 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHAMISA: SHAped Modeling of Implicit Structural Associations for Self-supervised No-Reference Image Quality Assessment
Mar 17, 2026No-Reference Image Quality Assessment (NR-IQA) aims to estimate perceptual quality without access to a reference image of pristine quality. Learning an NR-IQA model faces a fundamental bottleneck: its need for a large number of costly human perceptual labels. We propose SHAMISA, a non-contrastive self-supervised framework that learns from unlabeled distorted images by leveraging explicitly structured relational supervision. Unlike prior methods that impose rigid, binary similarity constraints, SHAMISA introduces implicit structural associations, defined as soft, controllable relations that are both distortion-aware and content-sensitive, inferred from synthetic metadata and intrinsic feature structure. A key innovation is our compositional distortion engine, which generates an uncountable family of degradations from continuous parameter spaces, grouped so that only one distortion factor varies at a time. This enables fine-grained control over representational similarity during training: images with shared distortion patterns are pulled together in the embedding space, while severity variations produce structured, predictable shifts. We integrate these insights via dual-source relation graphs that encode both known degradation profiles and emergent structural affinities to guide the learning process throughout training. A convolutional encoder is trained under this supervision and then frozen for inference, with quality prediction performed by a linear regressor on its features. Extensive experiments on synthetic, authentic, and cross-dataset NR-IQA benchmarks demonstrate that SHAMISA achieves strong overall performance with improved cross-dataset generalization and robustness, all without human quality annotations or contrastive losses.
Generated Contents Enrichment
May 06, 2024


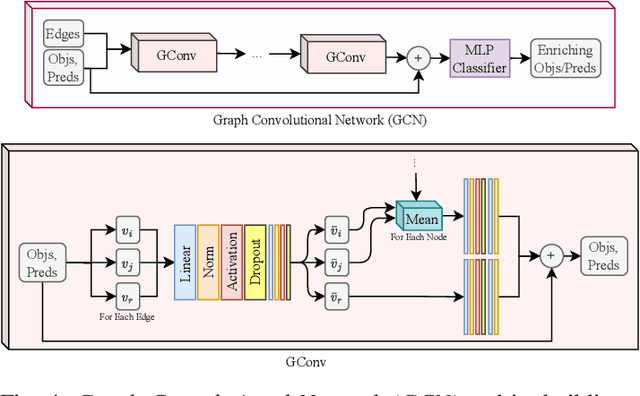
In this paper, we investigate a novel artificial intelligence generation task, termed as generated contents enrichment (GCE). Different from conventional artificial intelligence contents generation task that enriches the given textual description implicitly with limited semantics for generating visually real content, our proposed GCE strives to perform content enrichment explicitly on both the visual and textual domain, from which the enriched contents are visually real, structurally reasonable, and semantically abundant. Towards to solve GCE, we propose a deep end-to-end method that explicitly explores the semantics and inter-semantic relationships during the enrichment. Specifically, we first model the input description as a semantic graph, wherein each node represents an object and each edge corresponds to the inter-object relationship. We then adopt Graph Convolutional Networks on top of the input scene description to predict the enriching objects and their relationships with the input objects. Finally, the enriched graph is fed into an image synthesis model to carry out the visual contents generation. Our experiments conducted on the Visual Genome dataset exhibit promising and visually plausible results.
ExGRG: Explicitly-Generated Relation Graph for Self-Supervised Representation Learning
Feb 09, 2024



Self-supervised Learning (SSL) has emerged as a powerful technique in pre-training deep learning models without relying on expensive annotated labels, instead leveraging embedded signals in unlabeled data. While SSL has shown remarkable success in computer vision tasks through intuitive data augmentation, its application to graph-structured data poses challenges due to the semantic-altering and counter-intuitive nature of graph augmentations. Addressing this limitation, this paper introduces a novel non-contrastive SSL approach to Explicitly Generate a compositional Relation Graph (ExGRG) instead of relying solely on the conventional augmentation-based implicit relation graph. ExGRG offers a framework for incorporating prior domain knowledge and online extracted information into the SSL invariance objective, drawing inspiration from the Laplacian Eigenmap and Expectation-Maximization (EM). Employing an EM perspective on SSL, our E-step involves relation graph generation to identify candidates to guide the SSL invariance objective, and M-step updates the model parameters by integrating the derived relational information. Extensive experimentation on diverse node classification datasets demonstrates the superiority of our method over state-of-the-art techniques, affirming ExGRG as an effective adoption of SSL for graph representation learning.