 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Random Neural Networks
Oct 29, 2024



The single-layer feedforward neural network with random weights is a recurring motif in the neural networks literature. The advantage of these networks is their simplified training, which reduces to solving a ridge-regression problem. However, a general assumption is that these networks require a large number of hidden neurons relative to the dimensionality of the data samples, in order to achieve good classification accuracy. Contrary to this assumption, here we show that one can obtain good classification results even if the number of hidden neurons has the same order of magnitude as the dimensionality of the data samples, if this dimensionality is reasonably high. We also develop an efficient iterative residual training method for such random neural networks, which significantly improves their classification accuracy. Moreover, we also describe an encryption (obfuscation) method which can be used to protect both the data and the neural network model.
Heuristic Optimal Transport in Branching Networks
Nov 11, 2023Optimal transport aims to learn a mapping of sources to targets by minimizing the cost, which is typically defined as a function of distance. The solution to this problem consists of straight line segments optimally connecting sources to targets, and it does not exhibit branching. These optimal solutions are in stark contrast with both natural, and man-made transportation networks, where branching structures are prevalent. Here we discuss a fast heuristic branching method for optimal transport in networks, and we provide several applications.
ELM Ridge Regression Boosting
Oct 24, 2023We discuss a boosting approach for the Ridge Regression (RR) method, with applications to the Extreme Learning Machine (ELM), and we show that the proposed method significantly improves the classification performance and robustness of ELMs.
TensorFlow Chaotic Prediction and Blow Up
Sep 14, 2023Predicting the dynamics of chaotic systems is one of the most challenging tasks for neural networks, and machine learning in general. Here we aim to predict the spatiotemporal chaotic dynamics of a high-dimensional non-linear system. In our attempt we use the TensorFlow library, representing the state of the art for deep neural networks training and prediction. While our results are encouraging, and show that the dynamics of the considered system can be predicted for short time, we also indirectly discovered an unexpected and undesirable behavior of the TensorFlow library. More specifically, the longer term prediction of the system's chaotic behavior quickly deteriorates and blows up due to the nondeterministic behavior of the TensorFlow library. Here we provide numerical evidence of the short time prediction ability, and of the longer term predictability blow up.
Autoencoders as Pattern Filters
Feb 26, 2023We discuss a simple approach to transform autoencoders into "pattern filters". Besides filtering, we show how this simple approach can be used also to build robust classifiers, by learning to filter only patterns of a given class.
Sandbox Sample Classification Using Behavioral Indicators of Compromise
Jan 18, 2022Behavioral Indicators of Compromise are associated with various automated methods used to extract the sample behavior by observing the system function calls performed in a virtual execution environment. Thus, every sample is described by a set of BICs triggered by the sample behavior in the sandbox environment. Here we discuss a Machine Learning approach to the classification of the sandbox samples as MALICIOUS or BENIGN, based on the list of triggered BICs. Besides the more traditional methods like Logistic Regression and Naive Bayes Classification we also discuss a different approach inspired by the statistical Monte Carlo methods. The numerical results are illustrated using ThreatGRID and ReversingLabs data.
Diffusion Self-Organizing Map on the Hypersphere
May 31, 2021

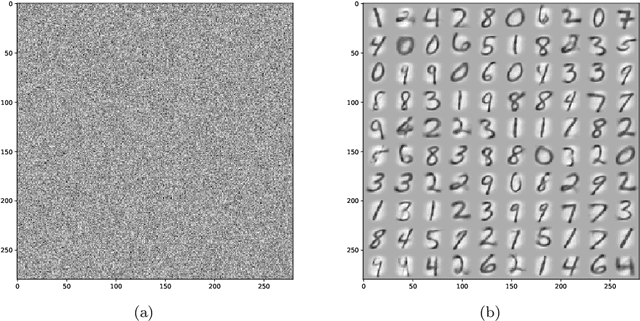

We discuss a diffusion based implementation of the self-organizing map on the unit hypersphere. We show that this approach can be efficiently implemented using just linear algebra methods, we give a python numpy implementation, and we illustrate the approach using the well known MNIST dataset.
Additive Feature Hashing
Feb 07, 2021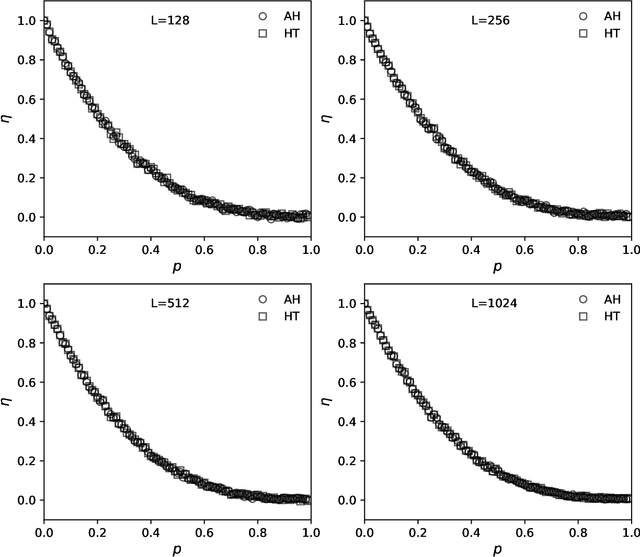
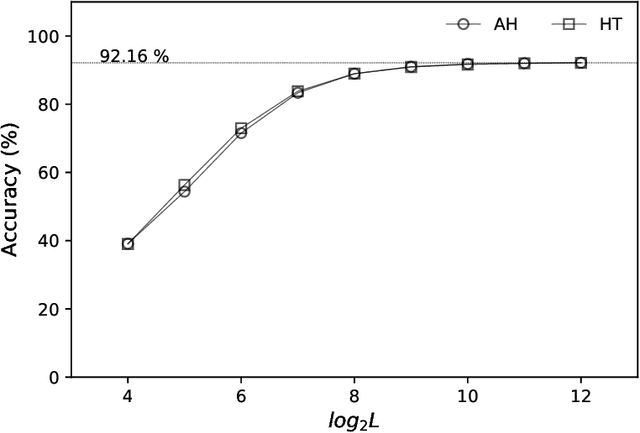

The hashing trick is a machine learning technique used to encode categorical features into a numerical vector representation of pre-defined fixed length. It works by using the categorical hash values as vector indices, and updating the vector values at those indices. Here we discuss a different approach based on additive-hashing and the "almost orthogonal" property of high-dimensional random vectors. That is, we show that additive feature hashing can be performed directly by adding the hash values and converting them into high-dimensional numerical vectors. We show that the performance of additive feature hashing is similar to the hashing trick, and we illustrate the results numerically using synthetic, language recognition, and SMS spam detection data.
K-Means Kernel Classifier
Dec 23, 2020

We combine K-means clustering with the least-squares kernel classification method. K-means clustering is used to extract a set of representative vectors for each class. The least-squares kernel method uses these representative vectors as a training set for the classification task. We show that this combination of unsupervised and supervised learning algorithms performs very well, and we illustrate this approach using the MNIST dataset
High-Dimensional Vector Semantics
Feb 23, 2018



In this paper we explore the "vector semantics" problem from the perspective of "almost orthogonal" property of high-dimensional random vectors. We show that this intriguing property can be used to "memorize" random vectors by simply adding them, and we provide an efficient probabilistic solution to the set membership problem. Also, we discuss several applications to word context vector embeddings, document sentences similarity, and spam filtering.