 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Strategies for Cooperative Multi-Agent Reinforcement Learning
Dec 14, 2022



Adequate strategizing of agents behaviors is essential to solving cooperative MARL problems. One intuitively beneficial yet uncommon method in this domain is predicting agents future behaviors and planning accordingly. Leveraging this point, we propose a two-level hierarchical architecture that combines a novel information-theoretic objective with a trajectory prediction model to learn a strategy. To this end, we introduce a latent policy that learns two types of latent strategies: individual $z_A$, and relational $z_R$ using a modified Graph Attention Network module to extract interaction features. We encourage each agent to behave according to the strategy by conditioning its local $Q$ functions on $z_A$, and we further equip agents with a shared $Q$ function that conditions on $z_R$. Additionally, we introduce two regularizers to allow predicted trajectories to be accurate and rewarding. Empirical results on Google Research Football (GRF) and StarCraft (SC) II micromanagement tasks show that our method establishes a new state of the art being, to the best of our knowledge, the first MARL algorithm to solve all super hard SC II scenarios as well as the GRF full game with a win rate higher than $95\%$, thus outperforming all existing methods. Videos and brief overview of the methods and results are available at: https://sites.google.com/view/hier-strats-marl/home.
Influence-based Reinforcement Learning for Intrinsically-motivated Agents
Aug 28, 2021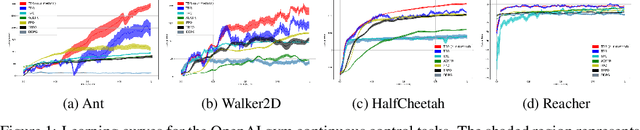
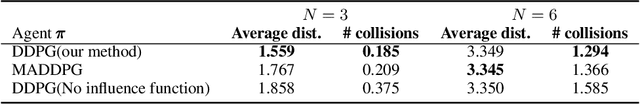
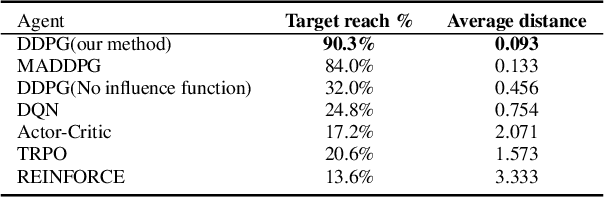
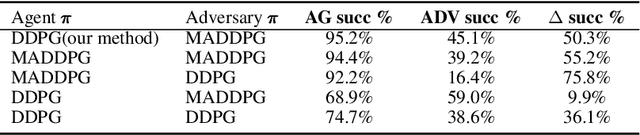
The reinforcement learning (RL) research area is very active, with several important applications. However, certain challenges still need to be addressed, amongst which one can mention the ability to find policies that achieve sufficient exploration and coordination while solving a given task. In this work, we present an algorithmic framework of two RL agents each with a different objective. We introduce a novel function approximation approach to assess the influence $F$ of a certain policy on others. While optimizing $F$ as a regularizer of $\pi$'s objective, agents learn to coordinate team behavior while exploiting high-reward regions of the solution space. Additionally, both agents use prediction error as intrinsic motivation to learn policies that behave as differently as possible, thus achieving the exploration criterion. Our method was evaluated on the suite of OpenAI gym tasks as well as cooperative and mixed scenarios, where agent populations are able to discover various physical and informational coordination strategies, showing state-of-the-art performance when compared to famous baselines.
Behavior-Guided Actor-Critic: Improving Exploration via Learning Policy Behavior Representation for Deep Reinforcement Learning
Apr 09, 2021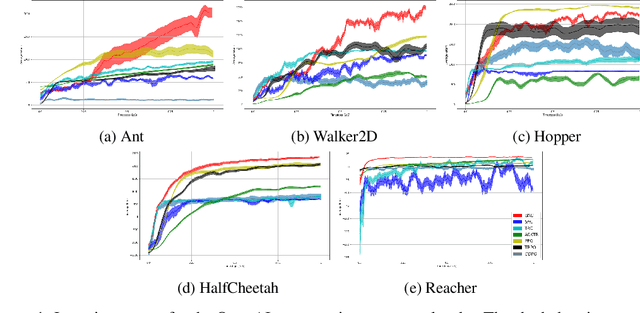
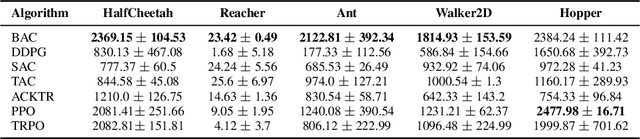
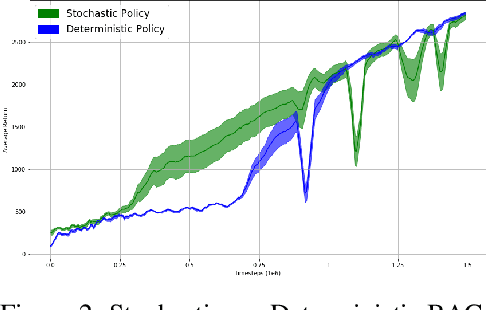

In this work, we propose Behavior-Guided Actor-Critic (BAC), an off-policy actor-critic deep RL algorithm. BAC mathematically formulates the behavior of the policy through autoencoders by providing an accurate estimation of how frequently each state-action pair was visited while taking into consideration state dynamics that play a crucial role in determining the trajectories produced by the policy. The agent is encouraged to change its behavior consistently towards less-visited state-action pairs while attaining good performance by maximizing the expected discounted sum of rewards, resulting in an efficient exploration of the environment and good exploitation of all high reward regions. One prominent aspect of our approach is that it is applicable to both stochastic and deterministic actors in contrast to maximum entropy deep reinforcement learning algorithms. Results show considerably better performances of BAC when compared to several cutting-edge learning algorithms.