 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior and Representation in Large Language Models for Combinatorial Optimization: From Feature Extraction to Algorithm Selection
Dec 15, 2025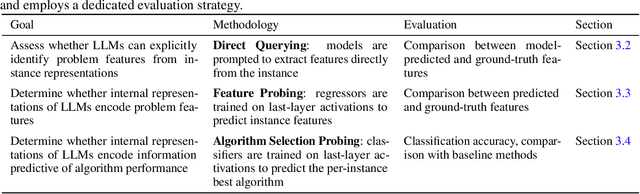
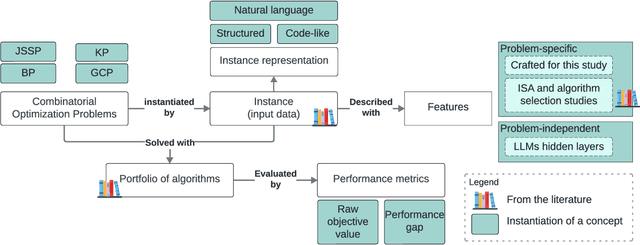

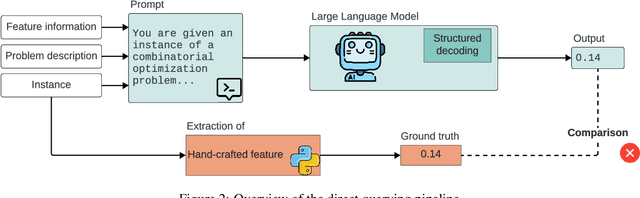
Recent advances in Large Language Models (LLMs) have opened new perspectives for automation in optimization. While several studies have explored how LLMs can generate or solve optimization models, far less is understood about what these models actually learn regarding problem structure or algorithmic behavior. This study investigates how LLMs internally represent combinatorial optimization problems and whether such representations can support downstream decision tasks. We adopt a twofold methodology combining direct querying, which assesses LLM capacity to explicitly extract instance features, with probing analyses that examine whether such information is implicitly encoded within their hidden layers. The probing framework is further extended to a per-instance algorithm selection task, evaluating whether LLM-derived representations can predict the best-performing solver. Experiments span four benchmark problems and three instance representations. Results show that LLMs exhibit moderate ability to recover feature information from problem instances, either through direct querying or probing. Notably, the predictive power of LLM hidden-layer representations proves comparable to that achieved through traditional feature extraction, suggesting that LLMs capture meaningful structural information relevant to optimization performance.
Educational Timetabling: Problems, Benchmarks, and State-of-the-Art Results
Jan 19, 2022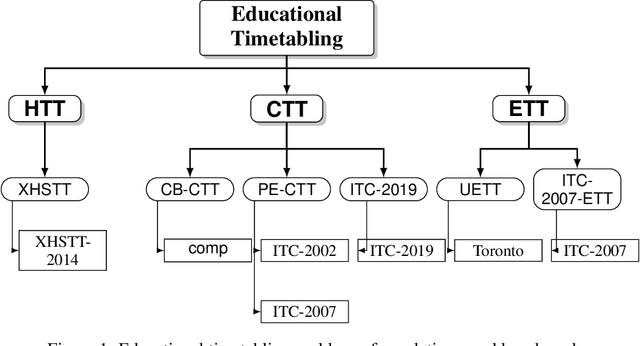
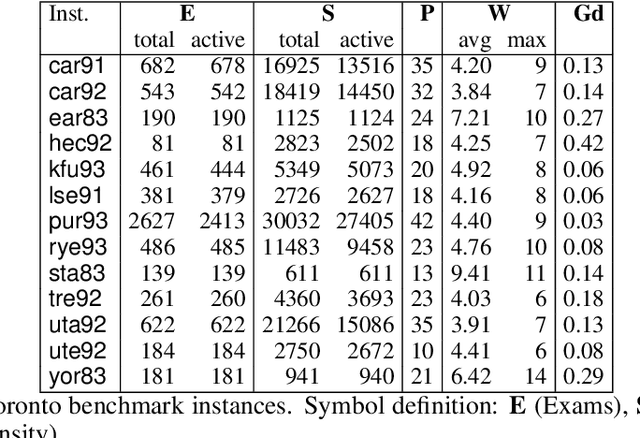
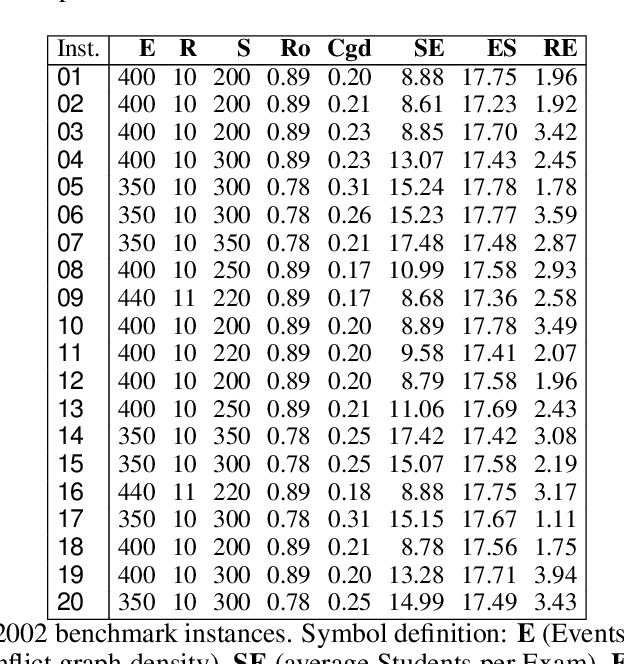

We propose a survey of the research contributions on the field of Educational Timetabling with a specific focus on "standard" formulations and the corresponding benchmark instances. We identify six of such formulations and we discuss their features, pointing out their relevance and usability. Other available formulations and datasets are also reviewed and briefly discussed. Subsequently, we report the main state-of-the-art results on the selected benchmarks, in terms of solution quality (upper and lower bounds), search techniques, running times, statistical distributions, and other side settings.
Feature-based tuning of simulated annealing applied to the curriculum-based course timetabling problem
Jul 08, 2015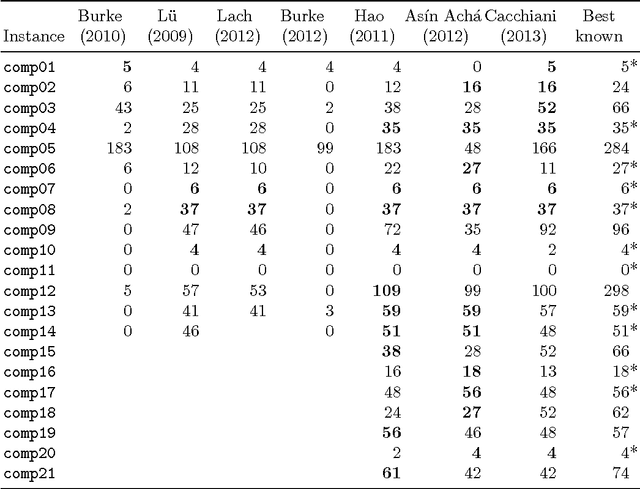
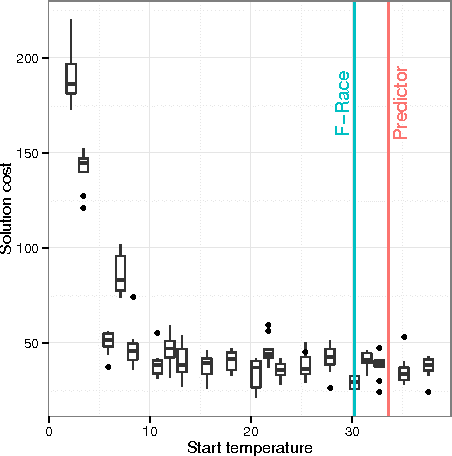

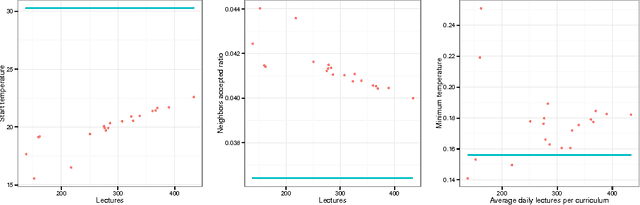
We consider the university course timetabling problem, which is one of the most studied problems in educational timetabling. In particular, we focus our attention on the formulation known as the curriculum-based course timetabling problem, which has been tackled by many researchers and for which there are many available benchmarks. The contribution of this paper is twofold. First, we propose an effective and robust single-stage simulated annealing method for solving the problem. Secondly, we design and apply an extensive and statistically-principled methodology for the parameter tuning procedure. The outcome of this analysis is a methodology for modeling the relationship between search method parameters and instance features that allows us to set the parameters for unseen instances on the basis of a simple inspection of the instance itself. Using this methodology, our algorithm, despite its apparent simplicity, has been able to achieve high quality results on a set of popular benchmarks. A final contribution of the paper is a novel set of real-world instances, which could be used as a benchmark for future comparison.
A preliminary analysis on metaheuristics methods applied to the Haplotype Inference Problem
Aug 03, 2007
Haplotype Inference is a challenging problem in bioinformatics that consists in inferring the basic genetic constitution of diploid organisms on the basis of their genotype. This information allows researchers to perform association studies for the genetic variants involved in diseases and the individual responses to therapeutic agents. A notable approach to the problem is to encode it as a combinatorial problem (under certain hypotheses, such as the pure parsimony criterion) and to solve it using off-the-shelf combinatorial optimization techniques. The main methods applied to Haplotype Inference are either simple greedy heuristic or exact methods (Integer Linear Programming, Semidefinite Programming, SAT encoding) that, at present, are adequate only for moderate size instances. We believe that metaheuristic and hybrid approaches could provide a better scalability. Moreover, metaheuristics can be very easily combined with problem specific heuristics and they can also be integrated with tree-based search techniques, thus providing a promising framework for hybrid systems in which a good trade-off between effectiveness and efficiency can be reached. In this paper we illustrate a feasibility study of the approach and discuss some relevant design issues, such as modeling and design of approximate solvers that combine constructive heuristics, local search-based improvement strategies and learning mechanisms. Besides the relevance of the Haplotype Inference problem itself, this preliminary analysis is also an interesting case study because the formulation of the problem poses some challenges in modeling and hybrid metaheuristic solver design that can be generalized to other problems.