 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign choice and machine learning model performances
Jan 25, 2022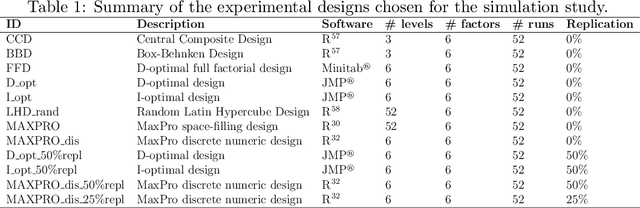
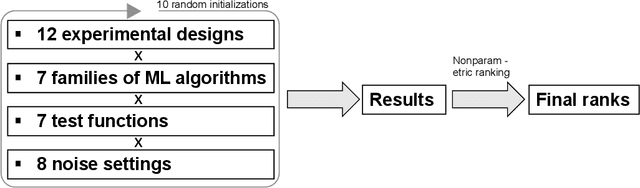

An increasing number of publications present the joint application of Design of Experiments (DOE) and machine learning (ML) as a methodology to collect and analyze data on a specific industrial phenomenon. However, the literature shows that the choice of the design for data collection and model for data analysis is often driven by incidental factors, rather than by statistical or algorithmic advantages, thus there is a lack of studies which provide guidelines on what designs and ML models to jointly use for data collection and analysis. This is the first time in the literature that a paper discusses the choice of design in relation to the ML model performances. An extensive study is conducted that considers 12 experimental designs, 7 families of predictive models, 7 test functions that emulate physical processes, and 8 noise settings, both homoscedastic and heteroscedastic. The results of the research can have an immediate impact on the work of practitioners, providing guidelines for practical applications of DOE and ML.
A Combined Approach To Detect Key Variables In Thick Data Analytics
Jun 01, 2020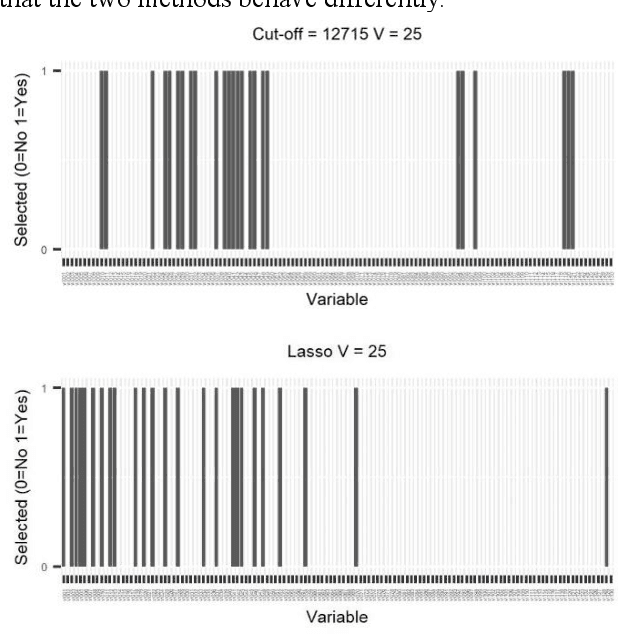
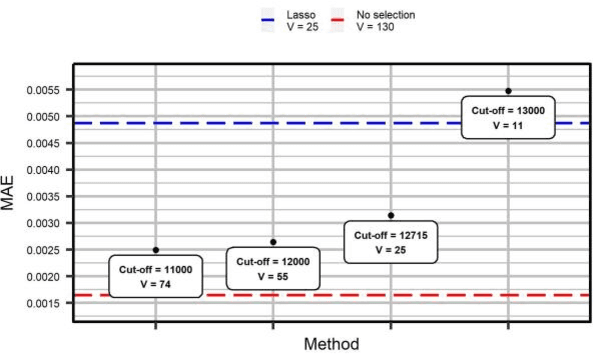
In machine learning one of the strategic tasks is the selection of only significant variables as predictors for the response(s). In this paper an approach is proposed which consists in the application of permutation tests on the candidate predictor variables in the aim of identifying only the most informative ones. Several industrial problems may benefit from such an approach, and an application in the field of chemical analysis is presented. A comparison is carried out between the approach proposed and Lasso, that is one of the most common alternatives for feature selection available in the literature.