 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing the Parameter Complexity of Hypernetworks and the Embedding-Based Alternative
Paper and Code
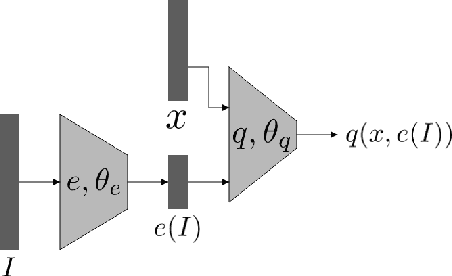
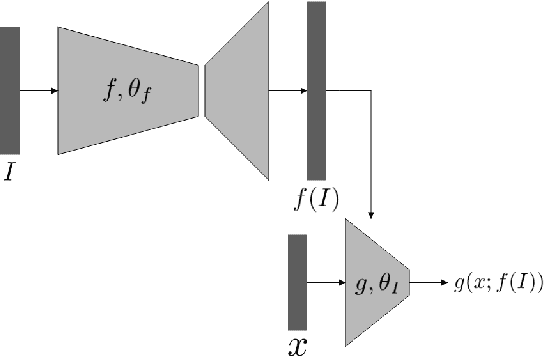
In the context of learning to map an input $I$ to a function $h_I:\mathcal{X}\to \mathbb{R}$, we compare two alternative methods: (i) an embedding-based method, which learns a fixed function in which $I$ is encoded as a conditioning signal $e(I)$ and the learned function takes the form $h_I(x) = q(x,e(I))$, and (ii) hypernetworks, in which the weights $\theta_I$ of the function $h_I(x) = g(x;\theta_I)$ are given by a hypernetwork $f$ as $\theta_I=f(I)$. We extend the theory of~\cite{devore} and provide a lower bound on the complexity of neural networks as function approximators, i.e., the number of trainable parameters. This extension, eliminates the requirements for the approximation method to be robust. Our results are then used to compare the complexities of $q$ and $g$, showing that under certain conditions and when letting the functions $e$ and $f$ be as large as we wish, $g$ can be smaller than $q$ by orders of magnitude. In addition, we show that for typical assumptions on the function to be approximated, the overall number of trainable parameters in a hypernetwork is smaller by orders of magnitude than the number of trainable parameters of a standard neural network and an embedding method.