 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Defense of the Learning Without Forgetting for Task Incremental Learning
Jul 26, 2021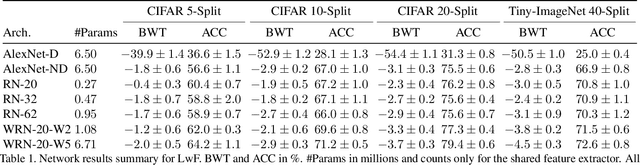
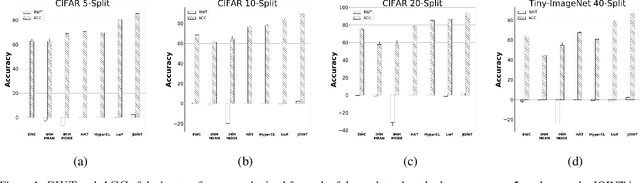

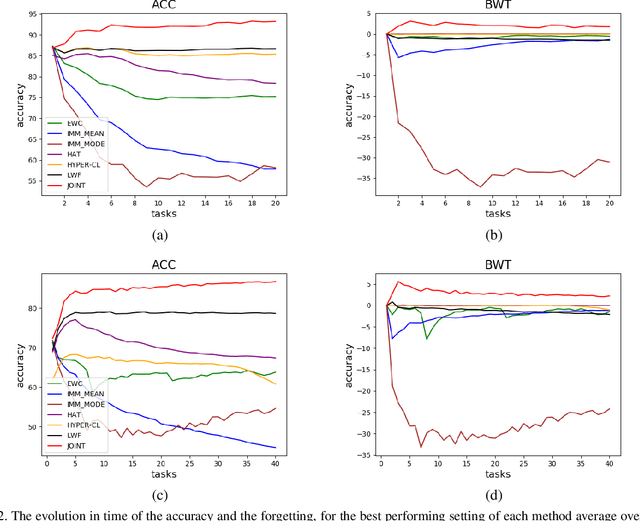
Catastrophic forgetting is one of the major challenges on the road for continual learning systems, which are presented with an on-line stream of tasks. The field has attracted considerable interest and a diverse set of methods have been presented for overcoming this challenge. Learning without Forgetting (LwF) is one of the earliest and most frequently cited methods. It has the advantages of not requiring the storage of samples from the previous tasks, of implementation simplicity, and of being well-grounded by relying on knowledge distillation. However, the prevailing view is that while it shows a relatively small amount of forgetting when only two tasks are introduced, it fails to scale to long sequences of tasks. This paper challenges this view, by showing that using the right architecture along with a standard set of augmentations, the results obtained by LwF surpass the latest algorithms for task incremental scenario. This improved performance is demonstrated by an extensive set of experiments over CIFAR-100 and Tiny-ImageNet, where it is also shown that other methods cannot benefit as much from similar improvements.
Non Gaussian Denoising Diffusion Models
Jun 14, 2021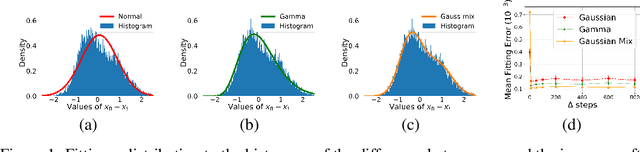

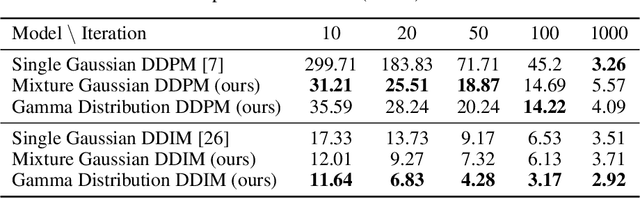

Generative diffusion processes are an emerging and effective tool for image and speech generation. In the existing methods, the underline noise distribution of the diffusion process is Gaussian noise. However, fitting distributions with more degrees of freedom, could help the performance of such generative models. In this work, we investigate other types of noise distribution for the diffusion process. Specifically, we show that noise from Gamma distribution provides improved results for image and speech generation. Moreover, we show that using a mixture of Gaussian noise variables in the diffusion process improves the performance over a diffusion process that is based on a single distribution. Our approach preserves the ability to efficiently sample state in the training diffusion process while using Gamma noise and a mixture of noise.
Recovering AES Keys with a Deep Cold Boot Attack
Jun 09, 2021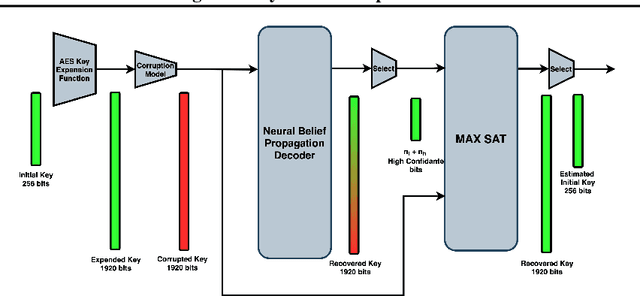
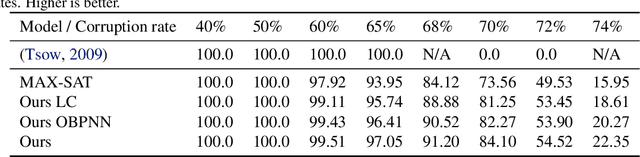
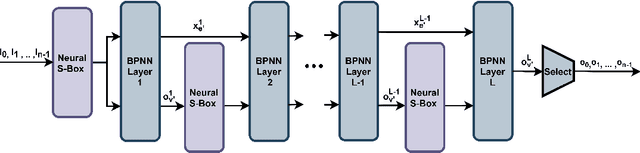
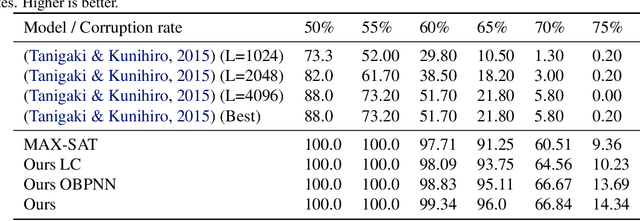
Cold boot attacks inspect the corrupted random access memory soon after the power has been shut down. While most of the bits have been corrupted, many bits, at random locations, have not. Since the keys in many encryption schemes are being expanded in memory into longer keys with fixed redundancies, the keys can often be restored. In this work, we combine a novel cryptographic variant of a deep error correcting code technique with a modified SAT solver scheme to apply the attack on AES keys. Even though AES consists of Rijndael S-box elements, that are specifically designed to be resistant to linear and differential cryptanalysis, our method provides a novel formalization of the AES key scheduling as a computational graph, which is implemented by a neural message passing network. Our results show that our methods outperform the state of the art attack methods by a very large margin.
Natural Statistics of Network Activations and Implications for Knowledge Distillation
Jun 01, 2021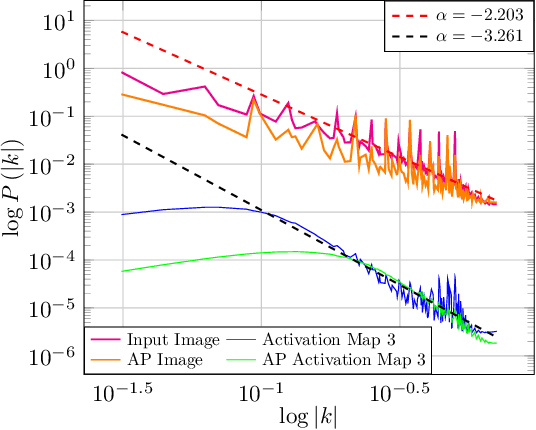
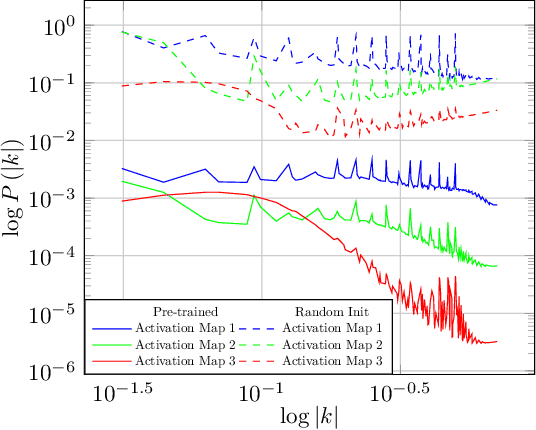

In a matter that is analog to the study of natural image statistics, we study the natural statistics of the deep neural network activations at various layers. As we show, these statistics, similar to image statistics, follow a power law. We also show, both analytically and empirically, that with depth the exponent of this power law increases at a linear rate. As a direct implication of our discoveries, we present a method for performing Knowledge Distillation (KD). While classical KD methods consider the logits of the teacher network, more recent methods obtain a leap in performance by considering the activation maps. This, however, uses metrics that are suitable for comparing images. We propose to employ two additional loss terms that are based on the spectral properties of the intermediate activation maps. The proposed method obtains state of the art results on multiple image recognition KD benchmarks.
Identity and Attribute Preserving Thumbnail Upscaling
May 30, 2021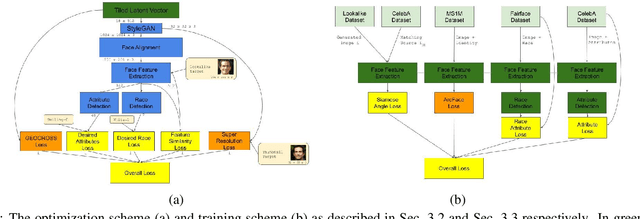
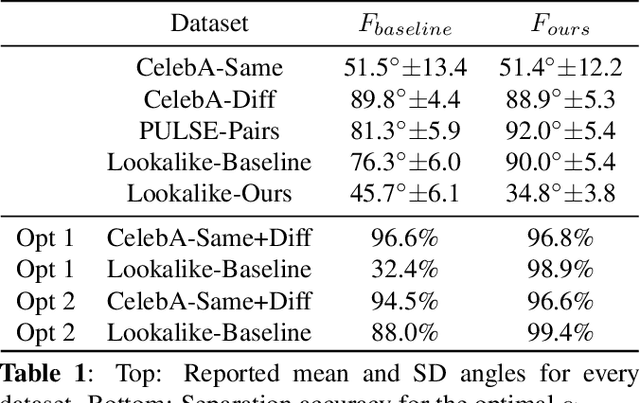


We consider the task of upscaling a low resolution thumbnail image of a person, to a higher resolution image, which preserves the person's identity and other attributes. Since the thumbnail image is of low resolution, many higher resolution versions exist. Previous approaches produce solutions where the person's identity is not preserved, or biased solutions, such as predominantly Caucasian faces. We address the existing ambiguity by first augmenting the feature extractor to better capture facial identity, facial attributes (such as smiling or not) and race, and second, use this feature extractor to generate high-resolution images which are identity preserving as well as conditioned on race and facial attributes. Our results indicate an improvement in face similarity recognition and lookalike generation as well as in the ability to generate higher resolution images which preserve an input thumbnail identity and whose race and attributes are maintained.
HyperHyperNetworks for the Design of Antenna Arrays
May 09, 2021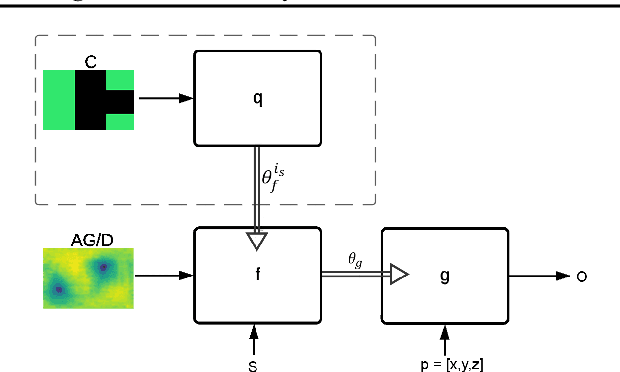
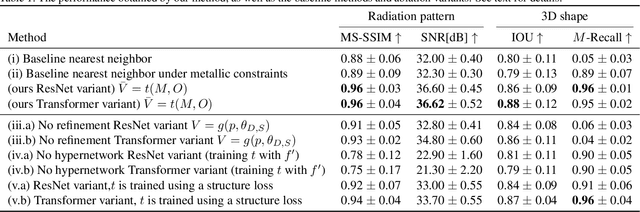

We present deep learning methods for the design of arrays and single instances of small antennas. Each design instance is conditioned on a target radiation pattern and is required to conform to specific spatial dimensions and to include, as part of its metallic structure, a set of predetermined locations. The solution, in the case of a single antenna, is based on a composite neural network that combines a simulation network, a hypernetwork, and a refinement network. In the design of the antenna array, we add an additional design level and employ a hypernetwork within a hypernetwork. The learning objective is based on measuring the similarity of the obtained radiation pattern to the desired one. Our experiments demonstrate that our approach is able to design novel antennas and antenna arrays that are compliant with the design requirements, considerably better than the baseline methods. We compare the solutions obtained by our method to existing designs and demonstrate a high level of overlap. When designing the antenna array of a cellular phone, the obtained solution displays improved properties over the existing one.
A Hierarchical Transformation-Discriminating Generative Model for Few Shot Anomaly Detection
Apr 29, 2021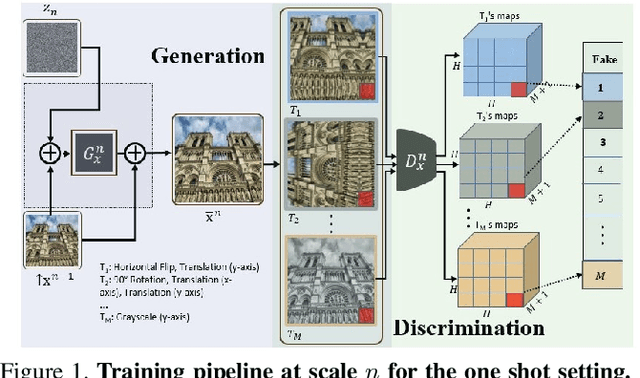
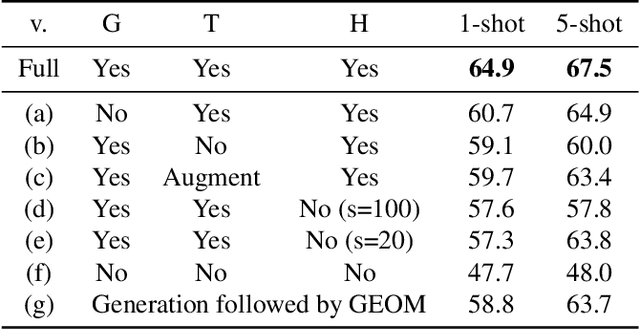
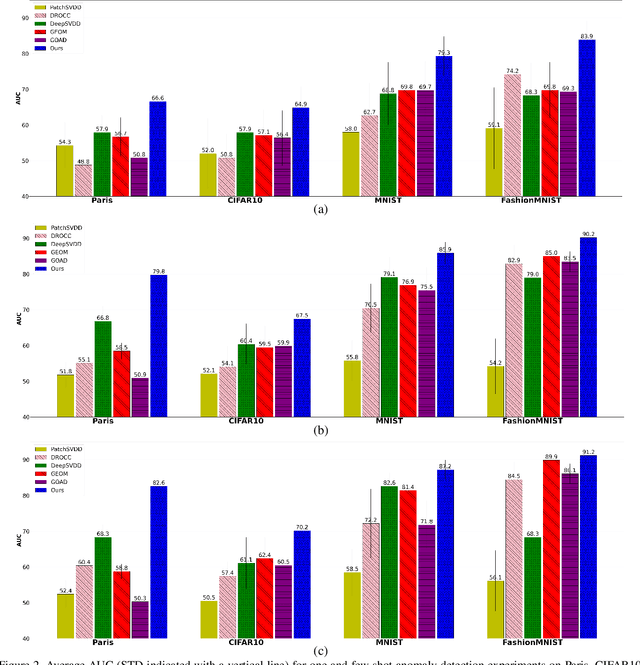

Anomaly detection, the task of identifying unusual samples in data, often relies on a large set of training samples. In this work, we consider the setting of few-shot anomaly detection in images, where only a few images are given at training. We devise a hierarchical generative model that captures the multi-scale patch distribution of each training image. We further enhance the representation of our model by using image transformations and optimize scale-specific patch-discriminators to distinguish between real and fake patches of the image, as well as between different transformations applied to those patches. The anomaly score is obtained by aggregating the patch-based votes of the correct transformation across scales and image regions. We demonstrate the superiority of our method on both the one-shot and few-shot settings, on the datasets of Paris, CIFAR10, MNIST and FashionMNIST as well as in the setting of defect detection on MVTec. In all cases, our method outperforms the recent baseline methods.
Many-Speakers Single Channel Speech Separation with Optimal Permutation Training
Apr 18, 2021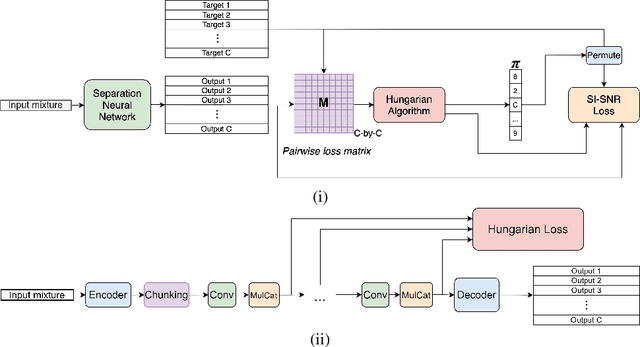
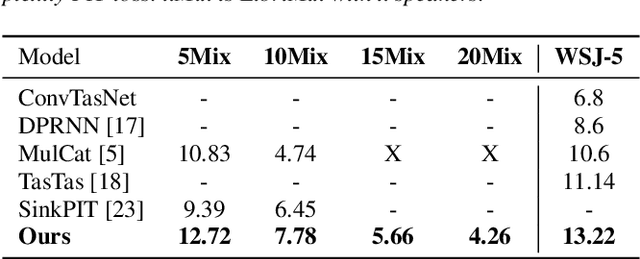
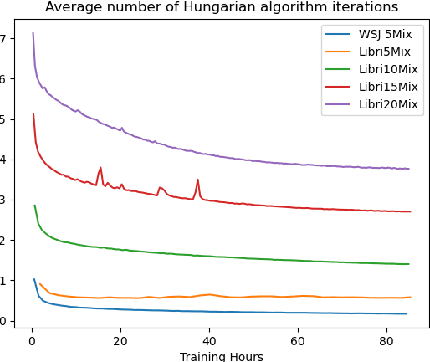
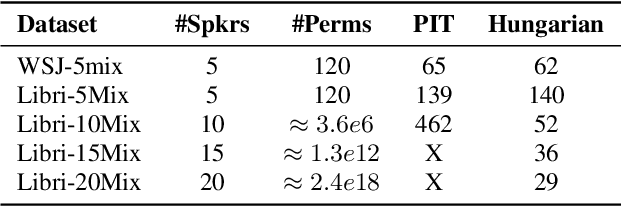
Single channel speech separation has experienced great progress in the last few years. However, training neural speech separation for a large number of speakers (e.g., more than 10 speakers) is out of reach for the current methods, which rely on the Permutation Invariant Loss (PIT). In this work, we present a permutation invariant training that employs the Hungarian algorithm in order to train with an $O(C^3)$ time complexity, where $C$ is the number of speakers, in comparison to $O(C!)$ of PIT based methods. Furthermore, we present a modified architecture that can handle the increased number of speakers. Our approach separates up to $20$ speakers and improves the previous results for large $C$ by a wide margin.
Noise Estimation for Generative Diffusion Models
Apr 06, 2021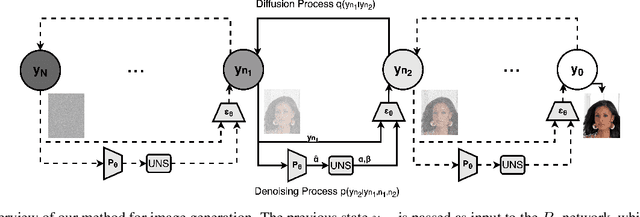
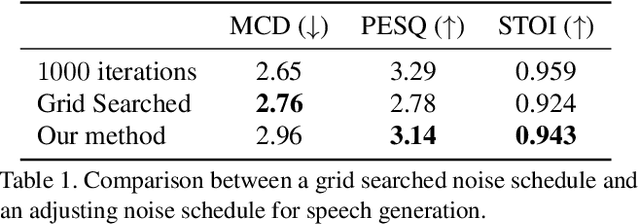
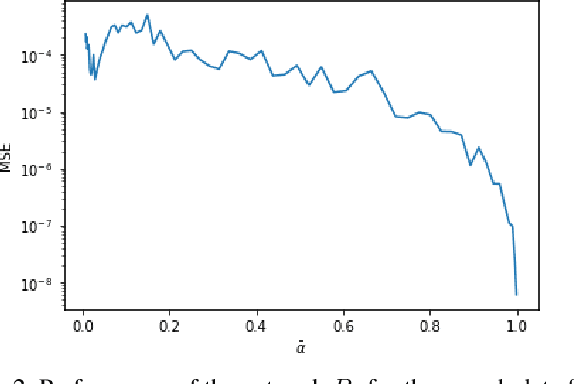

Generative diffusion models have emerged as leading models in speech and image generation. However, in order to perform well with a small number of denoising steps, a costly tuning of the set of noise parameters is needed. In this work, we present a simple and versatile learning scheme that can step-by-step adjust those noise parameters, for any given number of steps, while the previous work needs to retune for each number separately. Furthermore, without modifying the weights of the diffusion model, we are able to significantly improve the synthesis results, for a small number of steps. Our approach comes at a negligible computation cost.
Adaptive Gradient Balancing for UndersampledMRI Reconstruction and Image-to-Image Translation
Apr 05, 2021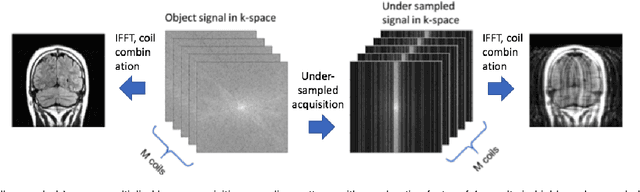
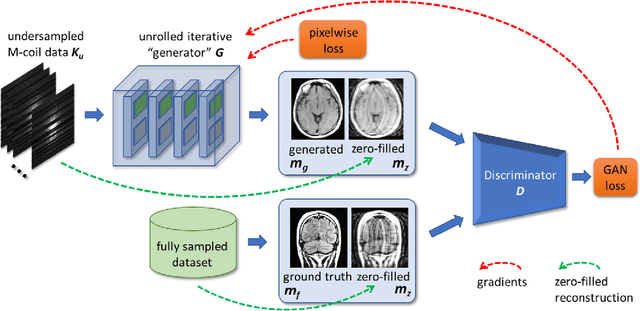
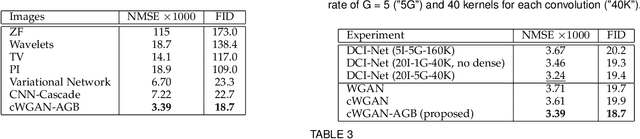
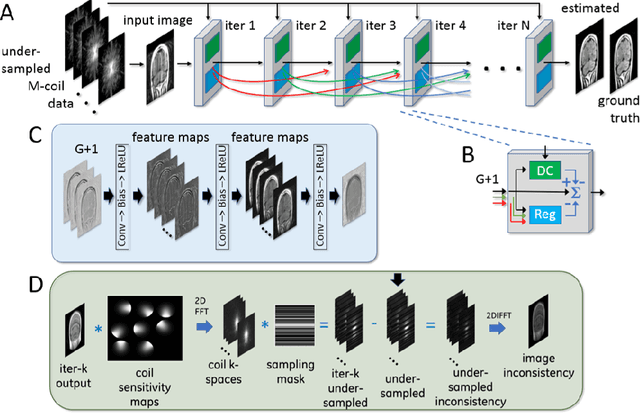
Recent accelerated MRI reconstruction models have used Deep Neural Networks (DNNs) to reconstruct relatively high-quality images from highly undersampled k-space data, enabling much faster MRI scanning. However, these techniques sometimes struggle to reconstruct sharp images that preserve fine detail while maintaining a natural appearance. In this work, we enhance the image quality by using a Conditional Wasserstein Generative Adversarial Network combined with a novel Adaptive Gradient Balancing (AGB) technique that automates the process of combining the adversarial and pixel-wise terms and streamlines hyperparameter tuning. In addition, we introduce a Densely Connected Iterative Network, which is an undersampled MRI reconstruction network that utilizes dense connections. In MRI, our method minimizes artifacts, while maintaining a high-quality reconstruction that produces sharper images than other techniques. To demonstrate the general nature of our method, it is further evaluated on a battery of image-to-image translation experiments, demonstrating an ability to recover from sub-optimal weighting in multi-term adversarial training.