 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLA-LDA: A Limited Attention Topic Model for Social Recommendation
Jan 26, 2013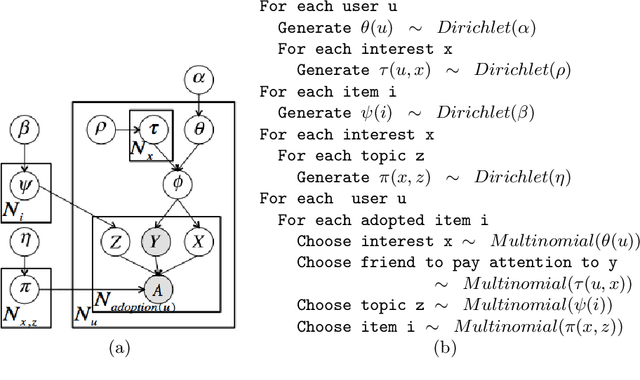

Social media users have finite attention which limits the number of incoming messages from friends they can process. Moreover, they pay more attention to opinions and recommendations of some friends more than others. In this paper, we propose LA-LDA, a latent topic model which incorporates limited, non-uniformly divided attention in the diffusion process by which opinions and information spread on the social network. We show that our proposed model is able to learn more accurate user models from users' social network and item adoption behavior than models which do not take limited attention into account. We analyze voting on news items on the social news aggregator Digg and show that our proposed model is better able to predict held out votes than alternative models. Our study demonstrates that psycho-socially motivated models have better ability to describe and predict observed behavior than models which only consider topics.
Bisimulation-based Approximate Lifted Inference
May 09, 2012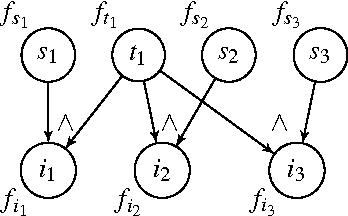

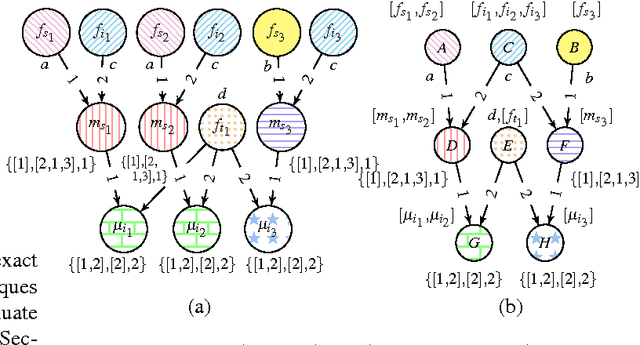
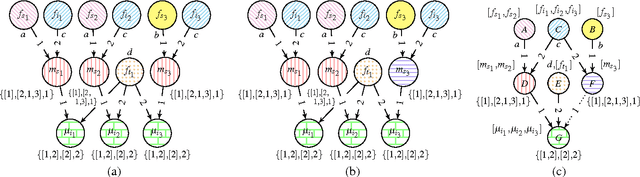
There has been a great deal of recent interest in methods for performing lifted inference; however, most of this work assumes that the first-order model is given as input to the system. Here, we describe lifted inference algorithms that determine symmetries and automatically lift the probabilistic model to speedup inference. In particular, we describe approximate lifted inference techniques that allow the user to trade off inference accuracy for computational efficiency by using a handful of tunable parameters, while keeping the error bounded. Our algorithms are closely related to the graph-theoretic concept of bisimulation. We report experiments on both synthetic and real data to show that in the presence of symmetries, run-times for inference can be improved significantly, with approximate lifted inference providing orders of magnitude speedup over ground inference.
Probabilistic Similarity Logic
Mar 15, 2012

Many machine learning applications require the ability to learn from and reason about noisy multi-relational data. To address this, several effective representations have been developed that provide both a language for expressing the structural regularities of a domain, and principled support for probabilistic inference. In addition to these two aspects, however, many applications also involve a third aspect-the need to reason about similarities-which has not been directly supported in existing frameworks. This paper introduces probabilistic similarity logic (PSL), a general-purpose framework for joint reasoning about similarity in relational domains that incorporates probabilistic reasoning about similarities and relational structure in a principled way. PSL can integrate any existing domain-specific similarity measures and also supports reasoning about similarities between sets of entities. We provide efficient inference and learning techniques for PSL and demonstrate its effectiveness both in common relational tasks and in settings that require reasoning about similarity.
Lifted Graphical Models: A Survey
Aug 26, 2011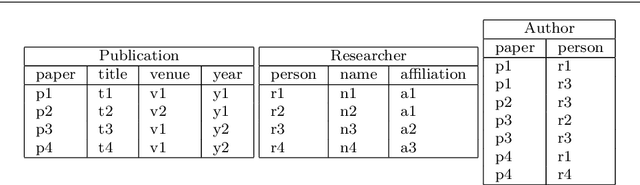
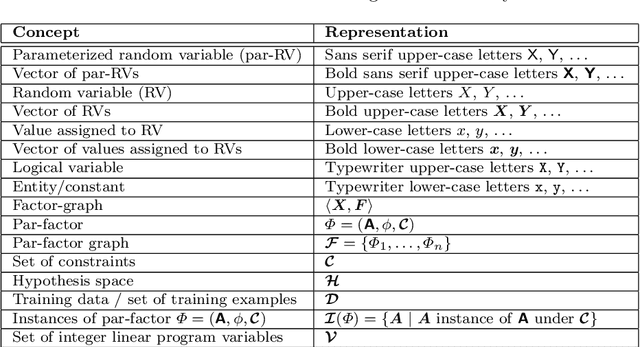
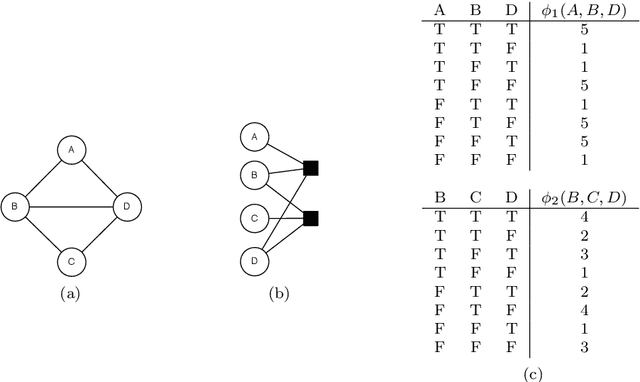
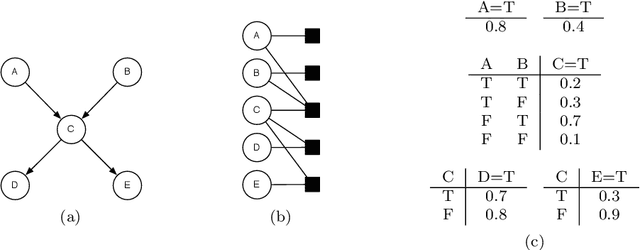
This article presents a survey of work on lifted graphical models. We review a general form for a lifted graphical model, a par-factor graph, and show how a number of existing statistical relational representations map to this formalism. We discuss inference algorithms, including lifted inference algorithms, that efficiently compute the answers to probabilistic queries. We also review work in learning lifted graphical models from data. It is our belief that the need for statistical relational models (whether it goes by that name or another) will grow in the coming decades, as we are inundated with data which is a mix of structured and unstructured, with entities and relations extracted in a noisy manner from text, and with the need to reason effectively with this data. We hope that this synthesis of ideas from many different research groups will provide an accessible starting point for new researchers in this expanding field.
A Probabilistic Approach for Learning Folksonomies from Structured Data
Nov 16, 2010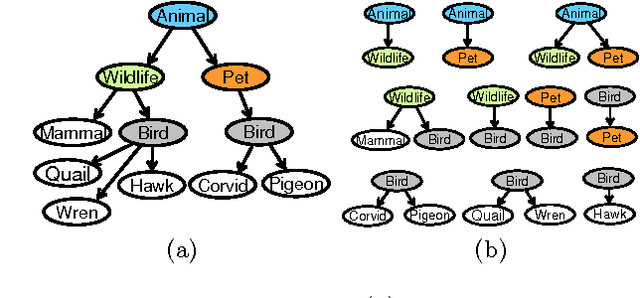
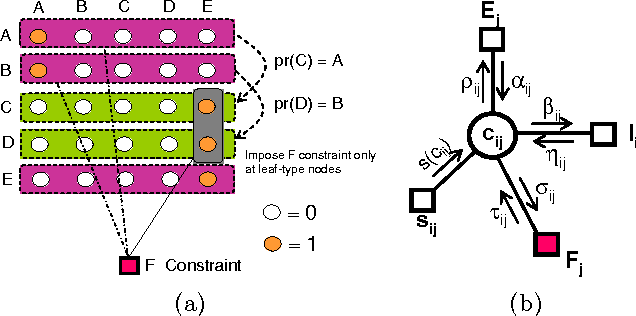
Learning structured representations has emerged as an important problem in many domains, including document and Web data mining, bioinformatics, and image analysis. One approach to learning complex structures is to integrate many smaller, incomplete and noisy structure fragments. In this work, we present an unsupervised probabilistic approach that extends affinity propagation to combine the small ontological fragments into a collection of integrated, consistent, and larger folksonomies. This is a challenging task because the method must aggregate similar structures while avoiding structural inconsistencies and handling noise. We validate the approach on a real-world social media dataset, comprised of shallow personal hierarchies specified by many individual users, collected from the photosharing website Flickr. Our empirical results show that our proposed approach is able to construct deeper and denser structures, compared to an approach using only the standard affinity propagation algorithm. Additionally, the approach yields better overall integration quality than a state-of-the-art approach based on incremental relational clustering.
Growing a Tree in the Forest: Constructing Folksonomies by Integrating Structured Metadata
May 27, 2010

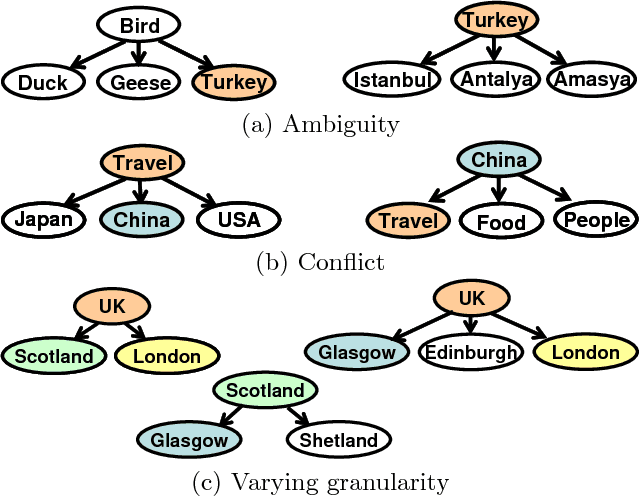
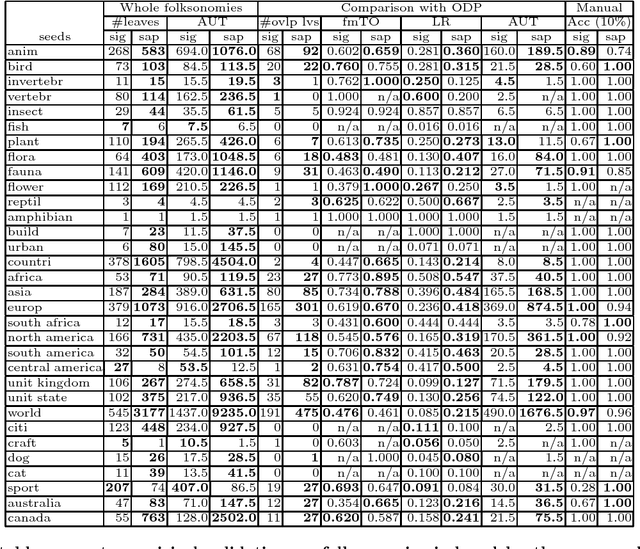
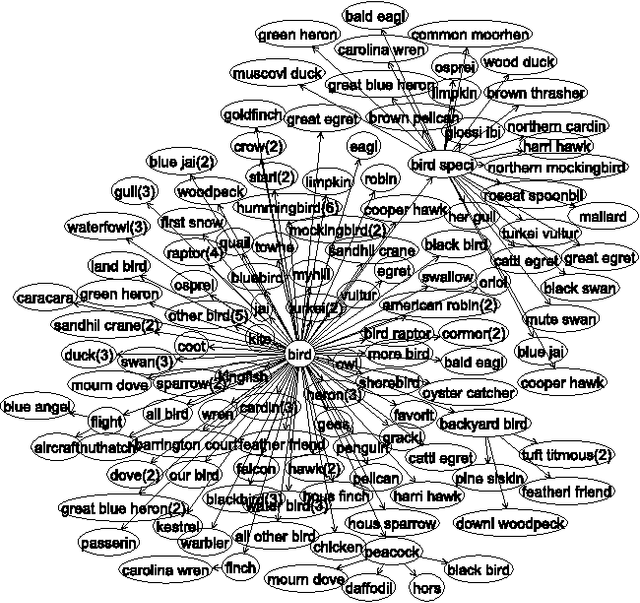
Many social Web sites allow users to annotate the content with descriptive metadata, such as tags, and more recently to organize content hierarchically. These types of structured metadata provide valuable evidence for learning how a community organizes knowledge. For instance, we can aggregate many personal hierarchies into a common taxonomy, also known as a folksonomy, that will aid users in visualizing and browsing social content, and also to help them in organizing their own content. However, learning from social metadata presents several challenges, since it is sparse, shallow, ambiguous, noisy, and inconsistent. We describe an approach to folksonomy learning based on relational clustering, which exploits structured metadata contained in personal hierarchies. Our approach clusters similar hierarchies using their structure and tag statistics, then incrementally weaves them into a deeper, bushier tree. We study folksonomy learning using social metadata extracted from the photo-sharing site Flickr, and demonstrate that the proposed approach addresses the challenges. Moreover, comparing to previous work, the approach produces larger, more accurate folksonomies, and in addition, scales better.
Integrating Structured Metadata with Relational Affinity Propagation
May 26, 2010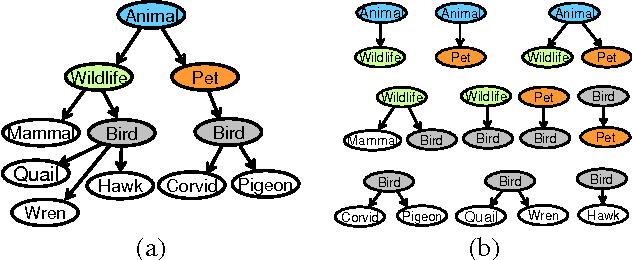
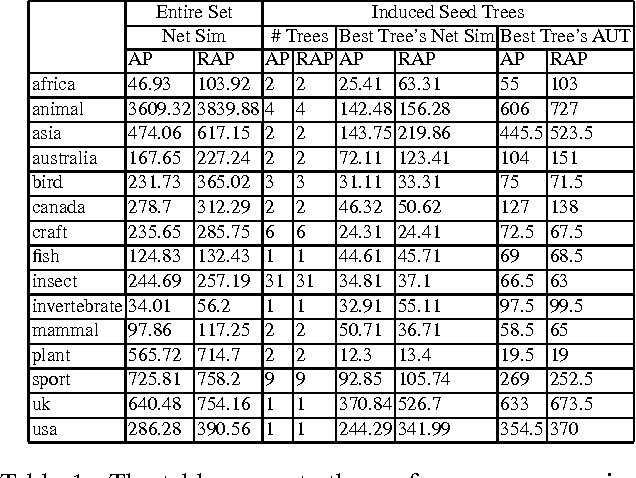
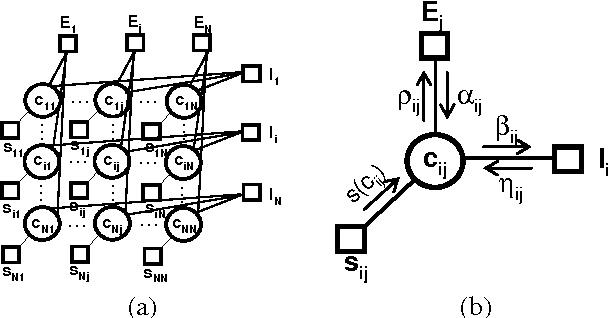
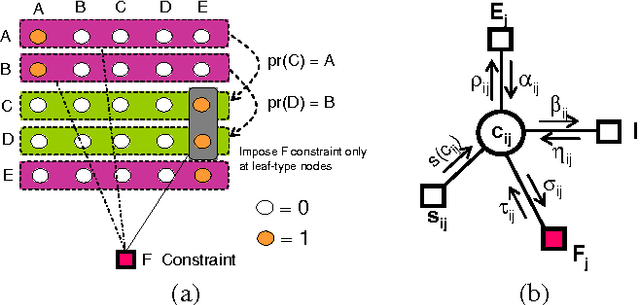
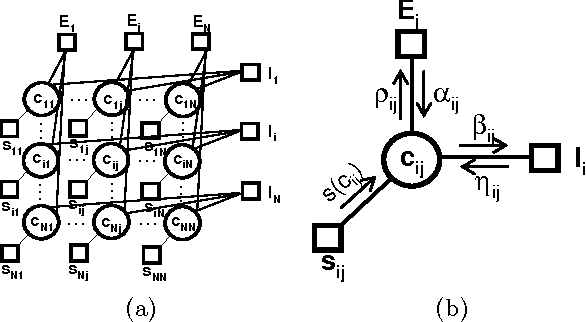
Structured and semi-structured data describing entities, taxonomies and ontologies appears in many domains. There is a huge interest in integrating structured information from multiple sources; however integrating structured data to infer complex common structures is a difficult task because the integration must aggregate similar structures while avoiding structural inconsistencies that may appear when the data is combined. In this work, we study the integration of structured social metadata: shallow personal hierarchies specified by many individual users on the SocialWeb, and focus on inferring a collection of integrated, consistent taxonomies. We frame this task as an optimization problem with structural constraints. We propose a new inference algorithm, which we refer to as Relational Affinity Propagation (RAP) that extends affinity propagation (Frey and Dueck 2007) by introducing structural constraints. We validate the approach on a real-world social media dataset, collected from the photosharing website Flickr. Our empirical results show that our proposed approach is able to construct deeper and denser structures compared to an approach using only the standard affinity propagation algorithm.