 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Example-Based Approach to Japanese-to-English Translation of Tense, Aspect, and Modality
Dec 13, 1999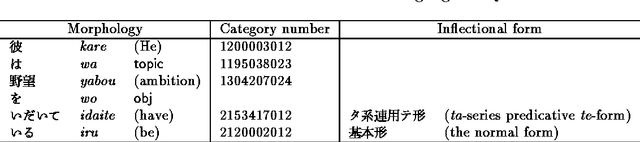
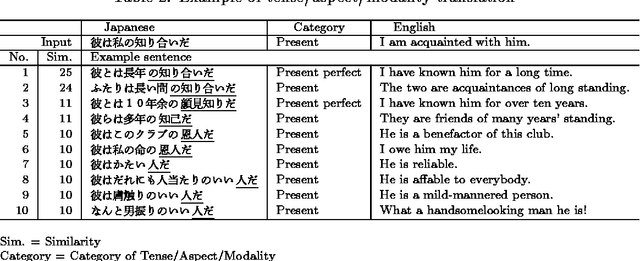

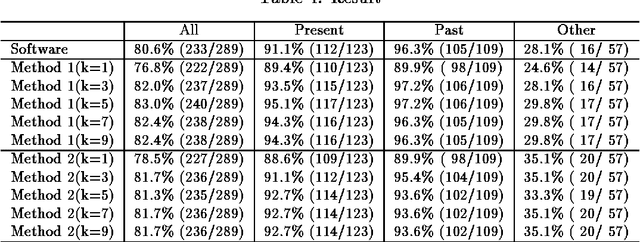
We have developed a new method for Japanese-to-English translation of tense, aspect, and modality that uses an example-based method. In this method the similarity between input and example sentences is defined as the degree of semantic matching between the expressions at the ends of the sentences. Our method also uses the k-nearest neighbor method in order to exclude the effects of noise; for example, wrongly tagged data in the bilingual corpora. Experiments show that our method can translate tenses, aspects, and modalities more accurately than the top-level MT software currently available on the market can. Moreover, it does not require hand-craft rules.
* 11 pages, 0 figures. Computation and Language
An Estimate of Referent of Noun Phrases in Japanese Sentences
Dec 13, 1999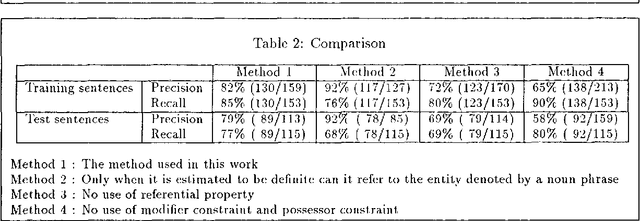
In machine translation and man-machine dialogue, it is important to clarify referents of noun phrases. We present a method for determining the referents of noun phrases in Japanese sentences by using the referential properties, modifiers, and possessors of noun phrases. Since the Japanese language has no articles, it is difficult to decide whether a noun phrase has an antecedent or not. We had previously estimated the referential properties of noun phrases that correspond to articles by using clue words in the sentences. By using these referential properties, our system determined the referents of noun phrases in Japanese sentences. Furthermore we used the modifiers and possessors of noun phrases in determining the referents of noun phrases. As a result, on training sentences we obtained a precision rate of 82% and a recall rate of 85% in the determination of the referents of noun phrases that have antecedents. On test sentences, we obtained a precision rate of 79% and a recall rate of 77%.
* 5 pages, 0 figures. Computation and Language
Resolution of Verb Ellipsis in Japanese Sentence using Surface Expressions and Examples
Dec 13, 1999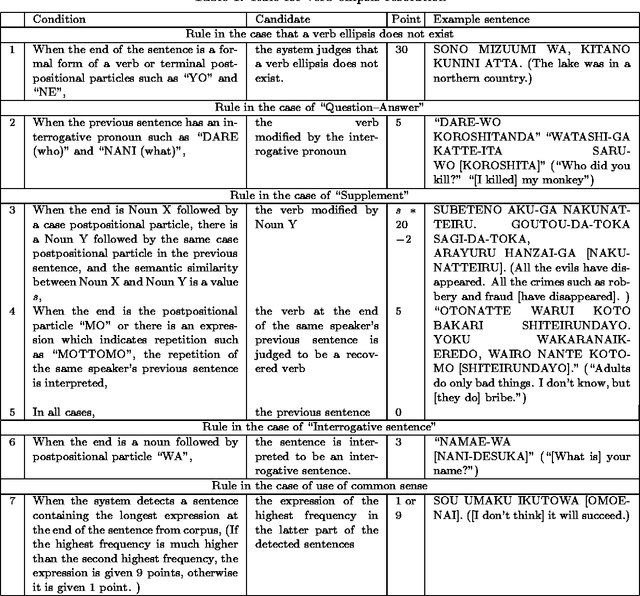
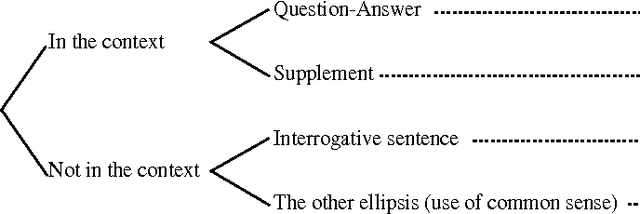
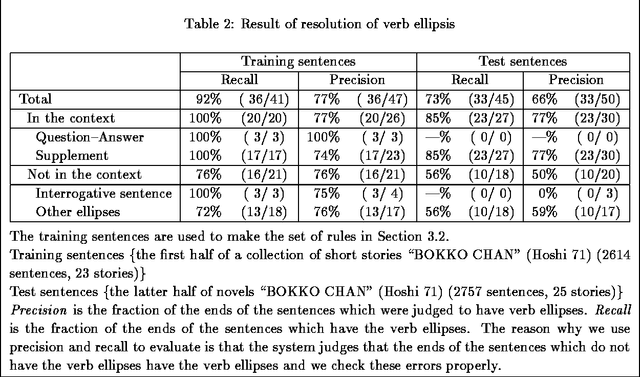

Verbs are sometimes omitted in Japanese sentences. It is necessary to recover omitted verbs for purposes of language understanding, machine translation, and conversational processing. This paper describes a practical way to recover omitted verbs by using surface expressions and examples. We experimented the resolution of verb ellipses by using this information, and obtained a recall rate of 73% and a precision rate of 66% on test sentences.
* 6 pages, 0 figures. Computation and Language
Pronoun Resolution in Japanese Sentences Using Surface Expressions and Examples
Dec 13, 1999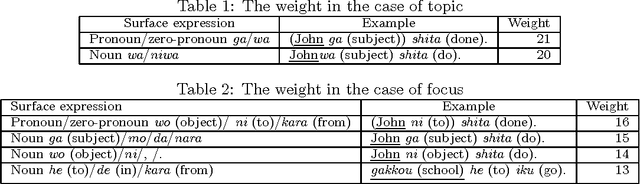

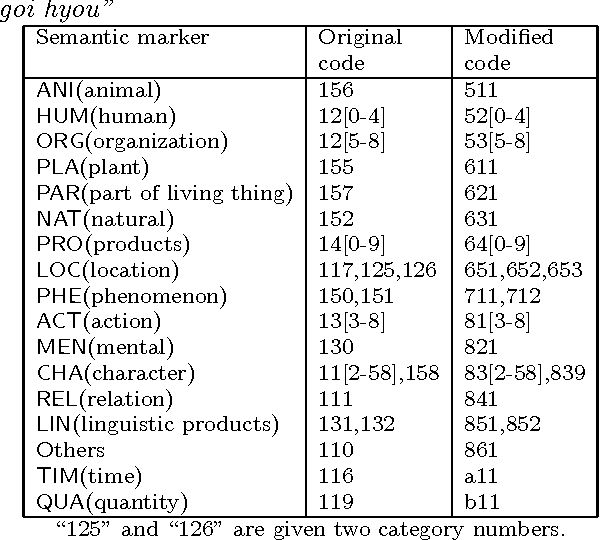
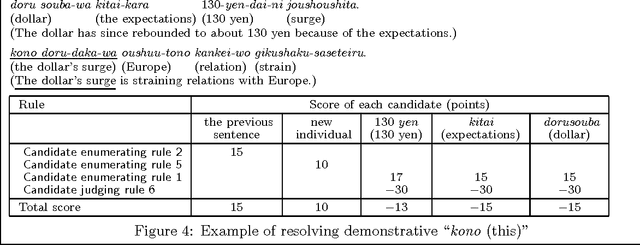
In this paper, we present a method of estimating referents of demonstrative pronouns, personal pronouns, and zero pronouns in Japanese sentences using examples, surface expressions, topics and foci. Unlike conventional work which was semantic markers for semantic constraints, we used examples for semantic constraints and showed in our experiments that examples are as useful as semantic markers. We also propose many new methods for estimating referents of pronouns. For example, we use the form ``X of Y'' for estimating referents of demonstrative adjectives. In addition to our new methods, we used many conventional methods. As a result, experiments using these methods obtained a precision rate of 87% in estimating referents of demonstrative pronouns, personal pronouns, and zero pronouns for training sentences, and obtained a precision rate of 78% for test sentences.
* 8 pages, 0 figures. Computation and Language
Resolution of Indirect Anaphora in Japanese Sentences Using Examples 'X no Y (Y of X)'
Dec 13, 1999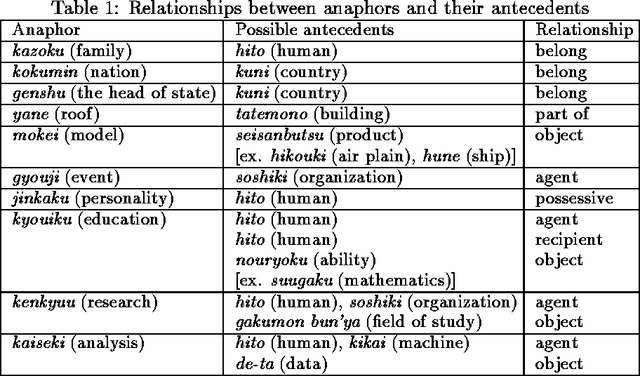
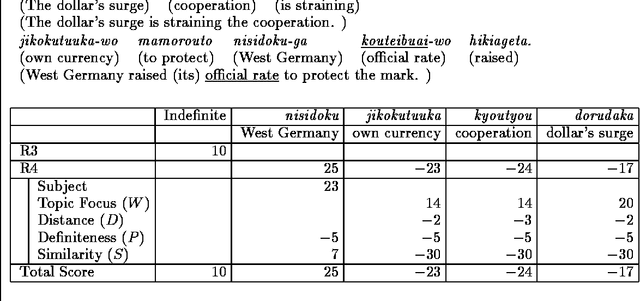


A noun phrase can indirectly refer to an entity that has already been mentioned. For example, ``I went into an old house last night. The roof was leaking badly and ...'' indicates that ``the roof'' is associated with `` an old house}'', which was mentioned in the previous sentence. This kind of reference (indirect anaphora) has not been studied well in natural language processing, but is important for coherence resolution, language understanding, and machine translation. In order to analyze indirect anaphora, we need a case frame dictionary for nouns that contains knowledge of the relationships between two nouns but no such dictionary presently exists. Therefore, we are forced to use examples of ``X no Y'' (Y of X) and a verb case frame dictionary instead. We tried estimating indirect anaphora using this information and obtained a recall rate of 63% and a precision rate of 68% on test sentences. This indicates that the information of ``X no Y'' is useful to a certain extent when we cannot make use of a noun case frame dictionary. We estimated the results that would be given by a noun case frame dictionary, and obtained recall and precision rates of 71% and 82% respectively. Finally, we proposed a way to construct a noun case frame dictionary by using examples of ``X no Y.''
* 8 pages, 0 figures. Computation and Language
Question Answering System Using Syntactic Information
Nov 15, 1999Question answering task is now being done in TREC8 using English documents. We examined question answering task in Japanese sentences. Our method selects the answer by matching the question sentence with knowledge-based data written in natural language. We use syntactic information to obtain highly accurate answers.