 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Topic Modeling for Determinants of Divergent Report Results Applied to Macular Degeneration Studies
Sep 01, 2023

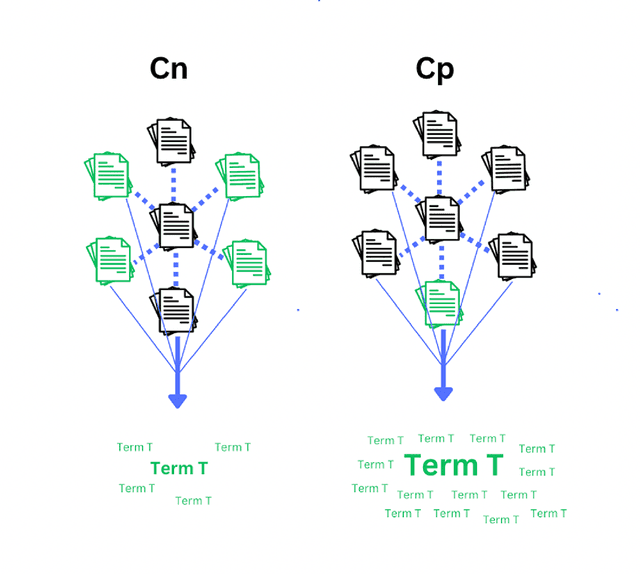
Topic modeling and text mining are subsets of Natural Language Processing with relevance for conducting meta-analysis (MA) and systematic review (SR). For evidence synthesis, the above NLP methods are conventionally used for topic-specific literature searches or extracting values from reports to automate essential phases of SR and MA. Instead, this work proposes a comparative topic modeling approach to analyze reports of contradictory results on the same general research question. Specifically, the objective is to find topics exhibiting distinct associations with significant results for an outcome of interest by ranking them according to their proportional occurrence and consistency of distribution across reports of significant results. The proposed method was tested on broad-scope studies addressing whether supplemental nutritional compounds significantly benefit macular degeneration (MD). Eight compounds were identified as having a particular association with reports of significant results for benefitting MD. Six of these were further supported in terms of effectiveness upon conducting a follow-up literature search for validation (omega-3 fatty acids, copper, zeaxanthin, lutein, zinc, and nitrates). The two not supported by the follow-up literature search (niacin and molybdenum) also had the lowest scores under the proposed methods ranking system, suggesting that the proposed method's score for a given topic is a viable proxy for its degree of association with the outcome of interest. These results underpin the proposed methods potential to add specificity in understanding effects from broad-scope reports, elucidate topics of interest for future research, and guide evidence synthesis in a systematic and scalable way.
Accuracy Improvement for Fully Convolutional Networks via Selective Augmentation with Applications to Electrocardiogram Data
Apr 25, 2021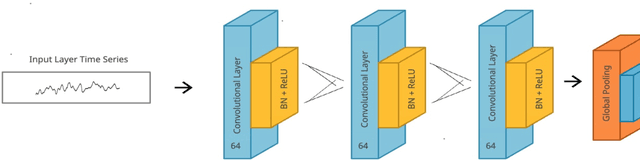

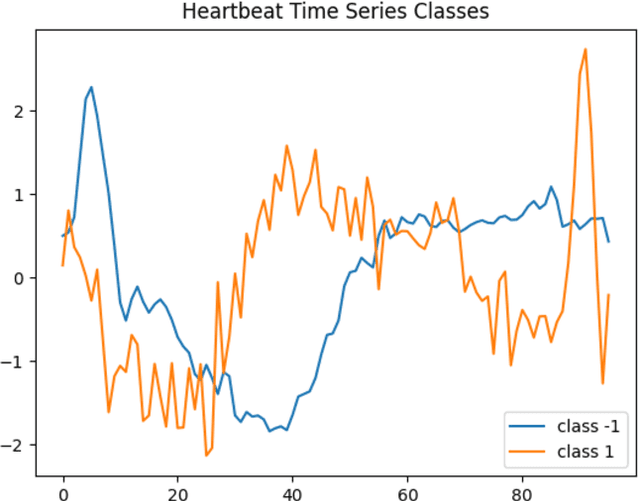
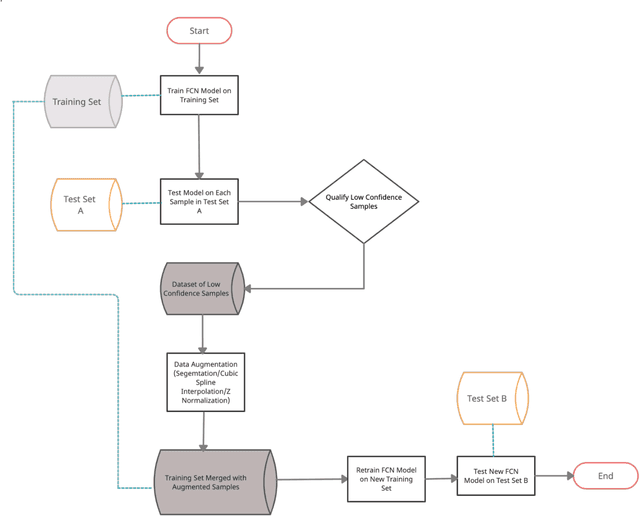
Deep learning methods have shown suitability for time series classification in the health and medical domain, with promising results for electrocardiogram data classification. Successful identification of myocardial infarction holds life saving potential and any meaningful improvement upon deep learning models in this area is of great interest. Conventionally, data augmentation methods are applied universally to the training set when data are limited in order to ameliorate data resolution or sample size. In the method proposed in this study, data augmentation was not applied in the context of data scarcity. Instead, samples that yield low confidence predictions were selectively augmented in order to bolster the model's sensitivity to features or patterns less strongly associated with a given class. This approach was tested for improving the performance of a Fully Convolutional Network. The proposed approach achieved 90 percent accuracy for classifying myocardial infarction as opposed to 82 percent accuracy for the baseline, a marked improvement. Further, the accuracy of the proposed approach was optimal near a defined upper threshold for qualifying low confidence samples and decreased as this threshold was raised to include higher confidence samples. This suggests exclusively selecting lower confidence samples for data augmentation comes with distinct benefits for electrocardiogram data classification with Fully Convolutional Networks.
Free congruence: an exploration of expanded similarity measures for time series data
Jan 17, 2021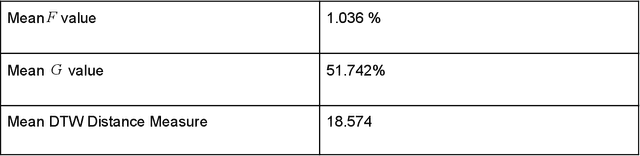
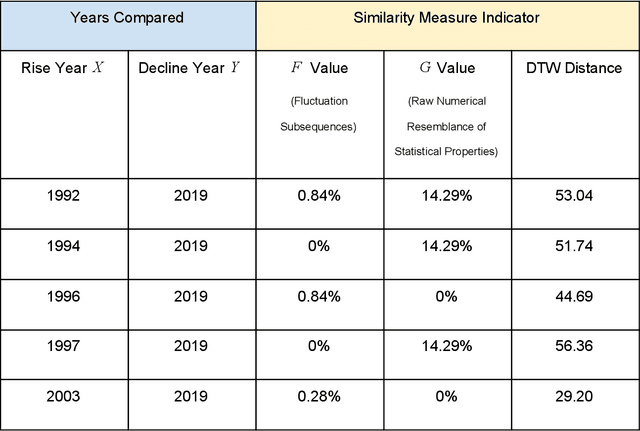
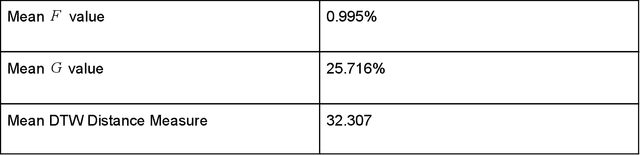
Time series similarity measures are highly relevant in a wide range of emerging applications including training machine learning models, classification, and predictive modeling. Standard similarity measures for time series most often involve point-to-point distance measures including Euclidean distance and Dynamic Time Warping. Such similarity measures fundamentally require the fluctuation of values in the time series being compared to follow a corresponding order or cadence for similarity to be established. This paper is spurred by the exploration of a broader definition of similarity, namely one that takes into account the sheer numerical resemblance between sets of statistical properties for time series segments irrespectively of value labeling. Further, the presence of common pattern components between time series segments was examined even if they occur in a permuted order, which would not necessarily satisfy the criteria of more conventional point-to-point distance measures. Results were compared with those of Dynamic Time Warping on the same data for context. Surprisingly, the test for the numerical resemblance between sets of statistical properties established a stronger resemblance for pairings of decline years with greater statistical significance than Dynamic Time Warping on the particular data and sample size used.