 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Portfolio Optimization Via Gradient Descent
Jul 22, 2025Traditional approaches to portfolio optimization, often rooted in Modern Portfolio Theory and solved via quadratic programming or evolutionary algorithms, struggle with scalability or flexibility, especially in scenarios involving complex constraints, large datasets and/or multiple conflicting objectives. To address these challenges, we introduce a benchmark framework for multi-objective portfolio optimization (MPO) using gradient descent with automatic differentiation. Our method supports any optimization objective, such as minimizing risk measures (e.g., CVaR) or maximizing Sharpe ratio, along with realistic constraints, such as tracking error limits, UCITS regulations, or asset group restrictions. We have evaluated our framework across six experimental scenarios, from single-objective setups to complex multi-objective cases, and have compared its performance against standard solvers like CVXPY and SKFOLIO. Our results show that our method achieves competitive performance while offering enhanced flexibility for modeling multiple objectives and constraints. We aim to provide a practical and extensible tool for researchers and practitioners exploring advanced portfolio optimization problems in real-world conditions.
The Importance of the Current Input in Sequence Modeling
Dec 22, 2021
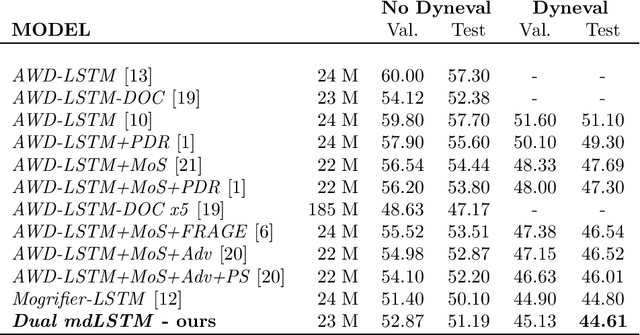


The last advances in sequence modeling are mainly based on deep learning approaches. The current state of the art involves the use of variations of the standard LSTM architecture, combined with several tricks that improve the final prediction rates of the trained neural networks. However, in some cases, these adaptations might be too much tuned to the particular problems being addressed. In this article, we show that a very simple idea, to add a direct connection between the input and the output, skipping the recurrent module, leads to an increase of the prediction accuracy in sequence modeling problems related to natural language processing. Experiments carried out on different problems show that the addition of this kind of connection to a recurrent network always improves the results, regardless of the architecture and training-specific details. When this idea is introduced into the models that lead the field, the resulting networks achieve a new state-of-the-art perplexity in language modeling problems.
Backward Gradient Normalization in Deep Neural Networks
Jun 17, 2021

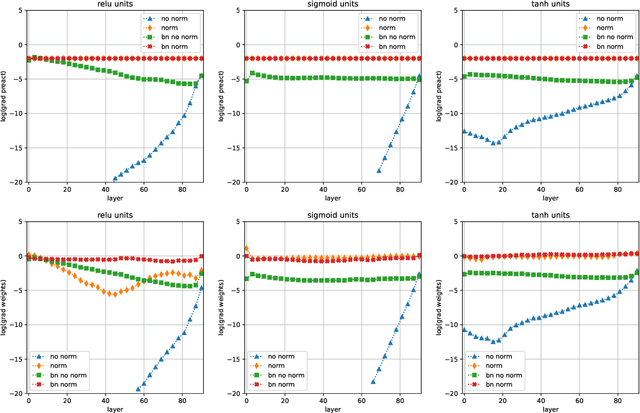

We introduce a new technique for gradient normalization during neural network training. The gradients are rescaled during the backward pass using normalization layers introduced at certain points within the network architecture. These normalization nodes do not affect forward activity propagation, but modify backpropagation equations to permit a well-scaled gradient flow that reaches the deepest network layers without experimenting vanishing or explosion. Results on tests with very deep neural networks show that the new technique can do an effective control of the gradient norm, allowing the update of weights in the deepest layers and improving network accuracy on several experimental conditions.
Stability of Internal States in Recurrent Neural Networks Trained on Regular Languages
Jun 18, 2020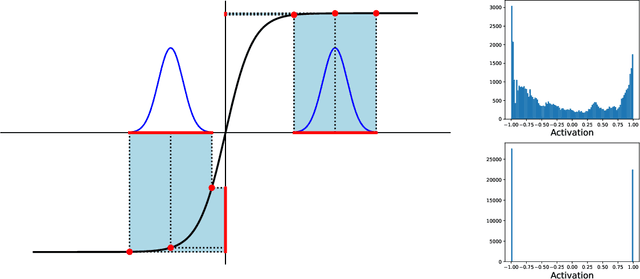


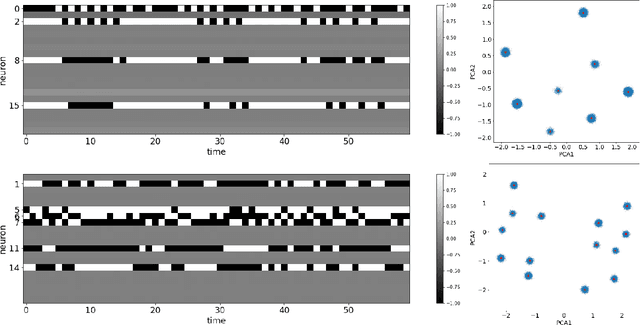
We provide an empirical study of the stability of recurrent neural networks trained to recognize regular languages. When a small amount of noise is introduced into the activation function, the neurons in the recurrent layer tend to saturate in order to compensate the variability. In this saturated regime, analysis of the network activation shows a set of clusters that resemble discrete states in a finite state machine. We show that transitions between these states in response to input symbols are deterministic and stable. The networks display a stable behavior for arbitrarily long strings, and when random perturbations are applied to any of the states, they are able to recover and their evolution converges to the original clusters. This observation reinforces the interpretation of the networks as finite automata, with neurons or groups of neurons coding specific and meaningful input patterns.
Separation of Memory and Processing in Dual Recurrent Neural Networks
May 17, 2020



We explore a neural network architecture that stacks a recurrent layer and a feedforward layer that is also connected to the input, and compare it to standard Elman and LSTM architectures in terms of accuracy and interpretability. When noise is introduced into the activation function of the recurrent units, these neurons are forced into a binary activation regime that makes the networks behave much as finite automata. The resulting models are simpler, easier to interpret and get higher accuracy on different sample problems, including the recognition of regular languages, the computation of additions in different bases and the generation of arithmetic expressions.