 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazy But Effective: Collaborative Personalized Federated Learning with Heterogeneous Data
May 05, 2025In Federated Learning, heterogeneity in client data distributions often means that a single global model does not have the best performance for individual clients. Consider for example training a next-word prediction model for keyboards: user-specific language patterns due to demographics (dialect, age, etc.), language proficiency, and writing style result in a highly non-IID dataset across clients. Other examples are medical images taken with different machines, or driving data from different vehicle types. To address this, we propose a simple yet effective personalized federated learning framework (pFedLIA) that utilizes a computationally efficient influence approximation, called `Lazy Influence', to cluster clients in a distributed manner before model aggregation. Within each cluster, data owners collaborate to jointly train a model that captures the specific data patterns of the clients. Our method has been shown to successfully recover the global model's performance drop due to the non-IID-ness in various synthetic and real-world settings, specifically a next-word prediction task on the Nordic languages as well as several benchmark tasks. It matches the performance of a hypothetical Oracle clustering, and significantly improves on existing baselines, e.g., an improvement of 17% on CIFAR100.
Privacy-preserving Data Filtering in Federated Learning Using Influence Approximation
May 23, 2022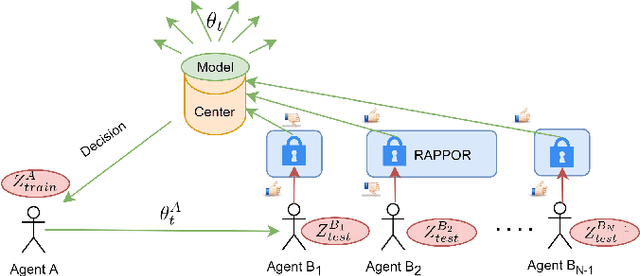
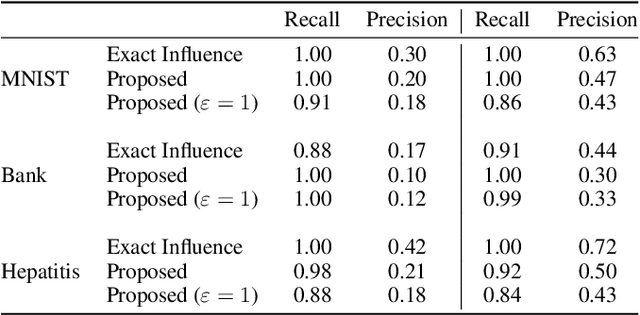
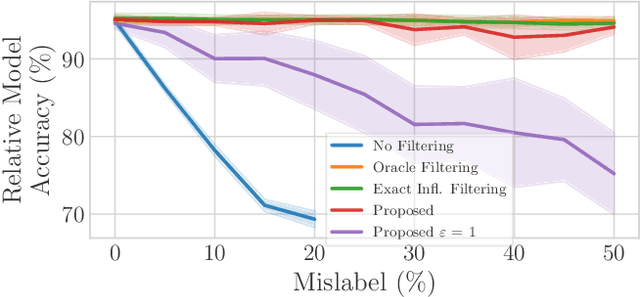
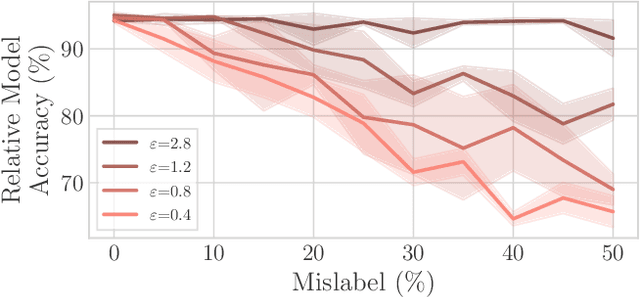
Federated Learning by nature is susceptible to low-quality, corrupted, or even malicious data that can severely degrade the quality of the learned model. Traditional techniques for data valuation cannot be applied as the data is never revealed. We present a novel technique for filtering, and scoring data based on a practical influence approximation that can be implemented in a privacy-preserving manner. Each agent uses his own data to evaluate the influence of another agent's batch, and reports to the center an obfuscated score using differential privacy. Our technique allows for almost perfect ($>92\%$ recall) filtering of corrupted data in a variety of applications using real-data. Importantly, the accuracy does not degrade significantly, even under really strong privacy guarantees ($\varepsilon \leq 1$), especially under realistic percentages of mislabeled data (for $15\%$ mislabeled data we only lose $10\%$ in accuracy).