 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Risk Detection of Pathological Gambling, Self-Harm and Depression Using BERT
Jun 30, 2021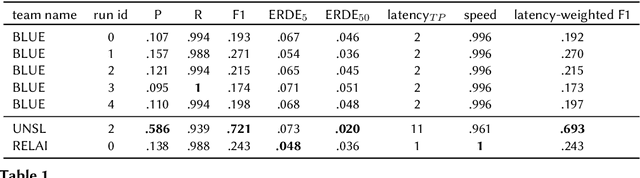
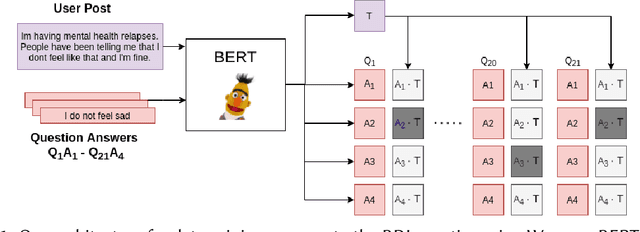

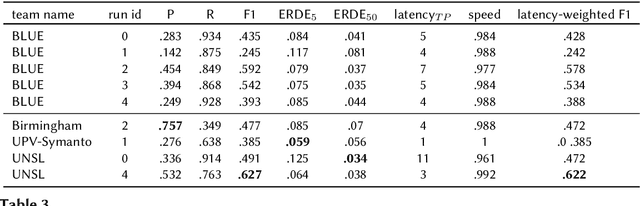
Early risk detection of mental illnesses has a massive positive impact upon the well-being of people. The eRisk workshop has been at the forefront of enabling interdisciplinary research in developing computational methods to automatically estimate early risk factors for mental issues such as depression, self-harm, anorexia and pathological gambling. In this paper, we present the contributions of the BLUE team in the 2021 edition of the workshop, in which we tackle the problems of early detection of gambling addiction, self-harm and estimating depression severity from social media posts. We employ pre-trained BERT transformers and data crawled automatically from mental health subreddits and obtain reasonable results on all three tasks.
An Exploratory Analysis of the Relation Between Offensive Language and Mental Health
May 31, 2021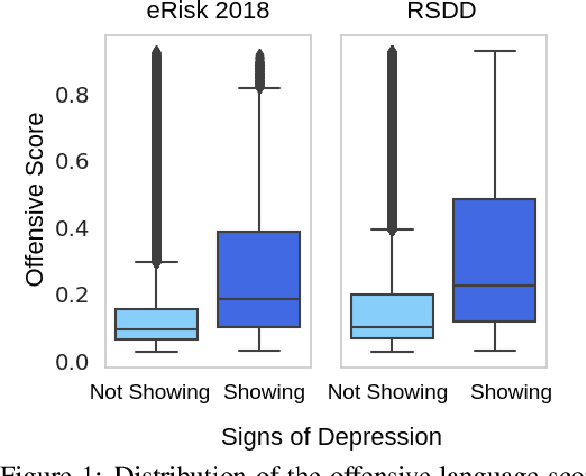
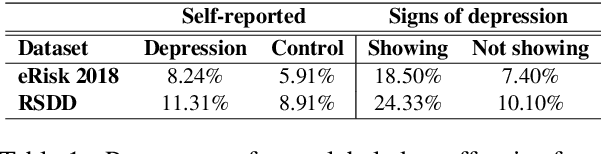
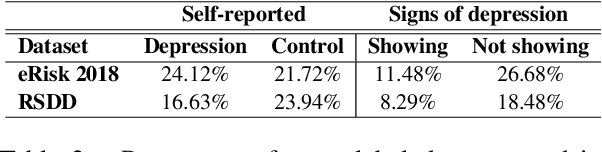
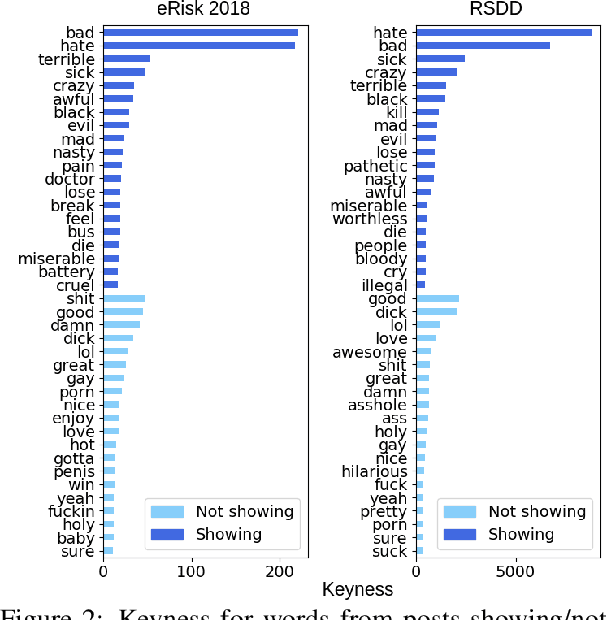
In this paper, we analyze the interplay between the use of offensive language and mental health. We acquired publicly available datasets created for offensive language identification and depression detection and we train computational models to compare the use of offensive language in social media posts written by groups of individuals with and without self-reported depression diagnosis. We also look at samples written by groups of individuals whose posts show signs of depression according to recent related studies. Our analysis indicates that offensive language is more frequently used in the samples written by individuals with self-reported depression as well as individuals showing signs of depression. The results discussed here open new avenues in research in politeness/offensiveness and mental health.
Analyzing Stylistic Variation across Different Political Regimes
Dec 02, 2020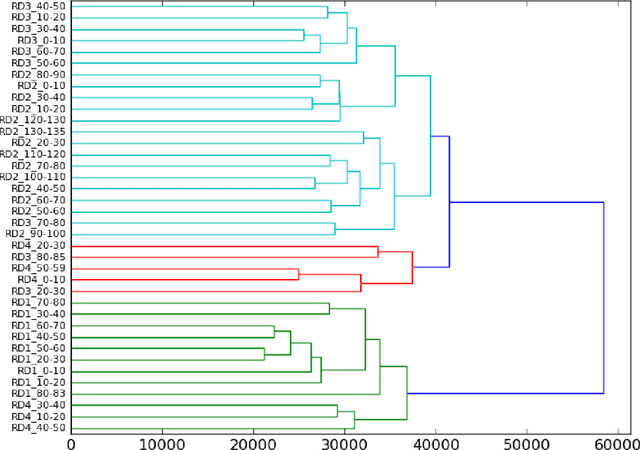

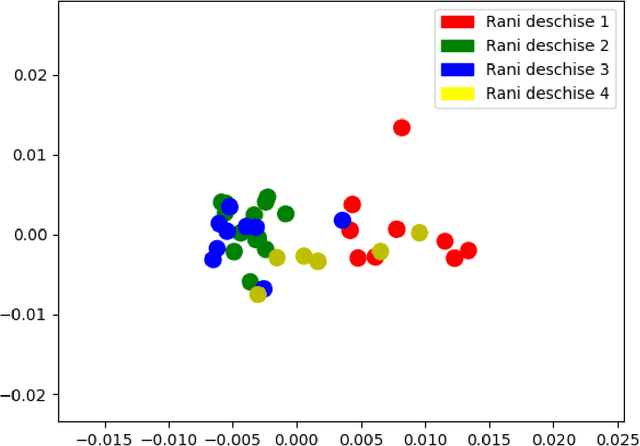
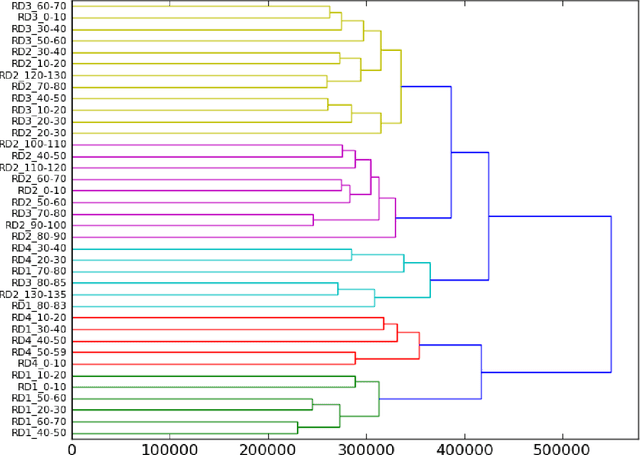
In this article we propose a stylistic analysis of texts written across two different periods, which differ not only temporally, but politically and culturally: communism and democracy in Romania. We aim to analyze the stylistic variation between texts written during these two periods, and determine at what levels the variation is more apparent (if any): at the stylistic level, at the topic level etc. We take a look at the stylistic profile of these texts comparatively, by performing clustering and classification experiments on the texts, using traditional authorship attribution methods and features. To confirm the stylistic variation is indeed an effect of the change in political and cultural environment, and not merely reflective of a natural change in the author's style with time, we look at various stylistic metrics over time and show that the change in style between the two periods is statistically significant. We also perform an analysis of the variation in topic between the two epochs, to compare with the variation at the style level. These analyses show that texts from the two periods can indeed be distinguished, both from the point of view of style and from that of semantic content (topic).
A Computational Approach to Measuring the Semantic Divergence of Cognates
Dec 02, 2020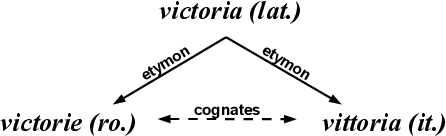
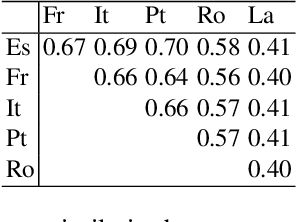
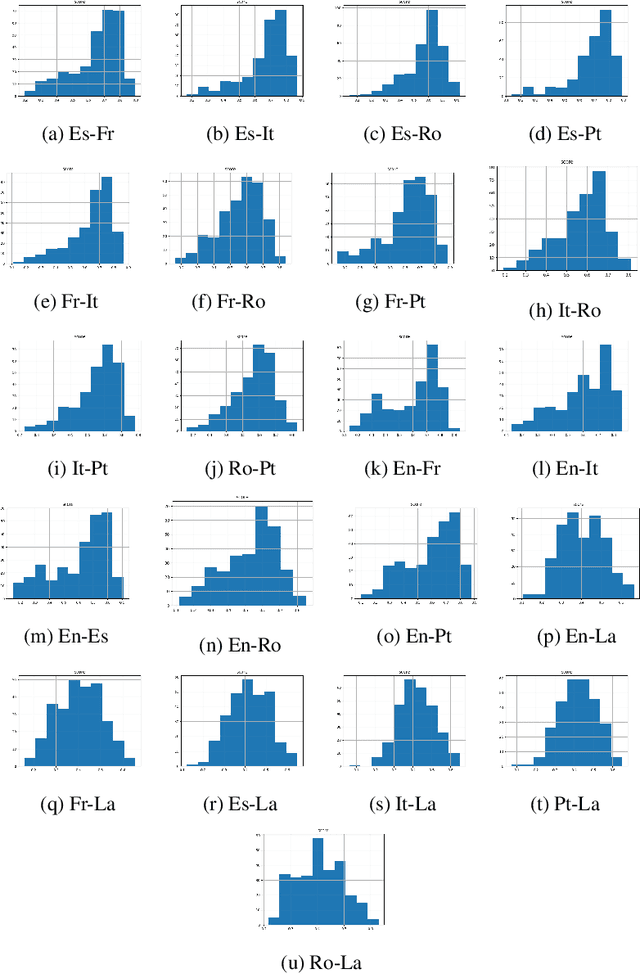

Meaning is the foundation stone of intercultural communication. Languages are continuously changing, and words shift their meanings for various reasons. Semantic divergence in related languages is a key concern of historical linguistics. In this paper we investigate semantic divergence across languages by measuring the semantic similarity of cognate sets in multiple languages. The method that we propose is based on cross-lingual word embeddings. In this paper we implement and evaluate our method on English and five Romance languages, but it can be extended easily to any language pair, requiring only large monolingual corpora for the involved languages and a small bilingual dictionary for the pair. This language-agnostic method facilitates a quantitative analysis of cognates divergence -- by computing degrees of semantic similarity between cognate pairs -- and provides insights for identifying false friends. As a second contribution, we formulate a straightforward method for detecting false friends, and introduce the notion of "soft false friend" and "hard false friend", as well as a measure of the degree of "falseness" of a false friends pair. Additionally, we propose an algorithm that can output suggestions for correcting false friends, which could result in a very helpful tool for language learning or translation.
Detecting Early Onset of Depression from Social Media Text using Learned Confidence Scores
Nov 03, 2020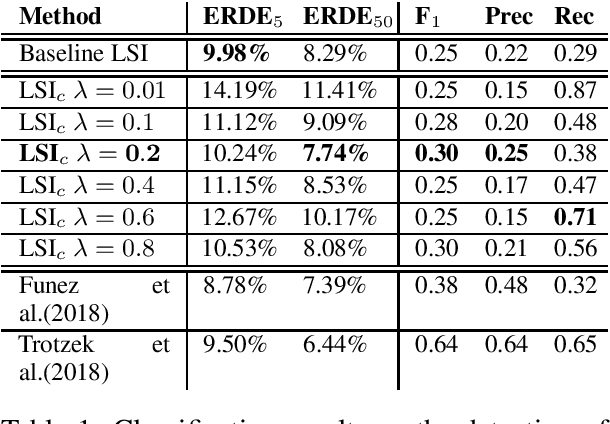
Computational research on mental health disorders from written texts covers an interdisciplinary area between natural language processing and psychology. A crucial aspect of this problem is prevention and early diagnosis, as suicide resulted from depression being the second leading cause of death for young adults. In this work, we focus on methods for detecting the early onset of depression from social media texts, in particular from Reddit. To that end, we explore the eRisk 2018 dataset and achieve good results with regard to the state of the art by leveraging topic analysis and learned confidence scores to guide the decision process.
Classifier Ensembles for Dialect and Language Variety Identification
Aug 14, 2018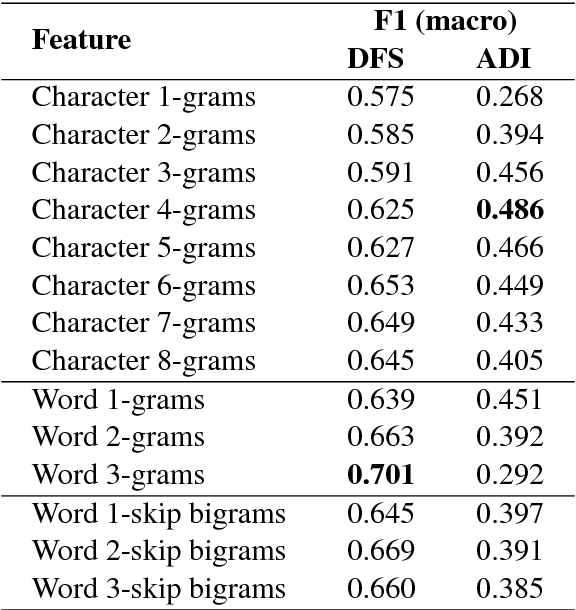
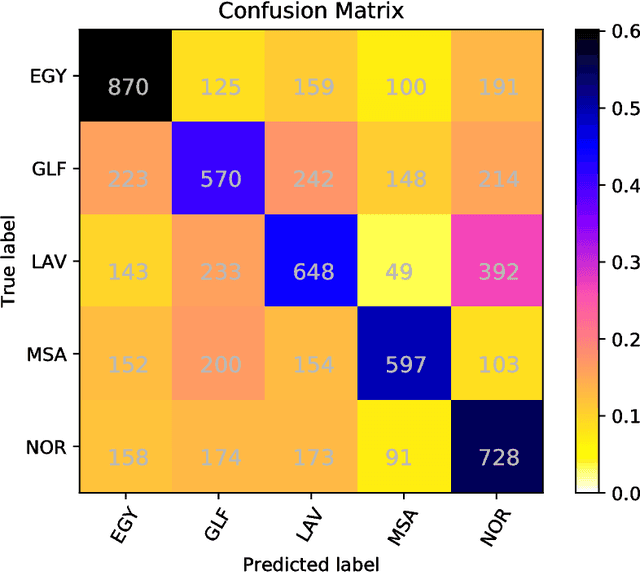
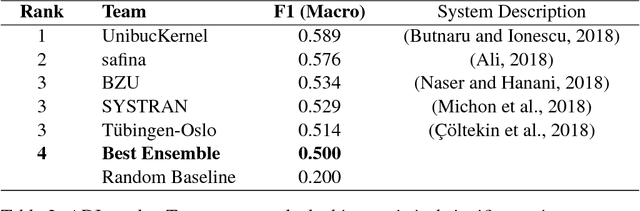
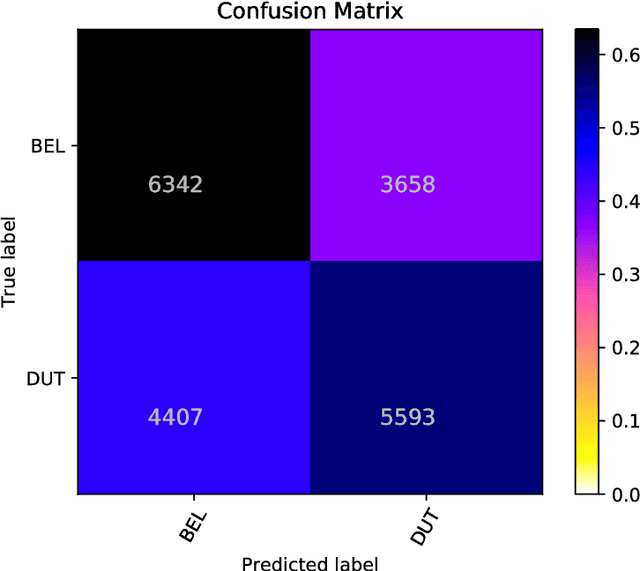
In this paper we present ensemble-based systems for dialect and language variety identification using the datasets made available by the organizers of the VarDial Evaluation Campaign 2018. We present a system developed to discriminate between Flemish and Dutch in subtitles and a system trained to discriminate between four Arabic dialects: Egyptian, Levantine, Gulf, North African, and Modern Standard Arabic in speech broadcasts. Finally, we compare the performance of these two systems with the other systems submitted to the Discriminating between Dutch and Flemish in Subtitles (DFS) and the Arabic Dialect Identification (ADI) shared tasks at VarDial 2018.
German Dialect Identification Using Classifier Ensembles
Jul 22, 2018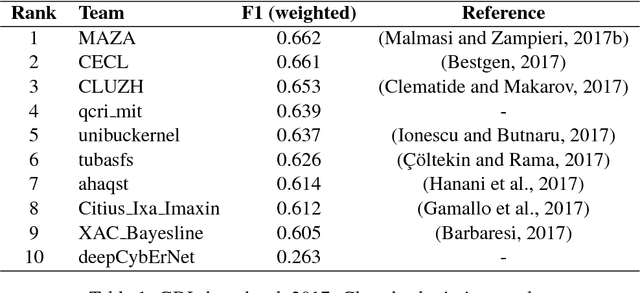
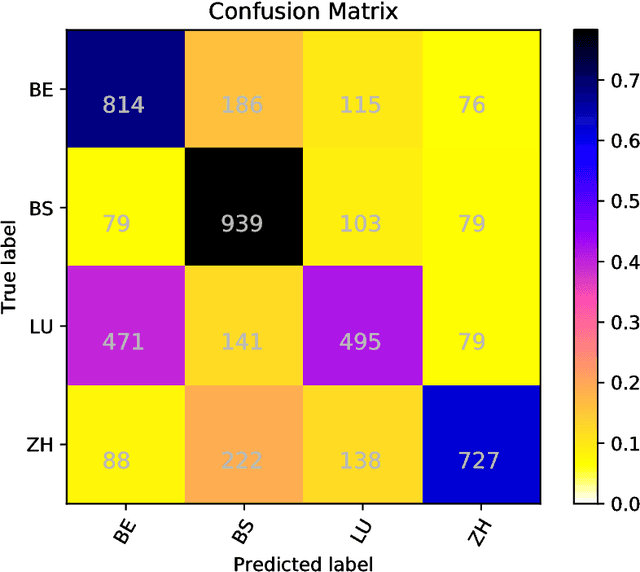
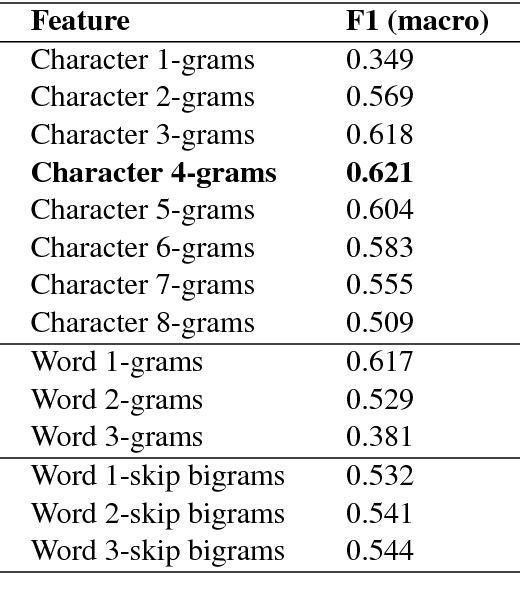
In this paper we present the GDI_classification entry to the second German Dialect Identification (GDI) shared task organized within the scope of the VarDial Evaluation Campaign 2018. We present a system based on SVM classifier ensembles trained on characters and words. The system was trained on a collection of speech transcripts of five Swiss-German dialects provided by the organizers. The transcripts included in the dataset contained speakers from Basel, Bern, Lucerne, and Zurich. Our entry in the challenge reached 62.03% F1-score and was ranked third out of eight teams.
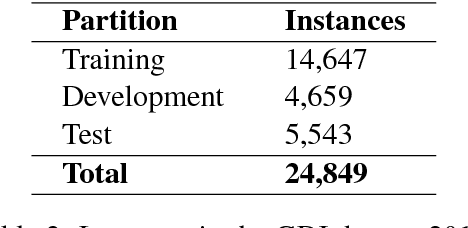
Discriminating between Indo-Aryan Languages Using SVM Ensembles
Jul 09, 2018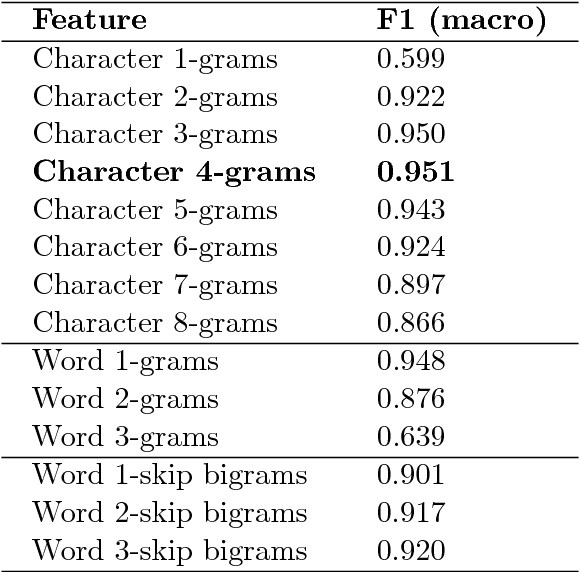
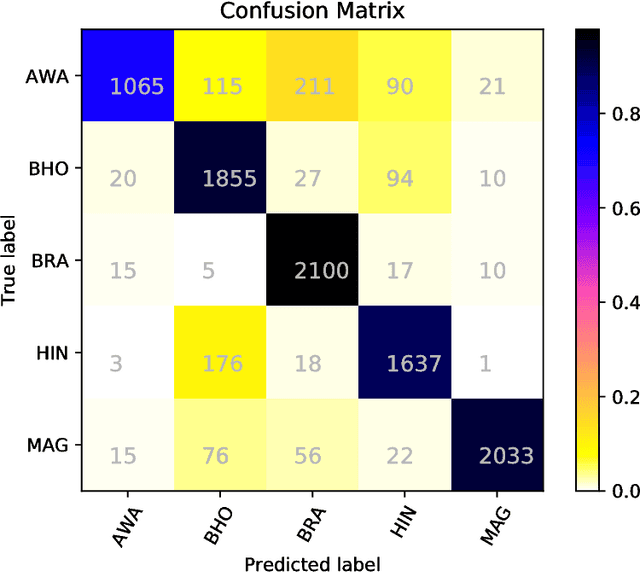

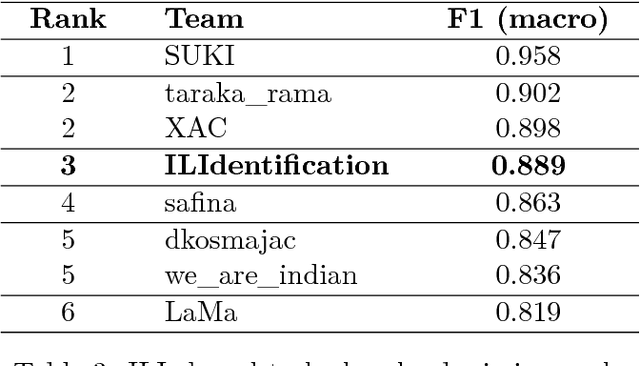
In this paper we present a system based on SVM ensembles trained on characters and words to discriminate between five similar languages of the Indo-Aryan family: Hindi, Braj Bhasha, Awadhi, Bhojpuri, and Magahi. We investigate the performance of individual features and combine the output of single classifiers to maximize performance. The system competed in the Indo-Aryan Language Identification (ILI) shared task organized within the VarDial Evaluation Campaign 2018. Our best entry in the competition, named ILIdentification, scored 88:95% F1 score and it was ranked 3rd out of 8 teams.
Exploring the Use of Text Classification in the Legal Domain
Oct 25, 2017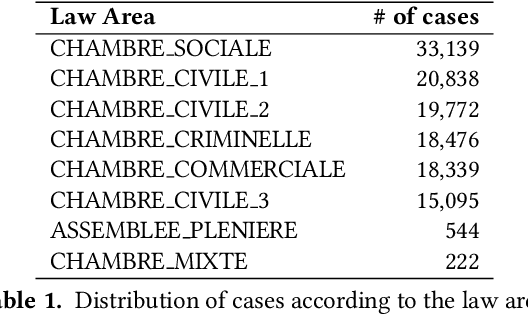
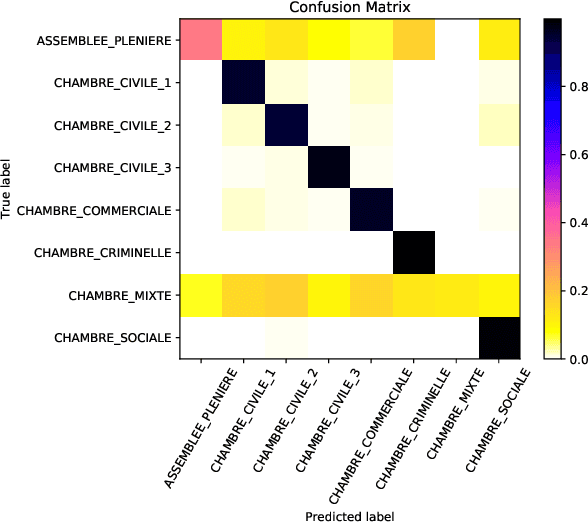
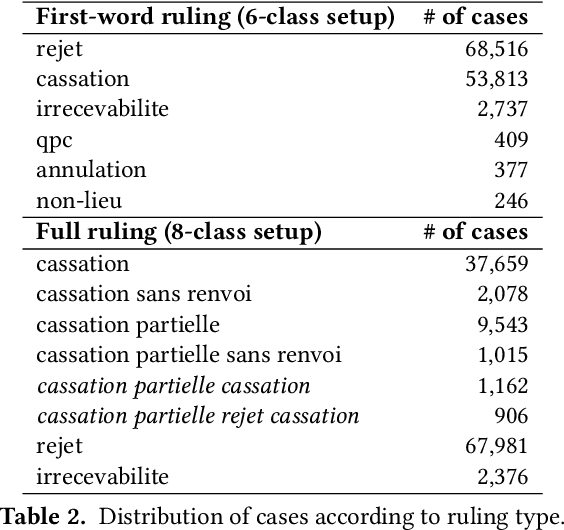
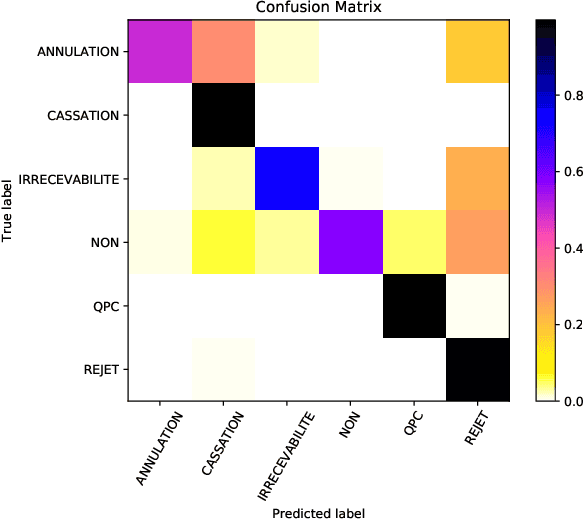
In this paper, we investigate the application of text classification methods to support law professionals. We present several experiments applying machine learning techniques to predict with high accuracy the ruling of the French Supreme Court and the law area to which a case belongs to. We also investigate the influence of the time period in which a ruling was made on the form of the case description and the extent to which we need to mask information in a full case ruling to automatically obtain training and test data that resembles case descriptions. We developed a mean probability ensemble system combining the output of multiple SVM classifiers. We report results of 98% average F1 score in predicting a case ruling, 96% F1 score for predicting the law area of a case, and 87.07% F1 score on estimating the date of a ruling.
Native Language Identification on Text and Speech
Jul 22, 2017
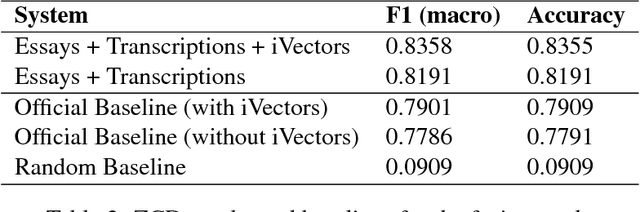
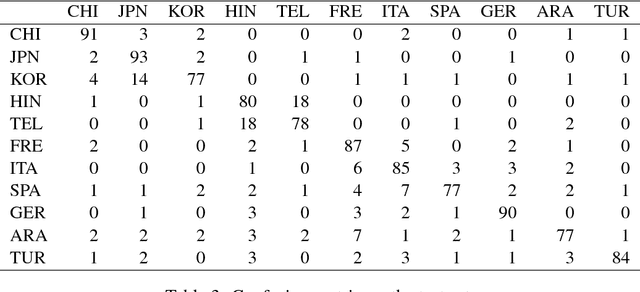

This paper presents an ensemble system combining the output of multiple SVM classifiers to native language identification (NLI). The system was submitted to the NLI Shared Task 2017 fusion track which featured students essays and spoken responses in form of audio transcriptions and iVectors by non-native English speakers of eleven native languages. Our system competed in the challenge under the team name ZCD and was based on an ensemble of SVM classifiers trained on character n-grams achieving 83.58% accuracy and ranking 3rd in the shared task.