 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Embeddings for Similarity, Retrieval, and Interpretable Alignment of Numeric Tabular Datasets
May 28, 2026Numeric tabular datasets are the dominant data format in scientific practice, yet large language models lack native mechanisms for representing numeric datasets in a meaningful way across heterogeneous feature spaces. Existing approaches either target predictive modeling over individual datasets, which requires a shared set of variable definitions, or lack mechanisms for interpretable cross-dataset alignment. The proposed methodology characterizes numeric tabular datasets through structured exploratory data analysis descriptors, embeds those descriptors into a shared vector space using a pretrained sentence transformer, and quantifies cross-dataset similarity via Canonical Correlation Analysis (CCA). Furthermore, a penalized formulation of CCA is applied to recover sparse, interpretable variable-level correspondences between datasets, identifying which statistical descriptors or variable-level quantities drive cross-dataset alignment without requiring shared variable names or feature conventions. Differential privacy is optionally applied to the descriptor set prior to embedding, supporting deployment in sensitive data contexts without requiring access to raw observations at time of comparison. The methodology is evaluated across 15 datasets spanning general-purpose benchmarks, materials informatics, and nuclear-grade graphite characterization. Results demonstrate a total P@1 score of 0.9, with known nearest-neighbor retrieval and cluster structure remaining robust across embedding ablations and differential privacy budgets. The proposed framework provides a principled pathway for integrating heterogeneous numeric data into retrieval-augmented generation pipelines while preserving statistical context, with direct applications to data-driven algorithm selection and simulation model initialization for unknown datasets.
A Priori Calibration of Transient Kinetics Data via Machine Learning
Sep 27, 2021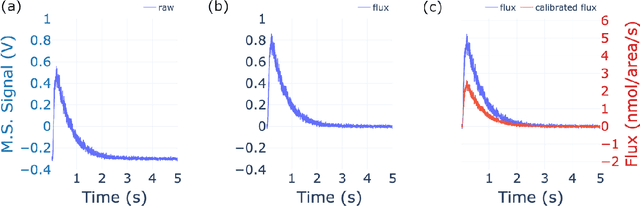
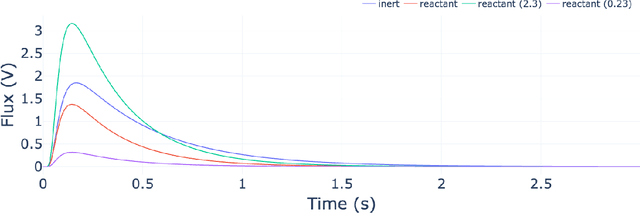
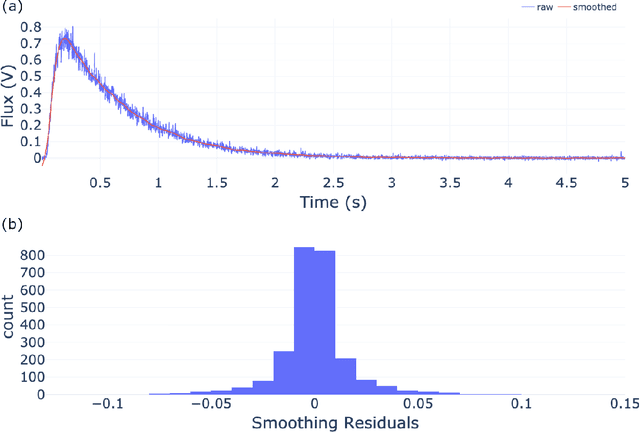
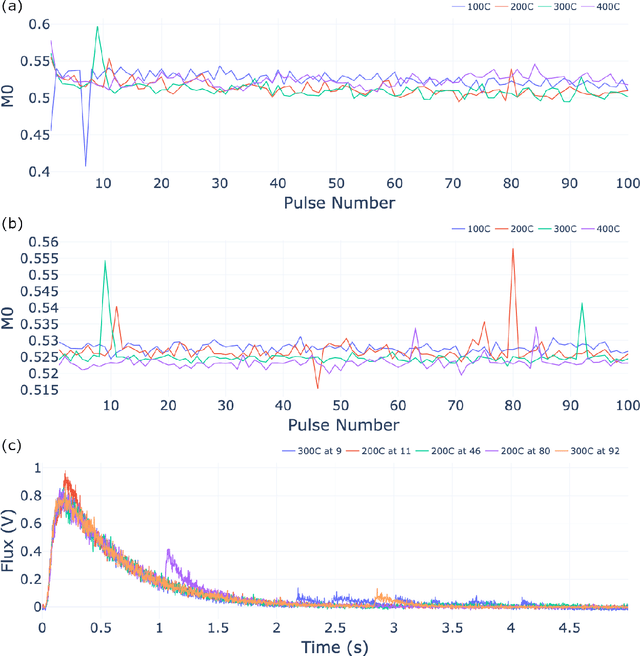
The temporal analysis of products reactor provides a vast amount of transient kinetic information that may be used to describe a variety of chemical features including the residence time distribution, kinetic coefficients, number of active sites, and the reaction mechanism. However, as with any measurement device, the TAP reactor signal is convoluted with noise. To reduce the uncertainty of the kinetic measurement and any derived parameters or mechanisms, proper preprocessing must be performed prior to any advanced analysis. This preprocessing consists of baseline correction, i.e., a shift in the voltage response, and calibration, i.e., a scaling of the flux response based on prior experiments. The current methodology of preprocessing requires significant user discretion and reliance on previous experiments that may drift over time. Herein we use machine learning techniques combined with physical constraints to convert the raw instrument signal to chemical information. As such, the proposed methodology demonstrates clear benefits over the traditional preprocessing in the calibration of the inert and feed mixture products without need of prior calibration experiments or heuristic input from the user.
Data Driven Reaction Mechanism Estimation via Transient Kinetics and Machine Learning
Nov 17, 2020
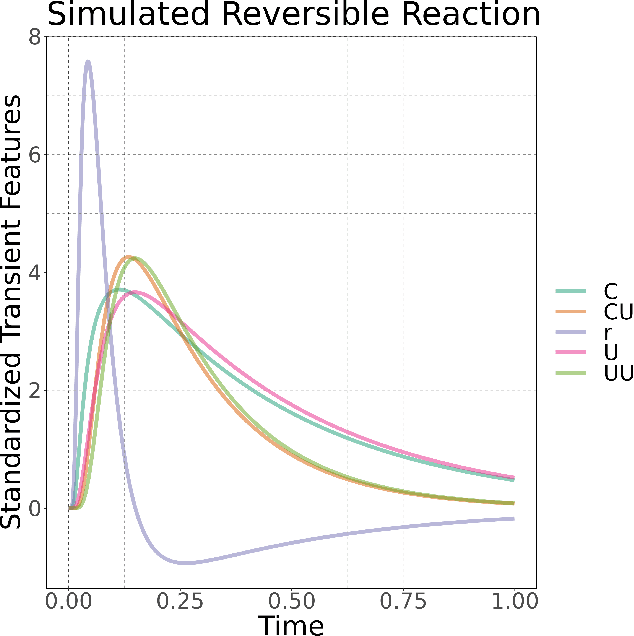

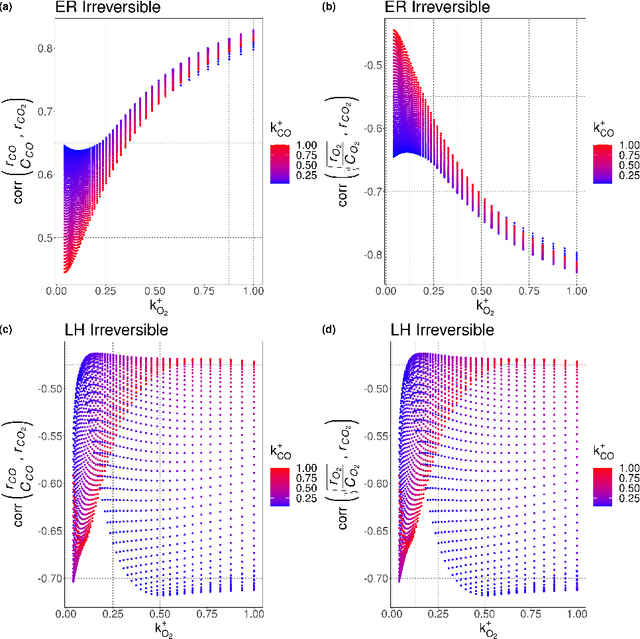
Understanding the set of elementary steps and kinetics in each reaction is extremely valuable to make informed decisions about creating the next generation of catalytic materials. With physical and mechanistic complexity of industrial catalysts, it is critical to obtain kinetic information through experimental methods. As such, this work details a methodology based on the combination of transient rate/concentration dependencies and machine learning to measure the number of active sites, the individual rate constants, and gain insight into the mechanism under a complex set of elementary steps. This new methodology was applied to simulated transient responses to verify its ability to obtain correct estimates of the micro-kinetic coefficients. Furthermore, experimental CO oxidation data was analyzed to reveal the Langmuir-Hinshelwood mechanism driving the reaction. As oxygen accumulated on the catalyst, a transition in the mechanism was clearly defined in the machine learning analysis due to the large amount of kinetic information available from transient reaction techniques. This methodology is proposed as a new data driven approach to characterize how materials control complex reaction mechanisms relying exclusively on experimental data.