 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Best Practices for Applying Speech Foundation Models to Speech Intelligibility Prediction for Hearing-Impaired People
May 13, 2025



Speech foundation models (SFMs) have demonstrated strong performance across a variety of downstream tasks, including speech intelligibility prediction for hearing-impaired people (SIP-HI). However, optimizing SFMs for SIP-HI has been insufficiently explored. In this paper, we conduct a comprehensive study to identify key design factors affecting SIP-HI performance with 5 SFMs, focusing on encoder layer selection, prediction head architecture, and ensemble configurations. Our findings show that, contrary to traditional use-all-layers methods, selecting a single encoder layer yields better results. Additionally, temporal modeling is crucial for effective prediction heads. We also demonstrate that ensembling multiple SFMs improves performance, with stronger individual models providing greater benefit. Finally, we explore the relationship between key SFM attributes and their impact on SIP-HI performance. Our study offers practical insights into effectively adapting SFMs for speech intelligibility prediction for hearing-impaired populations.
Chart-RCNN: Efficient Line Chart Data Extraction from Camera Images
Nov 25, 2022Line Chart Data Extraction is a natural extension of Optical Character Recognition where the objective is to recover the underlying numerical information a chart image represents. Some recent works such as ChartOCR approach this problem using multi-stage networks combining OCR models with object detection frameworks. However, most of the existing datasets and models are based on "clean" images such as screenshots that drastically differ from camera photos. In addition, creating domain-specific new datasets requires extensive labeling which can be time-consuming. Our main contributions are as follows: we propose a synthetic data generation framework and a one-stage model that outputs text labels, mark coordinates, and perspective estimation simultaneously. We collected two datasets consisting of real camera photos for evaluation. Results show that our model trained only on synthetic data can be applied to real photos without any fine-tuning and is feasible for real-world application.
Interpreting Audiograms with Multi-stage Neural Networks
Dec 17, 2021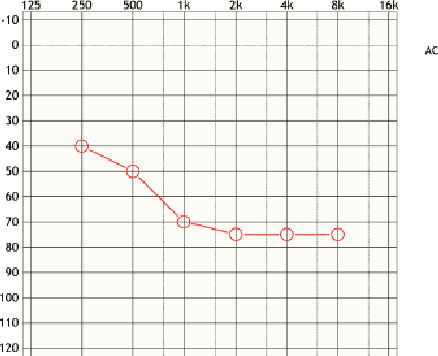
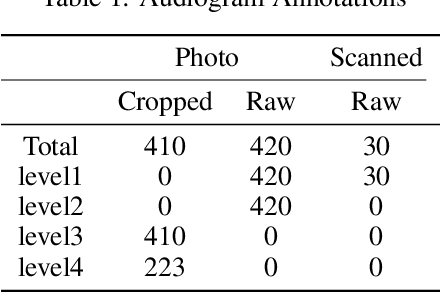

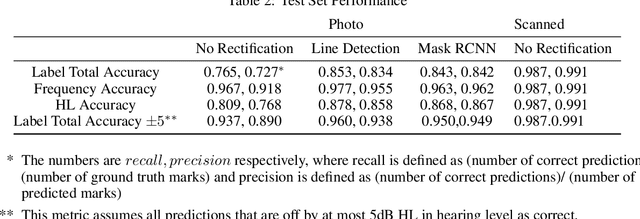
Audiograms are a particular type of line charts representing individuals' hearing level at various frequencies. They are used by audiologists to diagnose hearing loss, and further select and tune appropriate hearing aids for customers. There have been several projects such as Autoaudio that aim to accelerate this process through means of machine learning. But all existing models at their best can only detect audiograms in images and classify them into general categories. They are unable to extract hearing level information from detected audiograms by interpreting the marks, axis, and lines. To address this issue, we propose a Multi-stage Audiogram Interpretation Network (MAIN) that directly reads hearing level data from photos of audiograms. We also established Open Audiogram, an open dataset of audiogram images with annotations of marks and axes on which we trained and evaluated our proposed model. Experiments show that our model is feasible and reliable.