 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Capabilities of Large Language Models. Lessons Learned from General Game Playing
Feb 22, 2026This paper examines the reasoning capabilities of Large Language Models (LLMs) from a novel perspective, focusing on their ability to operate within formally specified, rule-governed environments. We evaluate four LLMs (Gemini 2.5 Pro and Flash variants, Llama 3.3 70B and GPT-OSS 120B) on a suite of forward-simulation tasks-including next / multistep state formulation, and legal action generation-across a diverse set of reasoning problems illustrated through General Game Playing (GGP) game instances. Beyond reporting instance-level performance, we characterize games based on 40 structural features and analyze correlations between these features and LLM performance. Furthermore, we investigate the effects of various game obfuscations to assess the role of linguistic semantics in game definitions and the impact of potential prior exposure of LLMs to specific games during training. The main results indicate that three of the evaluated models generally perform well across most experimental settings, with performance degradation observed as the evaluation horizon increases (i.e., with a higher number of game steps). Detailed case-based analysis of the LLM performance provides novel insights into common reasoning errors in the considered logic-based problem formulation, including hallucinated rules, redundant state facts, or syntactic errors. Overall, the paper reports clear progress in formal reasoning capabilities of contemporary models.
The Many Challenges of Human-Like Agents in Virtual Game Environments
May 26, 2025Human-like agents are an increasingly important topic in games and beyond. Believable non-player characters enhance the gaming experience by improving immersion and providing entertainment. They also offer players the opportunity to engage with AI entities that can function as opponents, teachers, or cooperating partners. Additionally, in games where bots are prohibited -- and even more so in non-game environments -- there is a need for methods capable of identifying whether digital interactions occur with bots or humans. This leads to two fundamental research questions: (1) how to model and implement human-like AI, and (2) how to measure its degree of human likeness. This article offers two contributions. The first one is a survey of the most significant challenges in implementing human-like AI in games (or any virtual environment featuring simulated agents, although this article specifically focuses on games). Thirteen such challenges, both conceptual and technical, are discussed in detail. The second is an empirical study performed in a tactical video game that addresses the research question: "Is it possible to distinguish human players from bots (AI agents) based on empirical data?" A machine-learning approach using a custom deep recurrent convolutional neural network is presented. We hypothesize that the more challenging it is to create human-like AI for a given game, the easier it becomes to develop a method for distinguishing humans from AI-driven players.
Deep Learning and Artificial General Intelligence: Still a Long Way to Go
Apr 05, 2022

In recent years, deep learning using neural network architecture, i.e. deep neural networks, has been on the frontier of computer science research. It has even lead to superhuman performance in some problems, e.g., in computer vision, games and biology, and as a result the term deep learning revolution was coined. The undisputed success and rapid growth of deep learning suggests that, in future, it might become an enabler for Artificial General Intelligence (AGI). In this article, we approach this statement critically showing five major reasons of why deep neural networks, as of the current state, are not ready to be the technique of choice for reaching AGI.
A Crossover That Matches Diverse Parents Together in Evolutionary Algorithms
May 08, 2021

Crossover and mutation are the two main operators that lead to new solutions in evolutionary approaches. In this article, a new method of performing the crossover phase is presented. The problem of choice is evolutionary decision tree construction. The method aims at finding such individuals that together complement each other. Hence we say that they are diversely specialized. We propose the way of calculating the so-called complementary fitness. In several empirical experiments, we evaluate the efficacy of the method proposed in four variants and compare it to a fitness-rank-based approach. One variant emerges clearly as the best approach, whereas the remaining ones are below the baseline.
Monte Carlo Tree Search: A Review of Recent Modifications and Applications
Mar 09, 2021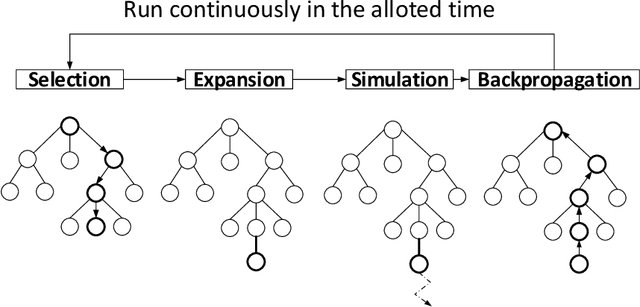
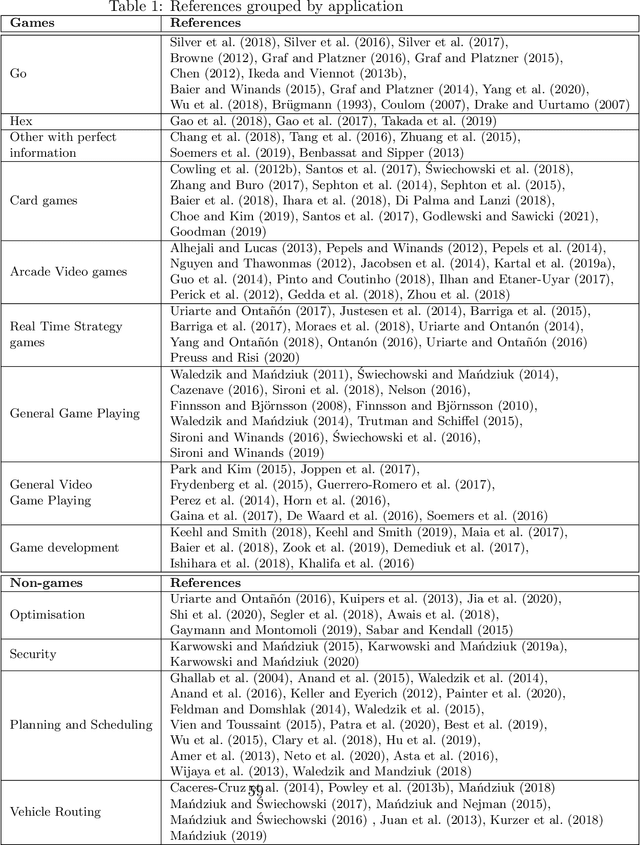
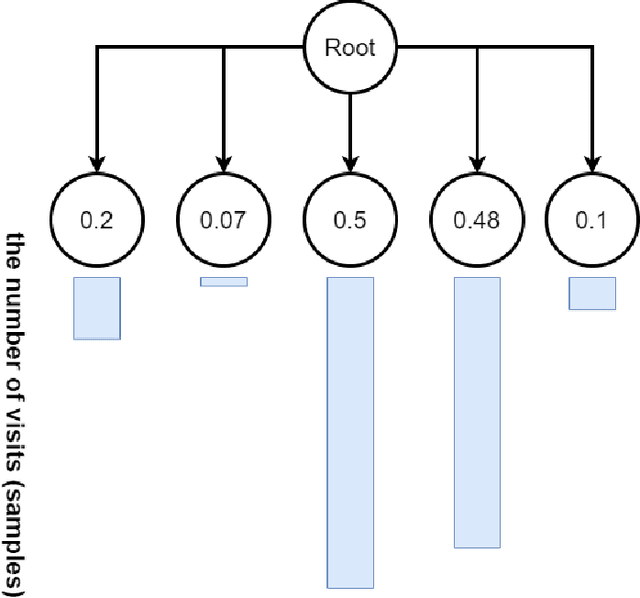
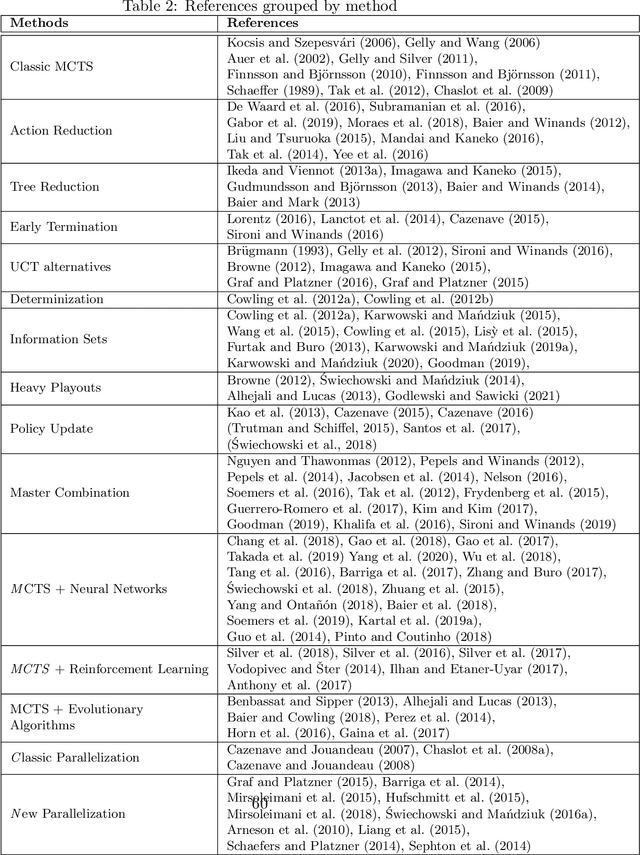
Monte Carlo Tree Search (MCTS) is a powerful approach to designing game-playing bots or solving sequential decision problems. The method relies on intelligent tree search that balances exploration and exploitation. MCTS performs random sampling in the form of simulations and stores statistics of actions to make more educated choices in each subsequent iteration. The method has become a state-of-the-art technique for combinatorial games, however, in more complex games (e.g. those with high branching factor or real-time ones), as well as in various practical domains (e.g. transportation, scheduling or security) an efficient MCTS application often requires its problem-dependent modification or integration with other techniques. Such domain-specific modifications and hybrid approaches are the main focus of this survey. The last major MCTS survey has been published in 2012. Contributions that appeared since its release are of particular interest for this review.
Improving Hearthstone AI by Combining MCTS and Supervised Learning Algorithms
Aug 14, 2018


We investigate the impact of supervised prediction models on the strength and efficiency of artificial agents that use the Monte-Carlo Tree Search (MCTS) algorithm to play a popular video game Hearthstone: Heroes of Warcraft. We overview our custom implementation of the MCTS that is well-suited for games with partially hidden information and random effects. We also describe experiments which we designed to quantify the performance of our Hearthstone agent's decision making. We show that even simple neural networks can be trained and successfully used for the evaluation of game states. Moreover, we demonstrate that by providing a guidance to the game state search heuristic, it is possible to substantially improve the win rate, and at the same time reduce the required computations.
Helping AI to Play Hearthstone: AAIA'17 Data Mining Challenge
Aug 02, 2017



This paper summarizes the AAIA'17 Data Mining Challenge: Helping AI to Play Hearthstone which was held between March 23, and May 15, 2017 at the Knowledge Pit platform. We briefly describe the scope and background of this competition in the context of a more general project related to the development of an AI engine for video games, called Grail. We also discuss the outcomes of this challenge and demonstrate how predictive models for the assessment of player's winning chances can be utilized in a construction of an intelligent agent for playing Hearthstone. Finally, we show a few selected machine learning approaches for modeling state and action values in Hearthstone. We provide evaluation for a few promising solutions that may be used to create more advanced types of agents, especially in conjunction with Monte Carlo Tree Search algorithms.