 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Synoptic Review of High-Frequency Oscillations as a Biomarker in Neurodegenerative Disease
Aug 27, 2025High Frequency Oscillations (HFOs), rapid bursts of brain activity above 80 Hz, have emerged as a highly specific biomarker for epileptogenic tissue. Recent evidence suggests that HFOs are also present in Alzheimer's Disease (AD), reflecting underlying network hyperexcitability and offering a promising, noninvasive tool for early diagnosis and disease tracking. This synoptic review provides a comprehensive analysis of publicly available electroencephalography (EEG) datasets relevant to HFO research in neurodegenerative disorders. We conducted a bibliometric analysis of 1,222 articles, revealing a significant and growing research interest in HFOs, particularly within the last ten years. We then systematically profile and compare key public datasets, evaluating their participant cohorts, data acquisition parameters, and accessibility, with a specific focus on their technical suitability for HFO analysis. Our comparative synthesis highlights critical methodological heterogeneity across datasets, particularly in sampling frequency and recording paradigms, which poses challenges for cross-study validation, but also offers opportunities for robustness testing. By consolidating disparate information, clarifying nomenclature, and providing a detailed methodological framework, this review serves as a guide for researchers aiming to leverage public data to advance the role of HFOs as a cross-disease biomarker for AD and related conditions.
FedPrune: Towards Inclusive Federated Learning
Oct 27, 2021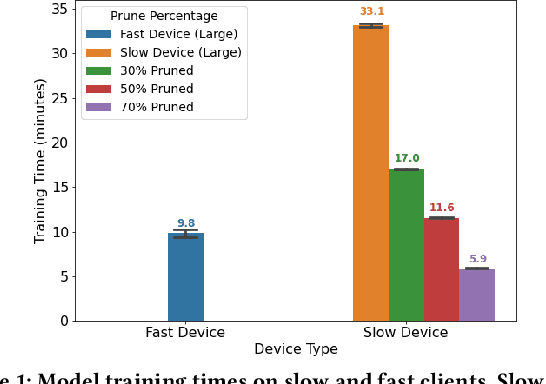
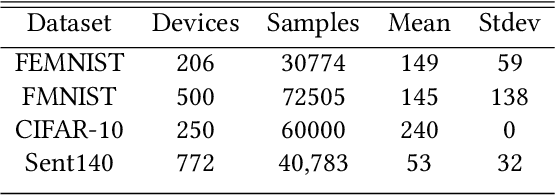
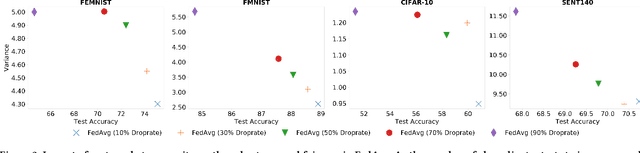
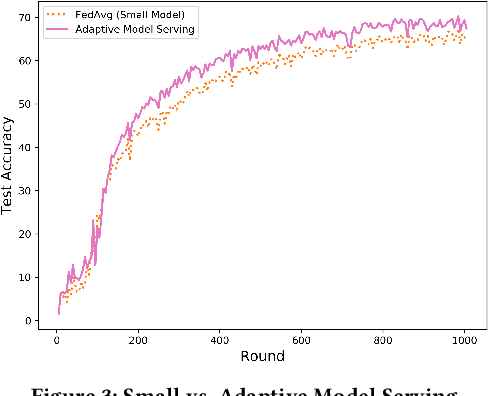
Federated learning (FL) is a distributed learning technique that trains a shared model over distributed data in a privacy-preserving manner. Unfortunately, FL's performance degrades when there is (i) variability in client characteristics in terms of computational and memory resources (system heterogeneity) and (ii) non-IID data distribution across clients (statistical heterogeneity). For example, slow clients get dropped in FL schemes, such as Federated Averaging (FedAvg), which not only limits overall learning but also biases results towards fast clients. We propose FedPrune; a system that tackles this challenge by pruning the global model for slow clients based on their device characteristics. By doing so, slow clients can train a small model quickly and participate in FL which increases test accuracy as well as fairness. By using insights from Central Limit Theorem, FedPrune incorporates a new aggregation technique that achieves robust performance over non-IID data. Experimental evaluation shows that Fed- Prune provides robust convergence and better fairness compared to Federated Averaging.