 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Multi-task Learning with Shared Variable Embeddings
May 10, 2024



This paper proposes a general interpretable predictive system with shared information. The system is able to perform predictions in a multi-task setting where distinct tasks are not bound to have the same input/output structure. Embeddings of input and output variables in a common space are obtained, where the input embeddings are produced through attending to a set of shared embeddings, reused across tasks. All the embeddings are treated as model parameters and learned. Specific restrictions on the space of shared embedings and the sparsity of the attention mechanism are considered. Experiments show that the introduction of shared embeddings does not deteriorate the results obtained from a vanilla variable embeddings method. We run a number of further ablations. Inducing sparsity in the attention mechanism leads to both an increase in accuracy and a significant decrease in the number of training steps required. Shared embeddings provide a measure of interpretability in terms of both a qualitative assessment and the ability to map specific shared embeddings to pre-defined concepts that are not tailored to the considered model. There seems to be a trade-off between accuracy and interpretability. The basic shared embeddings method favors interpretability, whereas the sparse attention method promotes accuracy. The results lead to the conclusion that variable embedding methods may be extended with shared information to provide increased interpretability and accuracy.
Text-to-Image Cross-Modal Generation: A Systematic Review
Jan 21, 2024We review research on generating visual data from text from the angle of "cross-modal generation." This point of view allows us to draw parallels between various methods geared towards working on input text and producing visual output, without limiting the analysis to narrow sub-areas. It also results in the identification of common templates in the field, which are then compared and contrasted both within pools of similar methods and across lines of research. We provide a breakdown of text-to-image generation into various flavors of image-from-text methods, video-from-text methods, image editing, self-supervised and graph-based approaches. In this discussion, we focus on research papers published at 8 leading machine learning conferences in the years 2016-2022, also incorporating a number of relevant papers not matching the outlined search criteria. The conducted review suggests a significant increase in the number of papers published in the area and highlights research gaps and potential lines of investigation. To our knowledge, this is the first review to systematically look at text-to-image generation from the perspective of "cross-modal generation."
Adversarial defenses via a mixture of generators
Oct 05, 2021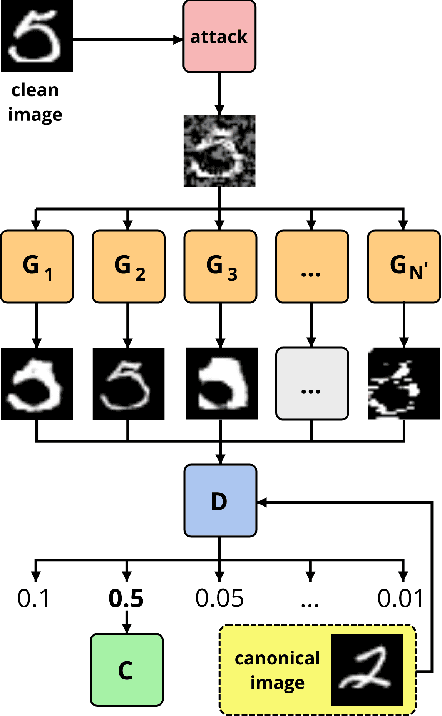


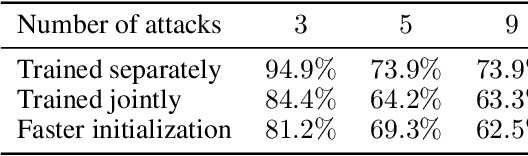
In spite of the enormous success of neural networks, adversarial examples remain a relatively weakly understood feature of deep learning systems. There is a considerable effort in both building more powerful adversarial attacks and designing methods to counter the effects of adversarial examples. We propose a method to transform the adversarial input data through a mixture of generators in order to recover the correct class obfuscated by the adversarial attack. A canonical set of images is used to generate adversarial examples through potentially multiple attacks. Such transformed images are processed by a set of generators, which are trained adversarially as a whole to compete in inverting the initial transformations. To our knowledge, this is the first use of a mixture-based adversarially trained system as a defense mechanism. We show that it is possible to train such a system without supervision, simultaneously on multiple adversarial attacks. Our system is able to recover class information for previously-unseen examples with neither attack nor data labels on the MNIST dataset. The results demonstrate that this multi-attack approach is competitive with adversarial defenses tested in single-attack settings.
Audio-to-Image Cross-Modal Generation
Sep 27, 2021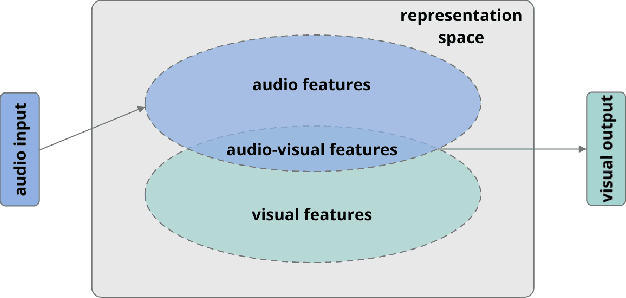

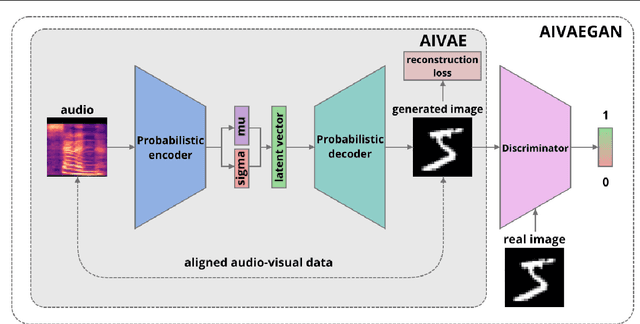

Cross-modal representation learning allows to integrate information from different modalities into one representation. At the same time, research on generative models tends to focus on the visual domain with less emphasis on other domains, such as audio or text, potentially missing the benefits of shared representations. Studies successfully linking more than one modality in the generative setting are rare. In this context, we verify the possibility to train variational autoencoders (VAEs) to reconstruct image archetypes from audio data. Specifically, we consider VAEs in an adversarial training framework in order to ensure more variability in the generated data and find that there is a trade-off between the consistency and diversity of the generated images - this trade-off can be governed by scaling the reconstruction loss up or down, respectively. Our results further suggest that even in the case when the generated images are relatively inconsistent (diverse), features that are critical for proper image classification are preserved.