 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuccioni
What's in the Box? An Analysis of Undesirable Content in the Common Crawl Corpus
May 06, 2021

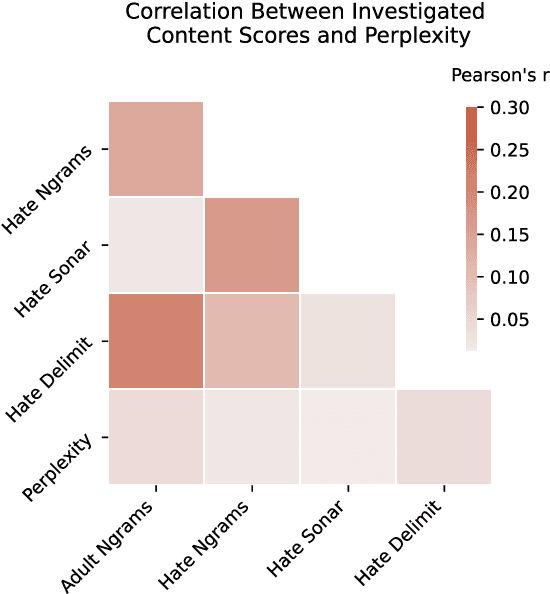

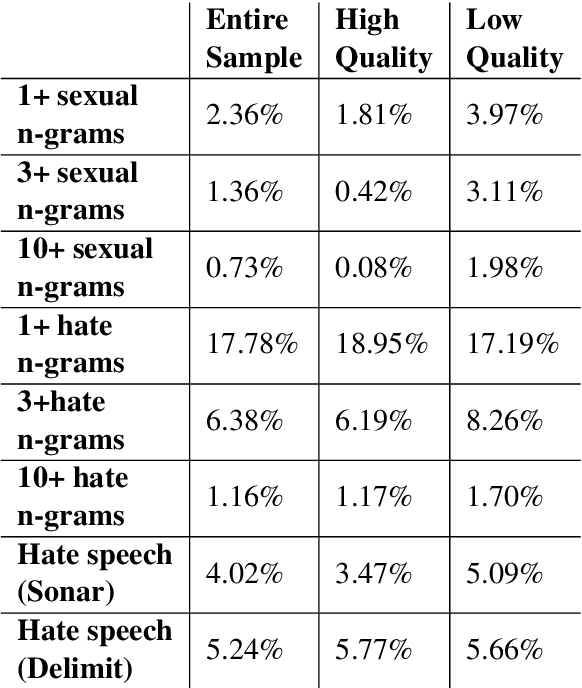
Whereas much of the success of the current generation of neural language models has been driven by increasingly large training corpora, relatively little research has been dedicated to analyzing these massive sources of textual data. In this exploratory analysis, we delve deeper into the Common Crawl, a colossal web corpus that is extensively used for training language models. We find that it contains a significant amount of undesirable content, including hate speech and sexually explicit content, even after filtering procedures. We conclude with a discussion of the potential impacts of this content on language models and call for more mindful approach to corpus collection and analysis.
Mapping the Landscape of Artificial Intelligence Applications against COVID-19
Mar 25, 2020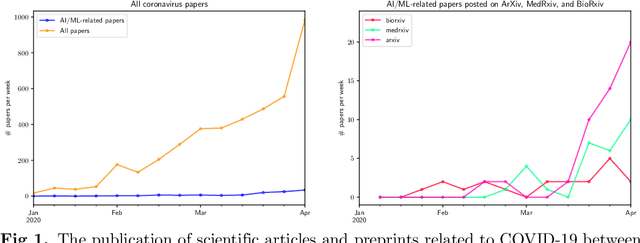
COVID-19, the disease caused by the SARS-CoV-2 virus, has been declared a pandemic by the World Health Organization, with over 294,000 cases as of March 22nd 2020. In this review, we present an overview of recent studies using Machine Learning and, more broadly, Artificial Intelligence, to tackle many aspects of the COVID-19 crisis at different scales including molecular, medical and epidemiological applications. We finish with a discussion of promising future directions of research and the tools and resources needed to facilitate AI research.