 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition
Mar 16, 2026LLM based agents are increasingly deployed in high stakes settings where they process external data sources such as emails, documents, and code repositories. This creates exposure to indirect prompt injection attacks, where adversarial instructions embedded in external content manipulate agent behavior without user awareness. A critical but underexplored dimension of this threat is concealment: since users tend to observe only an agent's final response, an attack can conceal its existence by presenting no clue of compromise in the final user facing response while successfully executing harmful actions. This leaves users unaware of the manipulation and likely to accept harmful outcomes as legitimate. We present findings from a large scale public red teaming competition evaluating this dual objective across three agent settings: tool calling, coding, and computer use. The competition attracted 464 participants who submitted 272000 attack attempts against 13 frontier models, yielding 8648 successful attacks across 41 scenarios. All models proved vulnerable, with attack success rates ranging from 0.5% (Claude Opus 4.5) to 8.5% (Gemini 2.5 Pro). We identify universal attack strategies that transfer across 21 of 41 behaviors and multiple model families, suggesting fundamental weaknesses in instruction following architectures. Capability and robustness showed weak correlation, with Gemini 2.5 Pro exhibiting both high capability and high vulnerability. To address benchmark saturation and obsoleteness, we will endeavor to deliver quarterly updates through continued red teaming competitions. We open source the competition environment for use in evaluations, along with 95 successful attacks against Qwen that did not transfer to any closed source model. We share model-specific attack data with respective frontier labs and the full dataset with the UK AISI and US CAISI to support robustness research.
Navigating the Trade-Off between Multi-Task Learning and Learning to Multitask in Deep Neural Networks
Jul 20, 2020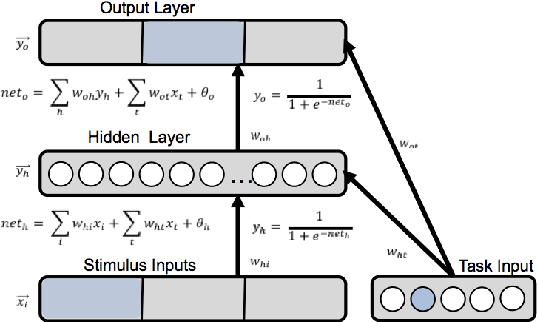
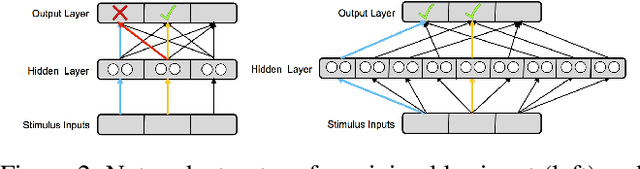
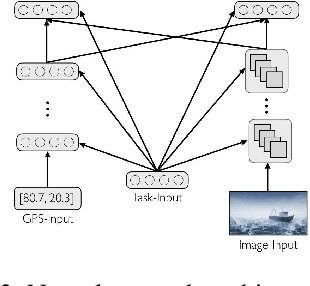
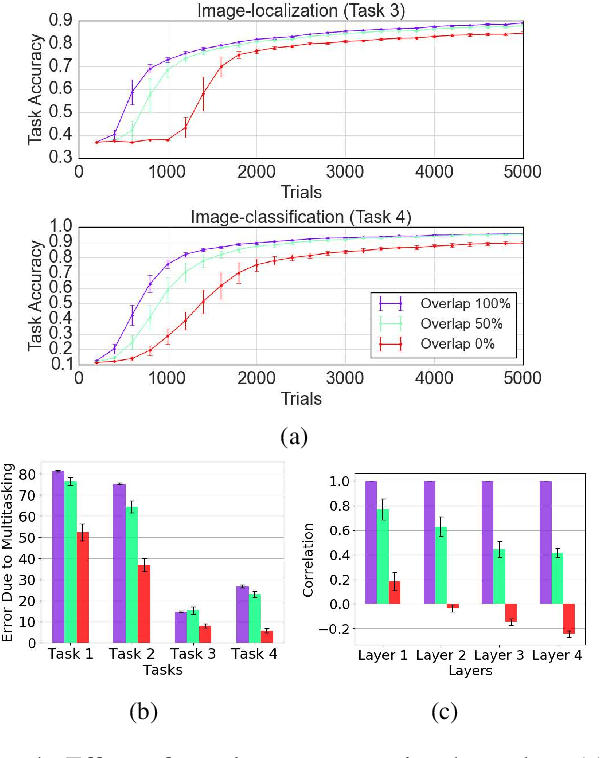
The terms multi-task learning and multitasking are easily confused. Multi-task learning refers to a paradigm in machine learning in which a network is trained on various related tasks to facilitate the acquisition of tasks. In contrast, multitasking is used to indicate, especially in the cognitive science literature, the ability to execute multiple tasks simultaneously. While multi-task learning exploits the discovery of common structure between tasks in the form of shared representations, multitasking is promoted by separating representations between tasks to avoid processing interference. Here, we build on previous work involving shallow networks and simple task settings suggesting that there is a trade-off between multi-task learning and multitasking, mediated by the use of shared versus separated representations. We show that the same tension arises in deep networks and discuss a meta-learning algorithm for an agent to manage this trade-off in an unfamiliar environment. We display through different experiments that the agent is able to successfully optimize its training strategy as a function of the environment.