 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneGAN: Simultaneous Unsupervised Learning of Conditional Image Generation, Foreground Segmentation, and Fine-Grained Clustering
Dec 31, 2019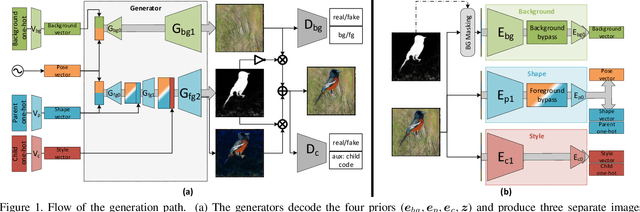
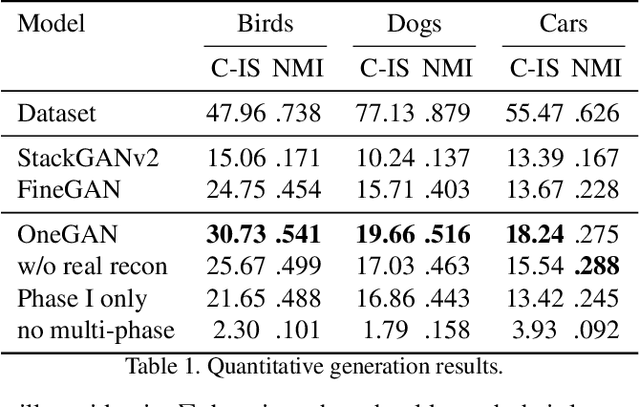
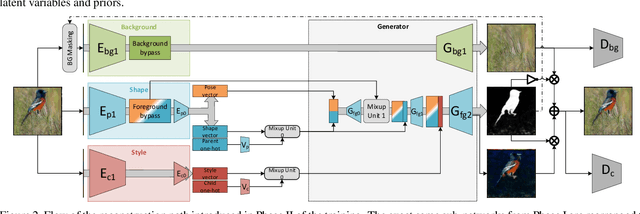
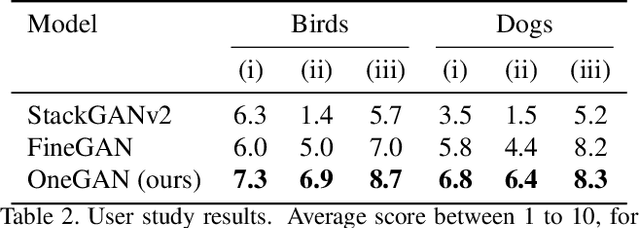
We present a method for simultaneously learning, in an unsupervised manner, (i) a conditional image generator, (ii) foreground extraction and segmentation, (iii) clustering into a two-level class hierarchy, and (iv) object removal and background completion, all done without any use of annotation. The method combines a generative adversarial network and a variational autoencoder, with multiple encoders, generators and discriminators, and benefits from solving all tasks at once. The input to the training scheme is a varied collection of unlabeled images from the same domain, as well as a set of background images without a foreground object. In addition, the image generator can mix the background from one image, with a foreground that is conditioned either on that of a second image or on the index of a desired cluster. The method obtains state of the art results in comparison to the literature methods, when compared to the current state of the art in each of the tasks.
Supervised and Unsupervised Learning of Parameterized Color Enhancement
Dec 30, 2019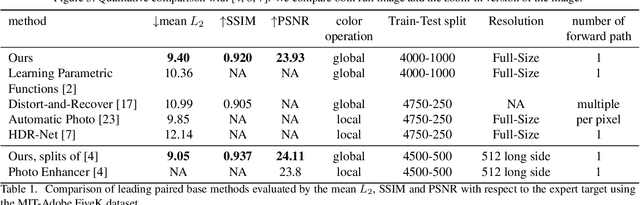
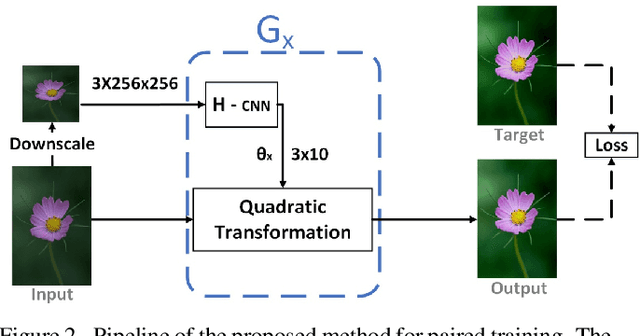

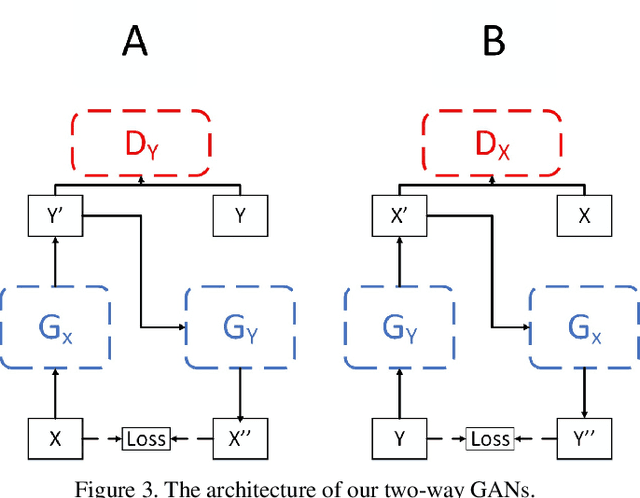
We treat the problem of color enhancement as an image translation task, which we tackle using both supervised and unsupervised learning. Unlike traditional image to image generators, our translation is performed using a global parameterized color transformation instead of learning to directly map image information. In the supervised case, every training image is paired with a desired target image and a convolutional neural network (CNN) learns from the expert retouched images the parameters of the transformation. In the unpaired case, we employ two-way generative adversarial networks (GANs) to learn these parameters and apply a circularity constraint. We achieve state-of-the-art results compared to both supervised (paired data) and unsupervised (unpaired data) image enhancement methods on the MIT-Adobe FiveK benchmark. Moreover, we show the generalization capability of our method, by applying it on photos from the early 20th century and to dark video frames.
Meta Decision Trees for Explainable Recommendation Systems
Dec 19, 2019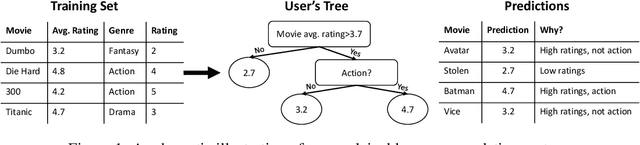
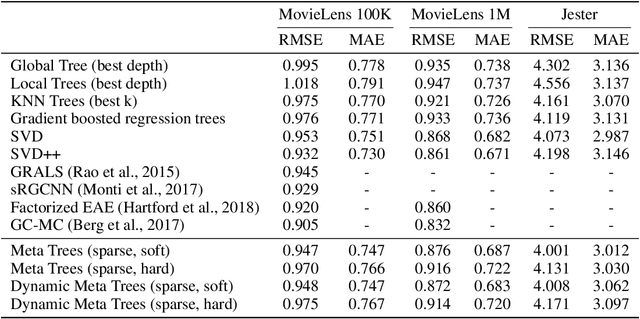


We tackle the problem of building explainable recommendation systems that are based on a per-user decision tree, with decision rules that are based on single attribute values. We build the trees by applying learned regression functions to obtain the decision rules as well as the values at the leaf nodes. The regression functions receive as input the embedding of the user's training set, as well as the embedding of the samples that arrive at the current node. The embedding and the regressors are learned end-to-end with a loss that encourages the decision rules to be sparse. By applying our method, we obtain a collaborative filtering solution that provides a direct explanation to every rating it provides. With regards to accuracy, it is competitive with other algorithms. However, as expected, explainability comes at a cost and the accuracy is typically slightly lower than the state of the art result reported in the literature.
End to End Trainable Active Contours via Differentiable Rendering
Dec 01, 2019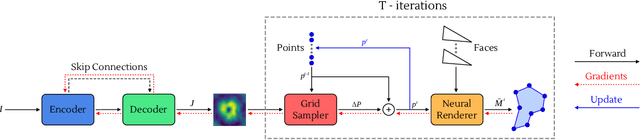
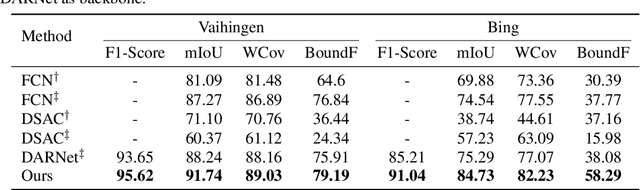

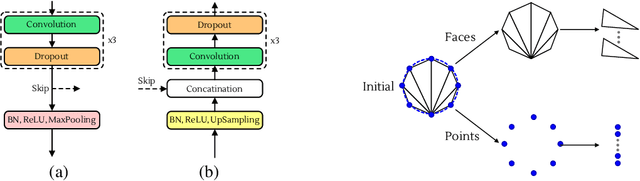
We present an image segmentation method that iteratively evolves a polygon. At each iteration, the vertices of the polygon are displaced based on the local value of a 2D shift map that is inferred from the input image via an encoder-decoder architecture. The main training loss that is used is the difference between the polygon shape and the ground truth segmentation mask. The network employs a neural renderer to create the polygon from its vertices, making the process fully differentiable. We demonstrate that our method outperforms the state of the art segmentation networks and deep active contour solutions in a variety of benchmarks, including medical imaging and aerial images. Our code is available at https://github.com/shirgur/ACDRNet.
Spectra2pix: Generating Nanostructure Images from Spectra
Nov 26, 2019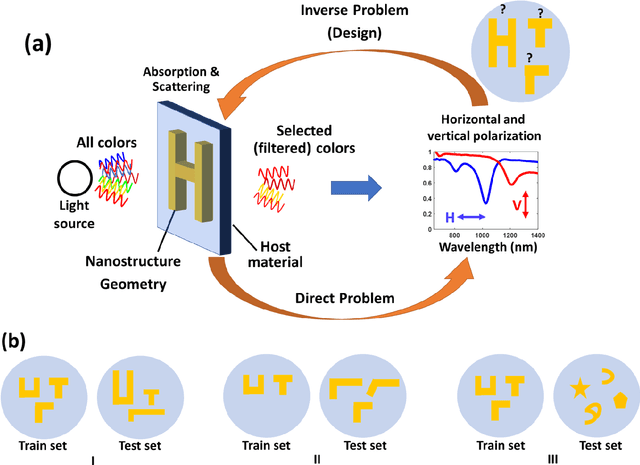
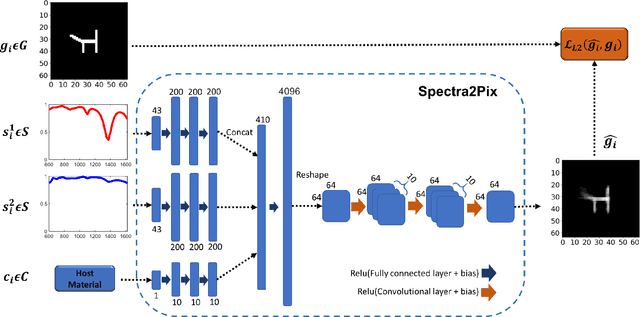
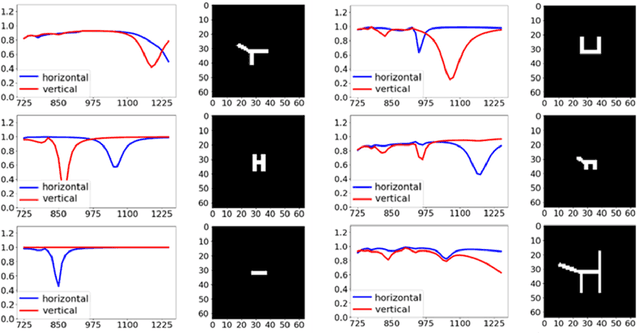
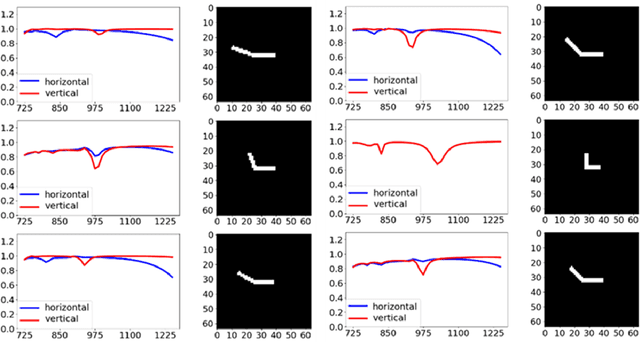
The design of the nanostructures that are used in the field of nano-photonics has remained complex, very often relying on the intuition and expertise of the designer, ultimately limiting the reach and penetration of this groundbreaking approach. Recently, there has been an increasing number of studies suggesting to apply Machine Learning techniques for the design of nanostructures. Most of these studies engage Deep Learning techniques, which entails training a Deep Neural Network (DNN) to approximate the highly non-linear function of the underlying physical process between spectra and nanostructures. At the end of the training, the DNN allows an on-demand design of nanostructures, i.e. the model can infer nanostructure geometries for desired spectra. In this work, we introduce spectra2pix, which is a model DNN trained to generate 2D images of the designed nanostructures. Our model architecture is not limited to a closed set of nanostructure shapes, and can be trained for the design of any geometry. We show, for the first time, a successful generalization ability by designing a completely unseen sub-family of geometries. This generalization capability highlights the importance of our model architecture, and allows higher applicability for real-world design problems.
Computational Ceramicology
Nov 22, 2019



Field archeologists are called upon to identify potsherds, for which purpose they rely on their experience and on reference works. We have developed two complementary machine-learning tools to propose identifications based on images captured on site. One method relies on the shape of the fracture outline of a sherd; the other is based on decorative features. For the outline-identification tool, a novel deep-learning architecture was employed, one that integrates shape information from points along the inner and outer surfaces. The decoration classifier is based on relatively standard architectures used in image recognition. In both cases, training the classifiers required tackling challenges that arise when working with real-world archeological data: paucity of labeled data; extreme imbalance between instances of the different categories; and the need to avoid neglecting rare classes and to take note of minute distinguishing features of some classes. The scarcity of training data was overcome by using synthetically-produced virtual potsherds and by employing multiple data-augmentation techniques. A novel form of training loss allowed us to overcome the problems caused by under-populated classes and non-homogeneous distribution of discriminative features.
Live Face De-Identification in Video
Nov 19, 2019

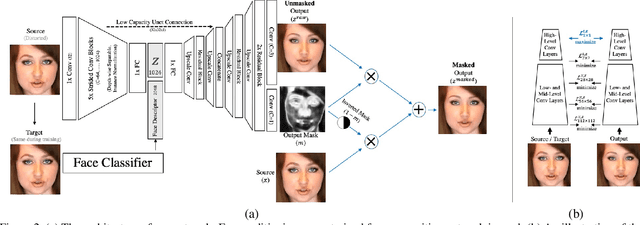
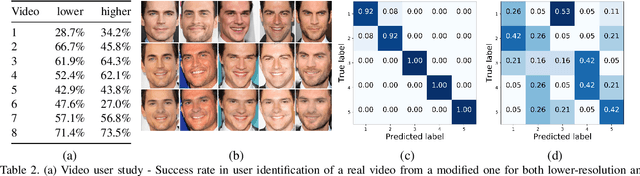
We propose a method for face de-identification that enables fully automatic video modification at high frame rates. The goal is to maximally decorrelate the identity, while having the perception (pose, illumination and expression) fixed. We achieve this by a novel feed-forward encoder-decoder network architecture that is conditioned on the high-level representation of a person's facial image. The network is global, in the sense that it does not need to be retrained for a given video or for a given identity, and it creates natural looking image sequences with little distortion in time.
* ICCV 2019
A Gated Hypernet Decoder for Polar Codes
Nov 08, 2019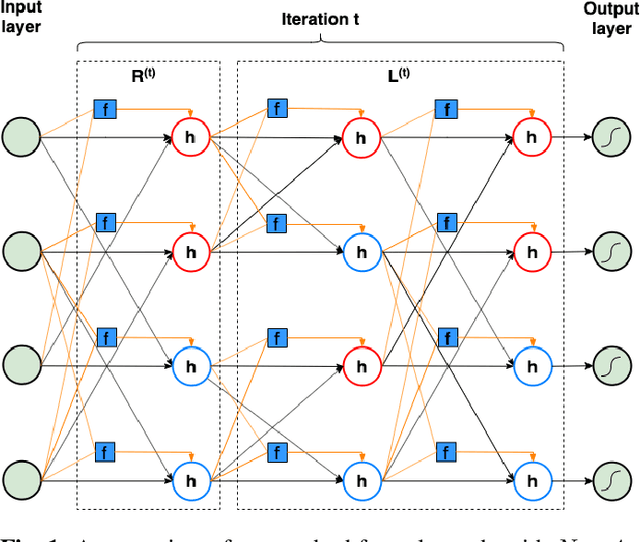

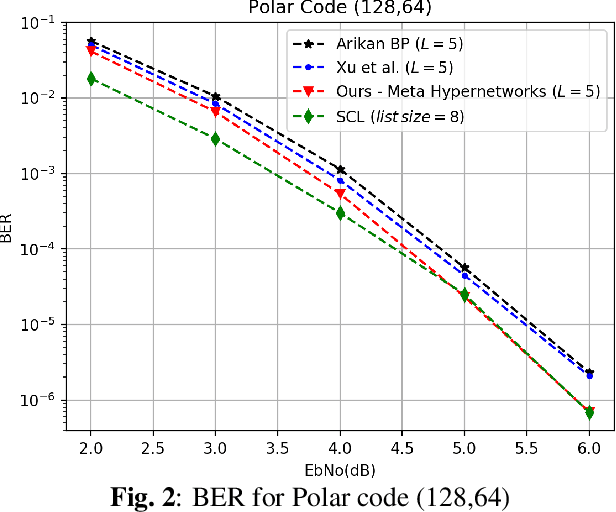
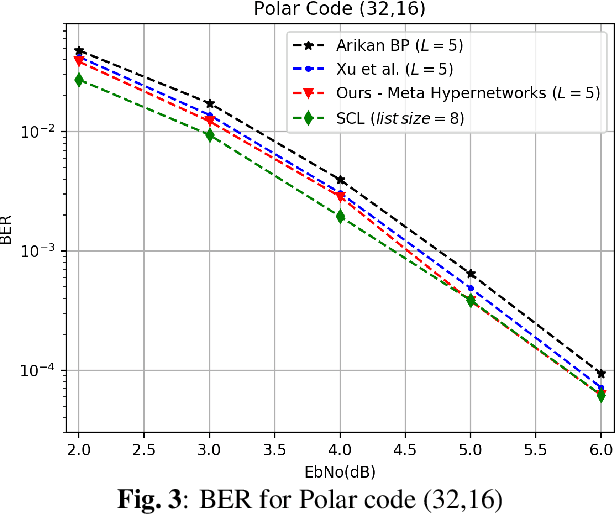
Hypernetworks were recently shown to improve the performance of message passing algorithms for decoding error correcting codes. In this work, we demonstrate how hypernetworks can be applied to decode polar codes by employing a new formalization of the polar belief propagation decoding scheme. We demonstrate that our method improves the previous results of neural polar decoders and achieves, for large SNRs, the same bit-error-rate performances as the successive list cancellation method, which is known to be better than any belief propagation decoders and very close to the maximum likelihood decoder.
Electric Analog Circuit Design with Hypernetworks and a Differential Simulator
Nov 08, 2019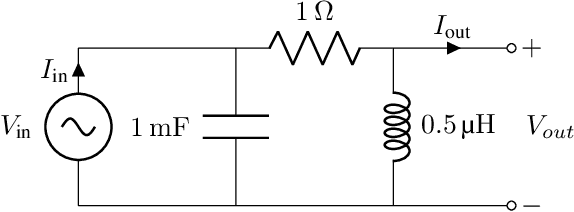

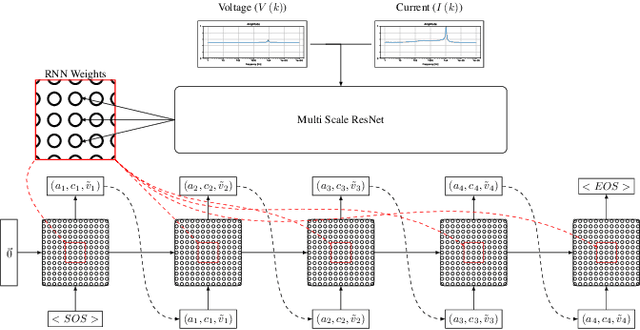
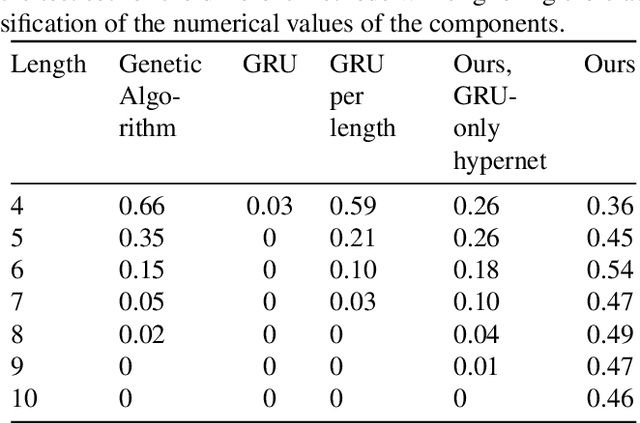
The manual design of analog circuits is a tedious task of parameter tuning that requires hours of work by human experts. In this work, we make a significant step towards a fully automatic design method that is based on deep learning. The method selects the components and their configuration, as well as their numerical parameters. By contrast, the current literature methods are limited to the parameter fitting part only. A two-stage network is used, which first generates a chain of circuit components and then predicts their parameters. A hypernetwork scheme is used in which a weight generating network, which is conditioned on the circuit's power spectrum, produces the parameters of a primal RNN network that places the components. A differential simulator is used for refining the numerical values of the components. We show that our model provides an efficient design solution, and is superior to alternative solutions.
MML: Maximal Multiverse Learning for Robust Fine-Tuning of Language Models
Nov 05, 2019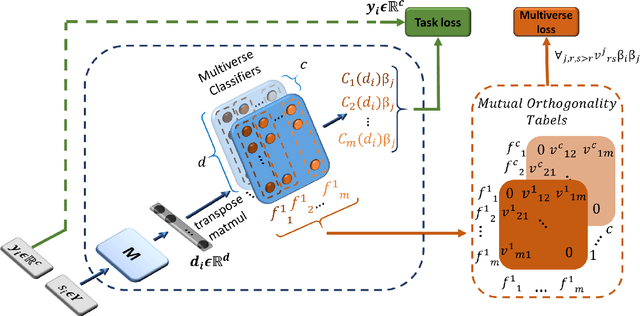
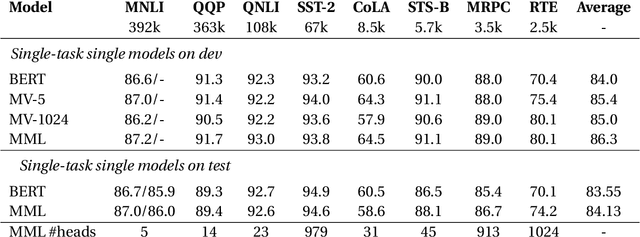
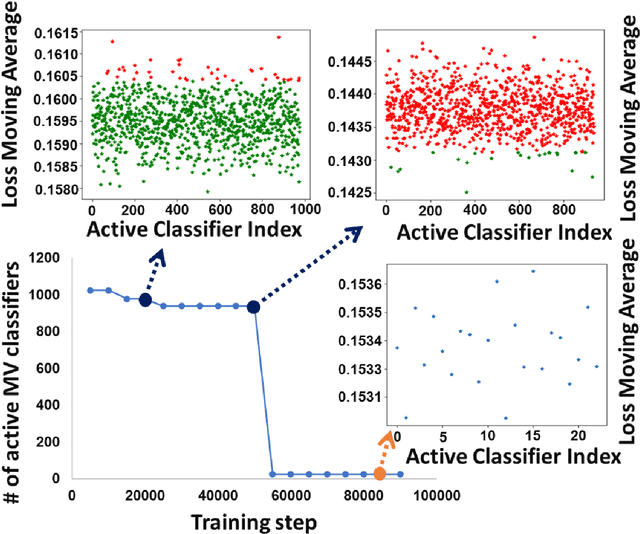
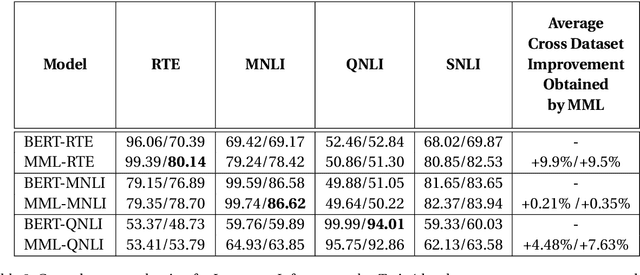
Recent state-of-the-art language models utilize a two-phase training procedure comprised of (i) unsupervised pre-training on unlabeled text, and (ii) fine-tuning for a specific supervised task. More recently, many studies have been focused on trying to improve these models by enhancing the pre-training phase, either via better choice of hyperparameters or by leveraging an improved formulation. However, the pre-training phase is computationally expensive and often done on private datasets. In this work, we present a method that leverages BERT's fine-tuning phase to its fullest, by applying an extensive number of parallel classifier heads, which are enforced to be orthogonal, while adaptively eliminating the weaker heads during training. Our method allows the model to converge to an optimal number of parallel classifiers, depending on the given dataset at hand. We conduct an extensive inter- and intra-dataset evaluations, showing that our method improves the robustness of BERT, sometimes leading to a +9\% gain in accuracy. These results highlight the importance of a proper fine-tuning procedure, especially for relatively smaller-sized datasets. Our code is attached as supplementary and our models will be made completely public.