 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Generating and Attributing Answers using Logits of Document-Identifier Tokens
Aug 12, 2025Despite their impressive performances, Large Language Models (LLMs) remain prone to hallucination, which critically undermines their trustworthiness. While most of the previous work focused on tackling answer and attribution correctness, a recent line of work investigated faithfulness, with a focus on leveraging internal model signals to reflect a model's actual decision-making process while generating the answer. Nevertheless, these methods induce additional latency and have shown limitations in directly aligning token generation with attribution generation. In this paper, we introduce LoDIT, a method that jointly generates and faithfully attributes answers in RAG by leveraging specific token logits during generation. It consists of two steps: (1) marking the documents with specific token identifiers and then leveraging the logits of these tokens to estimate the contribution of each document to the answer during generation, and (2) aggregating these contributions into document attributions. Experiments on a trustworthiness-focused attributed text-generation benchmark, Trust-Align, show that LoDIT significantly outperforms state-of-the-art models on several metrics. Finally, an in-depth analysis of LoDIT shows both its efficiency in terms of latency and its robustness in different settings.
Few-Shot Emotion Recognition in Conversation with Sequential Prototypical Networks
Sep 20, 2021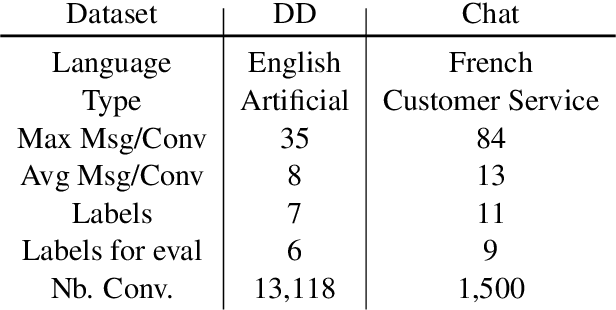
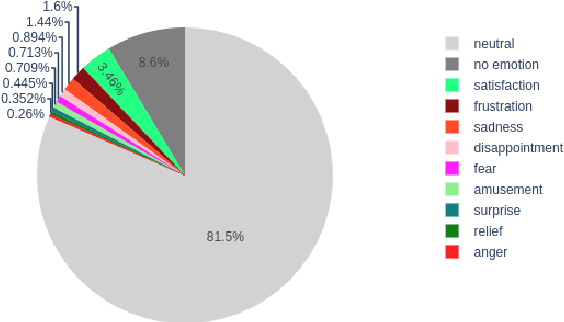
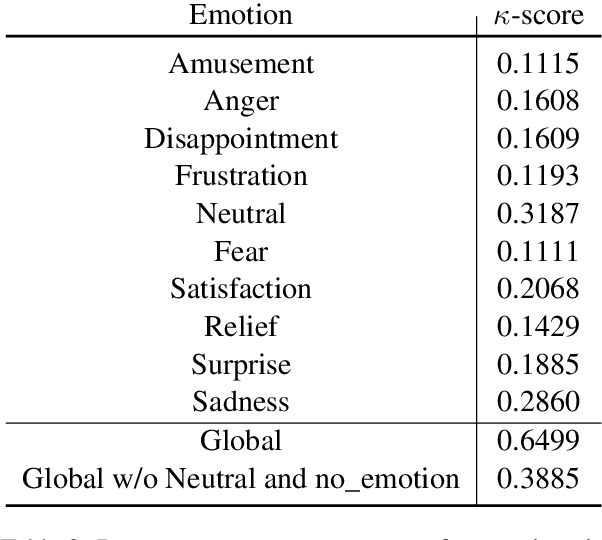
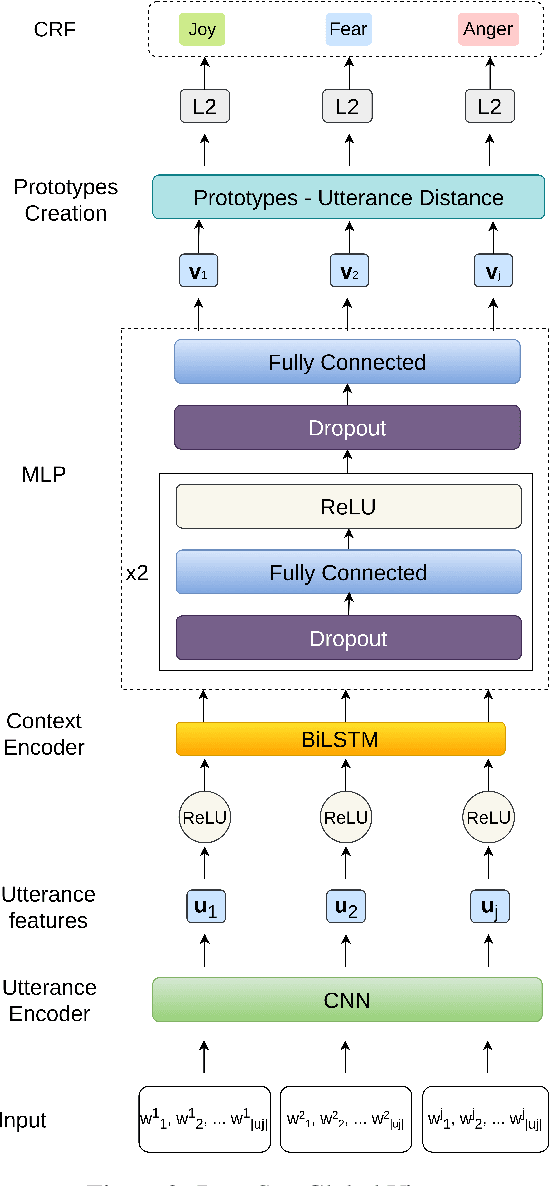
Several recent studies on dyadic human-human interactions have been done on conversations without specific business objectives. However, many companies might benefit from studies dedicated to more precise environments such as after sales services or customer satisfaction surveys. In this work, we place ourselves in the scope of a live chat customer service in which we want to detect emotions and their evolution in the conversation flow. This context leads to multiple challenges that range from exploiting restricted, small and mostly unlabeled datasets to finding and adapting methods for such context.We tackle these challenges by using Few-Shot Learning while making the hypothesis it can serve conversational emotion classification for different languages and sparse labels. We contribute by proposing a variation of Prototypical Networks for sequence labeling in conversation that we name ProtoSeq. We test this method on two datasets with different languages: daily conversations in English and customer service chat conversations in French. When applied to emotion classification in conversations, our method proved to be competitive even when compared to other ones.