 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning based Selective Fixed-filter Active Noise Control System with ResNet Classifier
Apr 27, 2025



The selective fixed-filter strategy is popular in industrial applications involving active noise control (ANC) technology, which circumvents the time-consuming online learning process by selecting the best-matched pre-trained control filter. However, the existing selective fixed-filter ANC (SFANC) based algorithms classify noises in frequency band, which is not a reasonable approach. Moreover, they pre-train the control filter utilizing only a single noise segment, leading to inaccurate estimation and undesirable noise cancellation performance when dealing with dynamically time-varying noise. Inspired by the applicability of meta-learning to various models utilizing gradient descent technique, this paper proposes a novel meta-learning based SFANC system, wherein the fixed-filters that may not be optimal for specific types of noises but can rapidly adapt to previously unseen noise conditions are pre-trained. To address the mismatch issue between meta-learning update methods and ANC requirements while enhancing the receptive field and convergence speed of control filters, a multiple-input batch processing strategy is utilized in pre-training. Simulations based on the common ESC-50 noise dataset are performed and demonstrate the superiorities of the proposed method in terms of classification accuracy, convergence speed, and steady-state noise cancellation.
Quantitative perfusion and water transport time model from multi b-value diffusion magnetic resonance imaging validated against neutron capture microspheres
Apr 04, 2023Intravoxel Incoherent Motion (IVIM) is a non-contrast magnetic resonance imaging diffusion-based scan that uses a multitude of b-values to measure various speeds of molecular perfusion and diffusion, sidestepping inaccuracy of arterial input functions or bolus kinetics in quantitative imaging. We test a new method of IVIM quantification and compare our values to reference standard neutron capture microspheres across normocapnia, CO2 induced hypercapnia, and middle cerebral artery occlusion in a controlled animal model. Perfusion quantification in ml/100g/min compared to microsphere perfusion uses the 3D gaussian probability distribution and defined water transport time as when 50% of the molecules remain in the tissue of interest. Perfusion, water transport time, and infarct volume was compared to reference standards. Simulations were studied to suppress non-specific cerebrospinal fluid (CSF). Linear regression analysis of quantitative perfusion returned correlation (slope = .55, intercept = 52.5, $R^2$= .64). Linear regression for water transport time asymmetry in infarcted tissue was excellent (slope = .59, intercept = .3, $R^2$ = .93). Strong linear agreement also was found for infarct volume (slope = 1.01, $R^2$= .79). Simulation of CSF suppression via inversion recovery returned blood signal reduced by 82% from combined T1 and T2 effects. Intra-physiologic state comparison of perfusion shows potential partial volume effects which require further study especially in disease states. The accuracy and sensitivity of IVIM provides evidence that observed signal changes reflect cytotoxic edema and tissue perfusion. Partial volume contamination of CSF may be better removed during post-processing rather than with inversion recovery to avoid artificial loss of blood signal.
Invariance, encodings, and generalization: learning identity effects with neural networks
Jan 21, 2021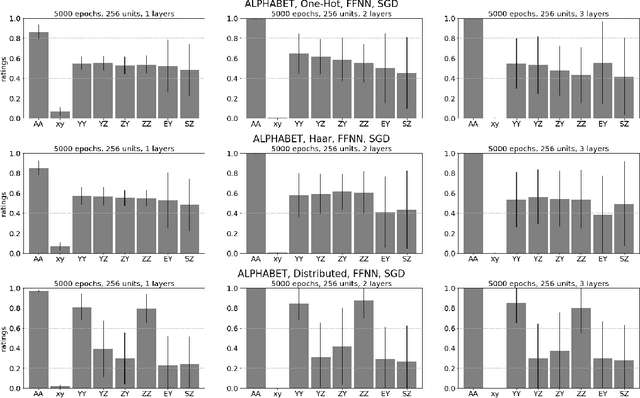
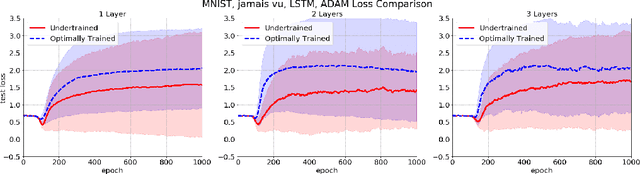
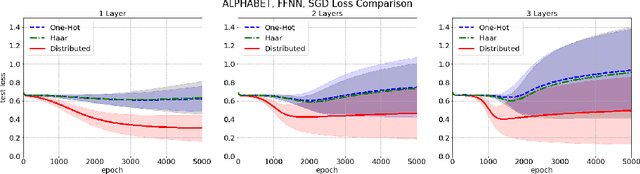
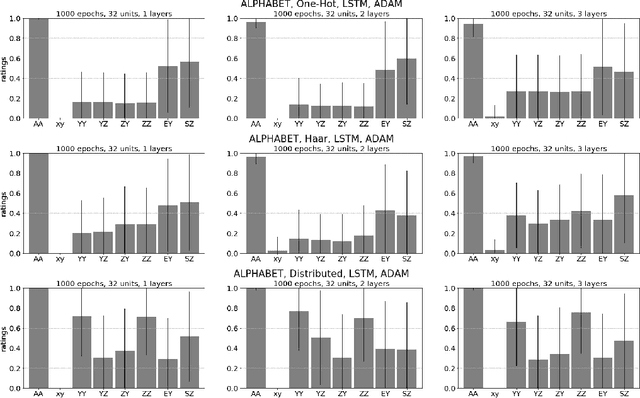
Often in language and other areas of cognition, whether two components of an object are identical or not determines if it is well formed. We call such constraints identity effects. When developing a system to learn well-formedness from examples, it is easy enough to build in an identify effect. But can identity effects be learned from the data without explicit guidance? We provide a framework in which we can rigorously prove that algorithms satisfying simple criteria cannot make the correct inference. We then show that a broad class of learning algorithms including deep feedforward neural networks trained via gradient-based algorithms (such as stochastic gradient descent or the Adam method) satisfy our criteria, dependent on the encoding of inputs. In some broader circumstances we are able to provide of adversarial examples that the network necessarily classifies incorrectly. Finally, we demonstrate our theory with computational experiments in which we explore the effect of different input encodings on the ability of algorithms to generalize to novel inputs.
Flow-based Algorithms for Improving Clusters: A Unifying Framework, Software, and Performance
Apr 22, 2020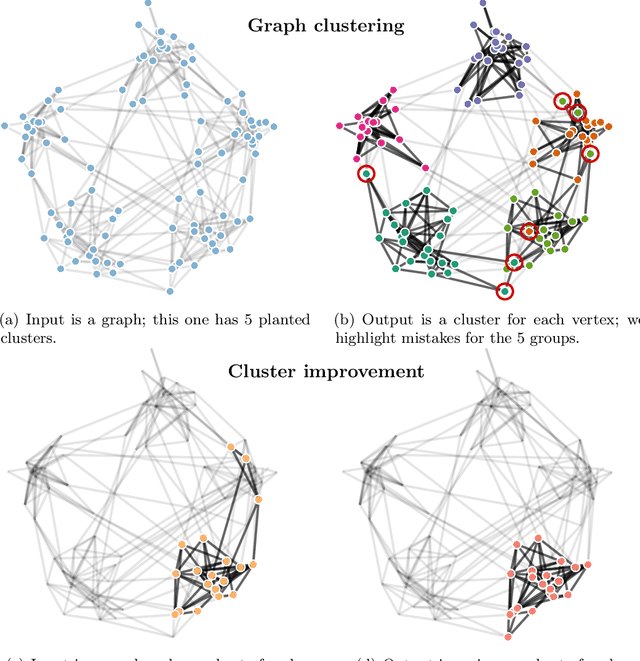

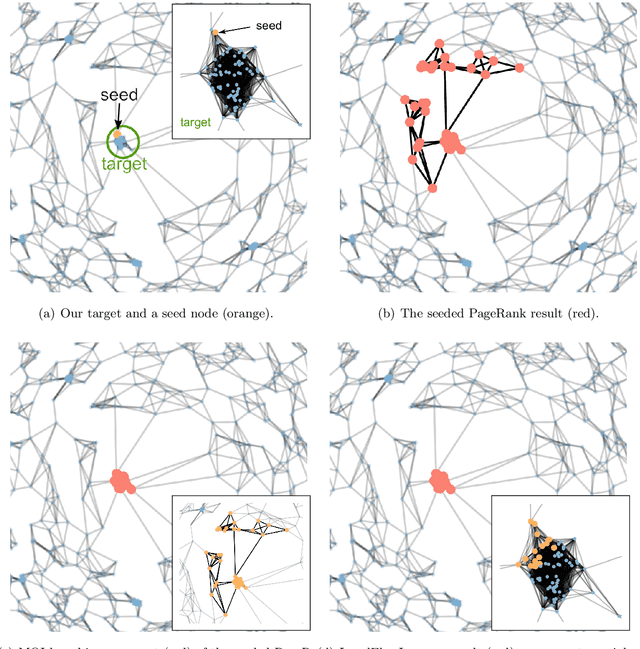

Clustering points in a vector space or nodes in a graph is a ubiquitous primitive in statistical data analysis, and it is commonly used for exploratory data analysis. In practice, it is often of interest to "refine" or "improve" a given cluster that has been obtained by some other method. In this survey, we focus on principled algorithms for this cluster improvement problem. Many such cluster improvement algorithms are flow-based methods, by which we mean that operationally they require the solution of a sequence of maximum flow problems on a (typically implicitly) modified data graph. These cluster improvement algorithms are powerful, both in theory and in practice, but they have not been widely adopted for problems such as community detection, local graph clustering, semi-supervised learning, etc. Possible reasons for this are: the steep learning curve for these algorithms; the lack of efficient and easy to use software; and the lack of detailed numerical experiments on real-world data that demonstrate their usefulness. Our objective here is to address these issues. To do so, we guide the reader through the whole process of understanding how to implement and apply these powerful algorithms. We present a unifying fractional programming optimization framework that permits us to distill out in a simple way the crucial components of all these algorithms. It also makes apparent similarities and differences between related methods. Viewing these cluster improvement algorithms via a fractional programming framework suggests directions for future algorithm development. Finally, we develop efficient implementations of these algorithms in our LocalGraphClustering python package, and we perform extensive numerical experiments to demonstrate the performance of these methods on social networks and image-based data graphs.
AI-optimized detector design for the future Electron-Ion Collider: the dual-radiator RICH case
Nov 13, 2019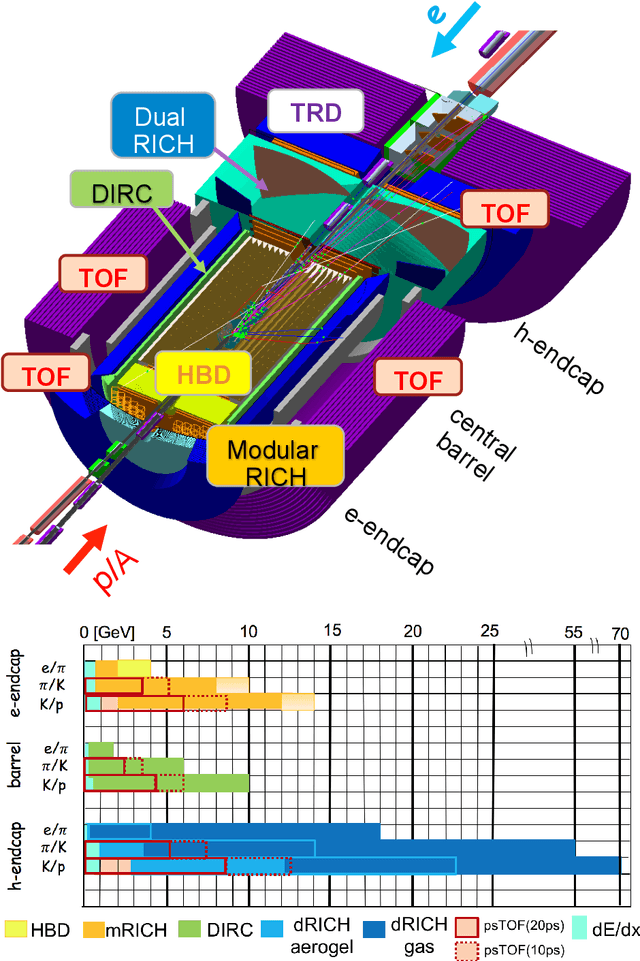
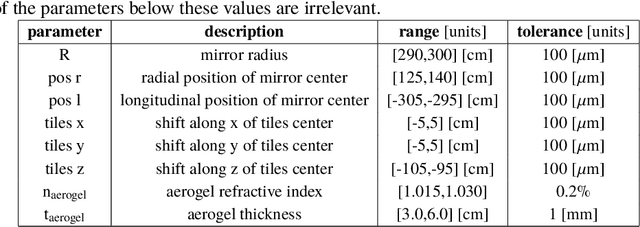
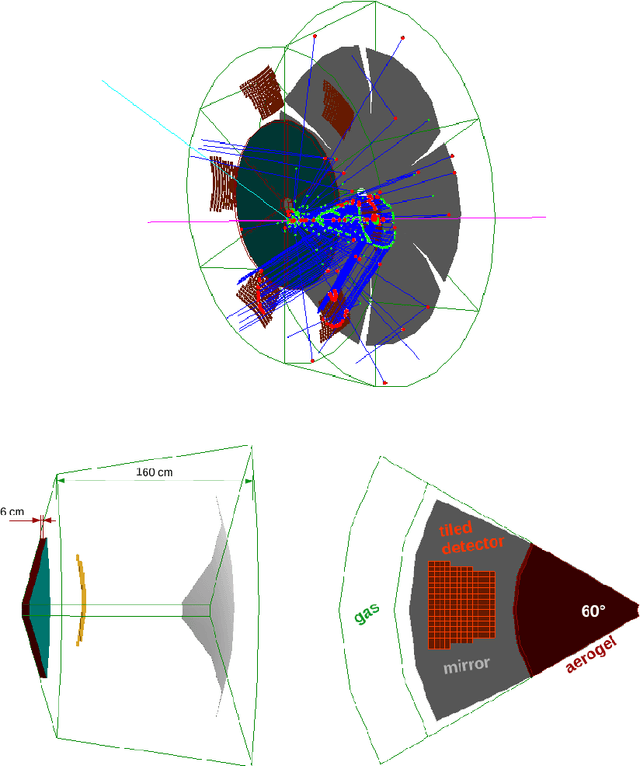
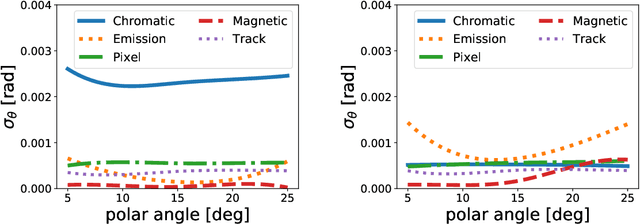
Advanced detector R&D requires performing computationally intensive and detailed simulations as part of the detector-design optimization process. We propose a general approach to this process based on Bayesian optimization and machine learning that encodes detector requirements. As a case study, we focus on the design of the dual-radiator Ring Imaging Cherenkov (dRICH) detector under development as part of the particle-identification system at the future Electron-Ion Collider (EIC). The EIC is a US-led frontier accelerator project for nuclear physics, which has been proposed to further explore the structure and interactions of nuclear matter at the scale of sea quarks and gluons. We show that the detector design obtained with our automated and highly parallelized framework outperforms the baseline dRICH design. Our approach can be applied to any detector R&D, provided that realistic simulations are available.