 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Temporal Knowledge Graph Embeddings with Relational and Time Curvatures
Jun 08, 2021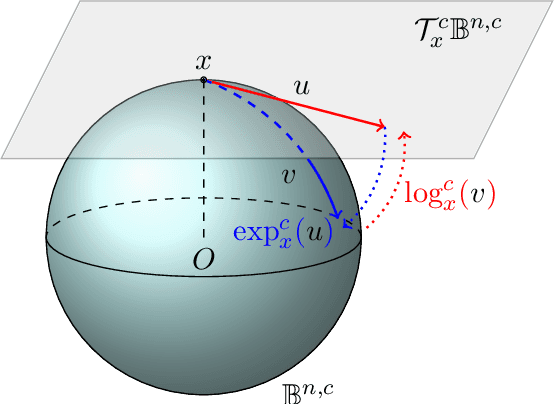


Knowledge Graph (KG) completion has been excessively studied with a massive number of models proposed for the Link Prediction (LP) task. The main limitation of such models is their insensitivity to time. Indeed, the temporal aspect of stored facts is often ignored. To this end, more and more works consider time as a parameter to complete KGs. In this paper, we first demonstrate that, by simply increasing the number of negative samples, the recent AttH model can achieve competitive or even better performance than the state-of-the-art on Temporal KGs (TKGs), albeit its nontemporality. We further propose Hercules, a time-aware extension of AttH model, which defines the curvature of a Riemannian manifold as the product of both relation and time. Our experiments show that both Hercules and AttH achieve competitive or new state-of-the-art performances on ICEWS04 and ICEWS05-15 datasets. Therefore, one should raise awareness when learning TKGs representations to identify whether time truly boosts performances.
Denoising Pre-Training and Data Augmentation Strategies for Enhanced RDF Verbalization with Transformers
Dec 01, 2020
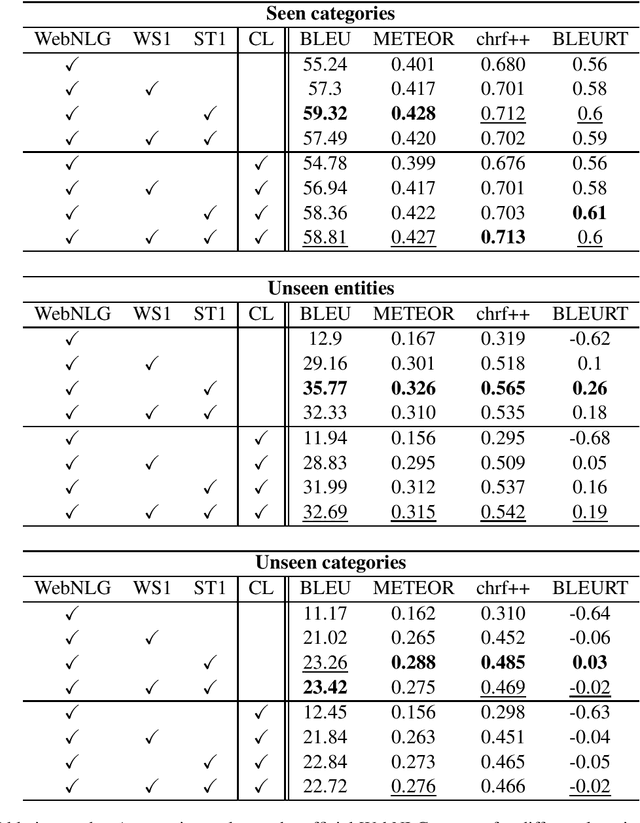
The task of verbalization of RDF triples has known a growth in popularity due to the rising ubiquity of Knowledge Bases (KBs). The formalism of RDF triples is a simple and efficient way to store facts at a large scale. However, its abstract representation makes it difficult for humans to interpret. For this purpose, the WebNLG challenge aims at promoting automated RDF-to-text generation. We propose to leverage pre-trainings from augmented data with the Transformer model using a data augmentation strategy. Our experiment results show a minimum relative increases of 3.73%, 126.05% and 88.16% in BLEU score for seen categories, unseen entities and unseen categories respectively over the standard training.
Addressing Objects and Their Relations: The Conversational Entity Dialogue Model
Jan 05, 2019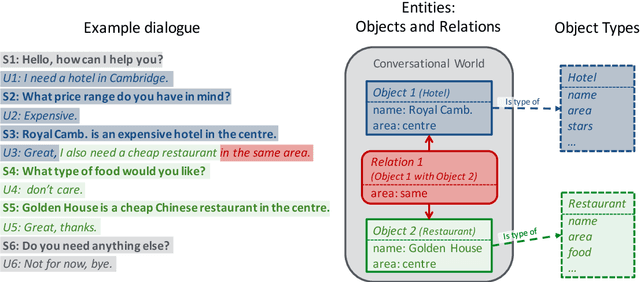
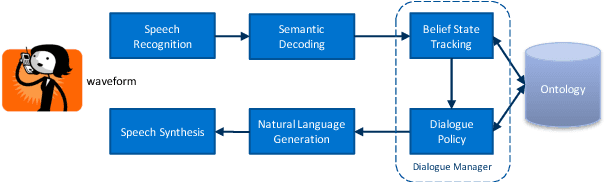
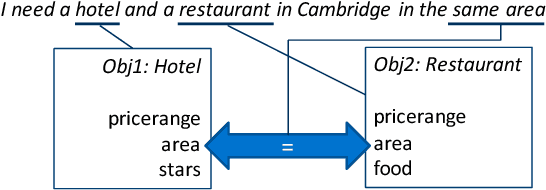

Statistical spoken dialogue systems usually rely on a single- or multi-domain dialogue model that is restricted in its capabilities of modelling complex dialogue structures, e.g., relations. In this work, we propose a novel dialogue model that is centred around entities and is able to model relations as well as multiple entities of the same type. We demonstrate in a prototype implementation benefits of relation modelling on the dialogue level and show that a trained policy using these relations outperforms the multi-domain baseline. Furthermore, we show that by modelling the relations on the dialogue level, the system is capable of processing relations present in the user input and even learns to address them in the system response.
Deep learning for language understanding of mental health concepts derived from Cognitive Behavioural Therapy
Sep 03, 2018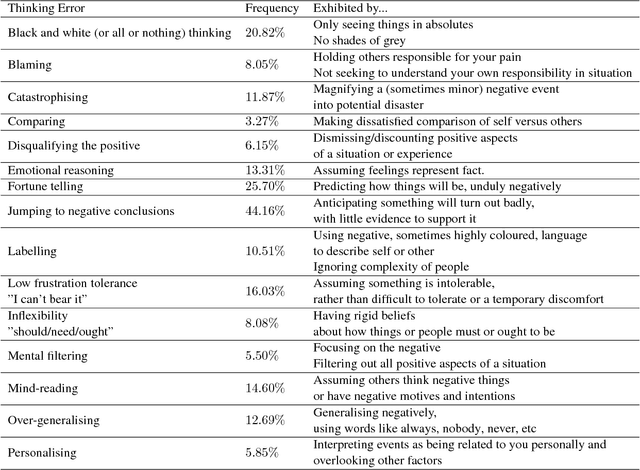
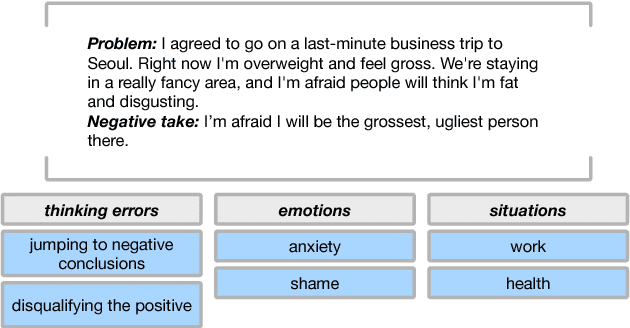
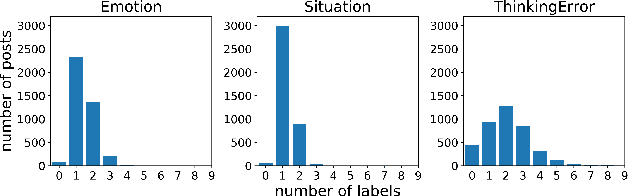

In recent years, we have seen deep learning and distributed representations of words and sentences make impact on a number of natural language processing tasks, such as similarity, entailment and sentiment analysis. Here we introduce a new task: understanding of mental health concepts derived from Cognitive Behavioural Therapy (CBT). We define a mental health ontology based on the CBT principles, annotate a large corpus where this phenomena is exhibited and perform understanding using deep learning and distributed representations. Our results show that the performance of deep learning models combined with word embeddings or sentence embeddings significantly outperform non-deep-learning models in this difficult task. This understanding module will be an essential component of a statistical dialogue system delivering therapy.
A Benchmarking Environment for Reinforcement Learning Based Task Oriented Dialogue Management
Apr 06, 2018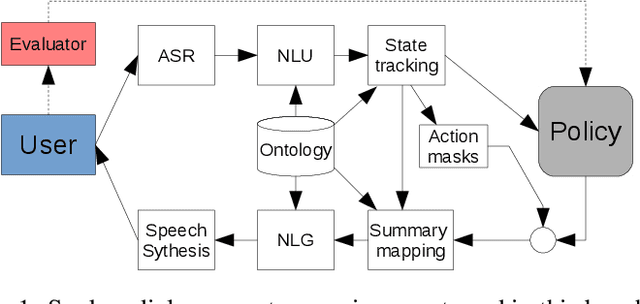
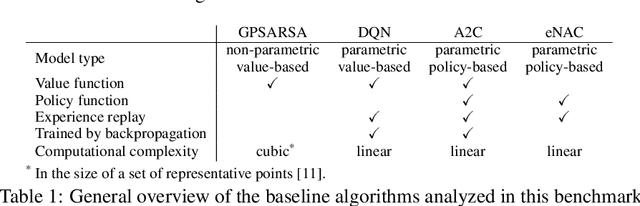

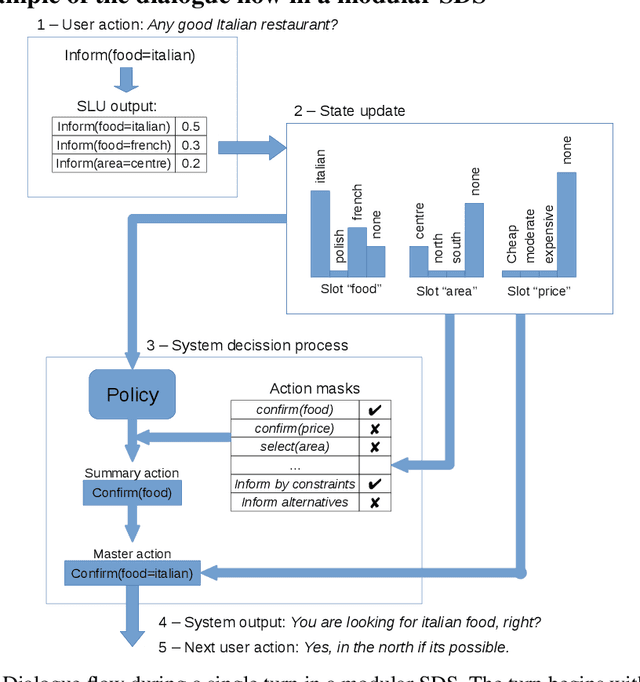
Dialogue assistants are rapidly becoming an indispensable daily aid. To avoid the significant effort needed to hand-craft the required dialogue flow, the Dialogue Management (DM) module can be cast as a continuous Markov Decision Process (MDP) and trained through Reinforcement Learning (RL). Several RL models have been investigated over recent years. However, the lack of a common benchmarking framework makes it difficult to perform a fair comparison between different models and their capability to generalise to different environments. Therefore, this paper proposes a set of challenging simulated environments for dialogue model development and evaluation. To provide some baselines, we investigate a number of representative parametric algorithms, namely deep reinforcement learning algorithms - DQN, A2C and Natural Actor-Critic and compare them to a non-parametric model, GP-SARSA. Both the environments and policy models are implemented using the publicly available PyDial toolkit and released on-line, in order to establish a testbed framework for further experiments and to facilitate experimental reproducibility.
Feudal Reinforcement Learning for Dialogue Management in Large Domains
Mar 08, 2018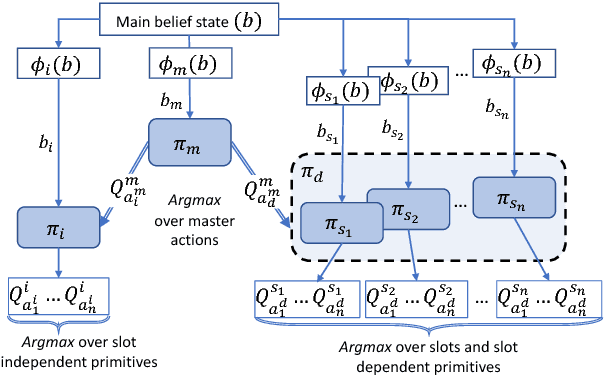
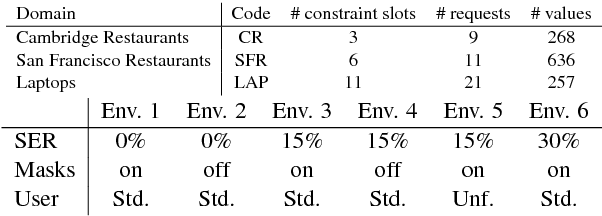
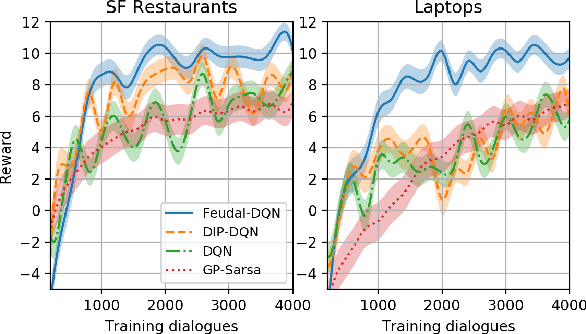
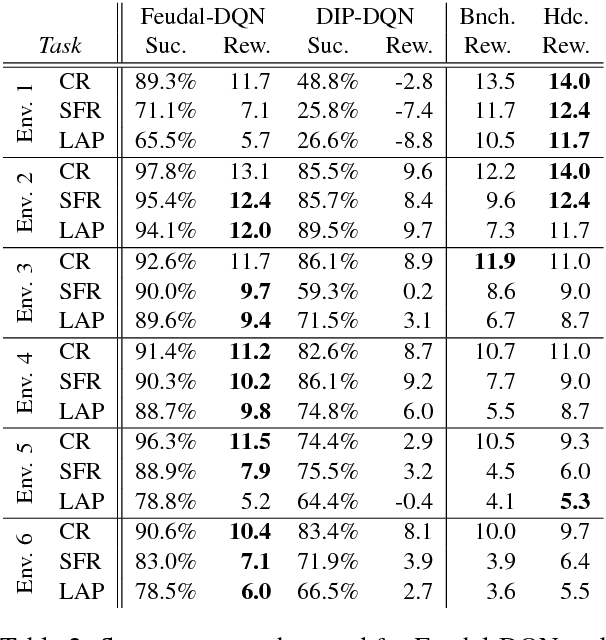
Reinforcement learning (RL) is a promising approach to solve dialogue policy optimisation. Traditional RL algorithms, however, fail to scale to large domains due to the curse of dimensionality. We propose a novel Dialogue Management architecture, based on Feudal RL, which decomposes the decision into two steps; a first step where a master policy selects a subset of primitive actions, and a second step where a primitive action is chosen from the selected subset. The structural information included in the domain ontology is used to abstract the dialogue state space, taking the decisions at each step using different parts of the abstracted state. This, combined with an information sharing mechanism between slots, increases the scalability to large domains. We show that an implementation of this approach, based on Deep-Q Networks, significantly outperforms previous state of the art in several dialogue domains and environments, without the need of any additional reward signal.
Reward-Balancing for Statistical Spoken Dialogue Systems using Multi-objective Reinforcement Learning
Jul 19, 2017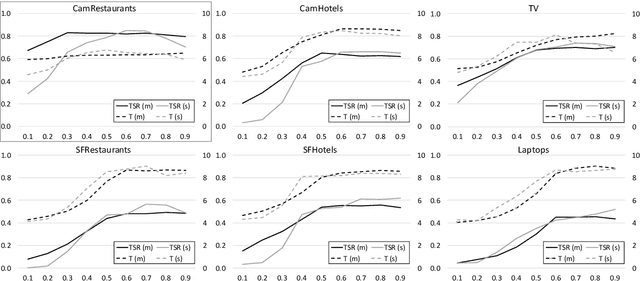
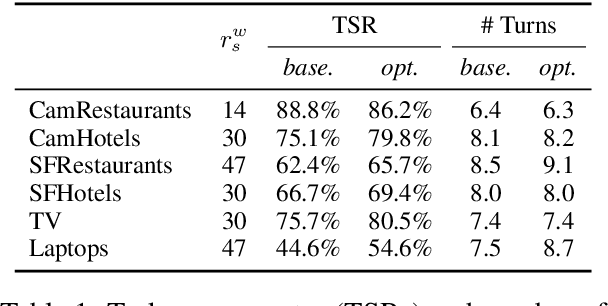
Reinforcement learning is widely used for dialogue policy optimization where the reward function often consists of more than one component, e.g., the dialogue success and the dialogue length. In this work, we propose a structured method for finding a good balance between these components by searching for the optimal reward component weighting. To render this search feasible, we use multi-objective reinforcement learning to significantly reduce the number of training dialogues required. We apply our proposed method to find optimized component weights for six domains and compare them to a default baseline.
Sub-domain Modelling for Dialogue Management with Hierarchical Reinforcement Learning
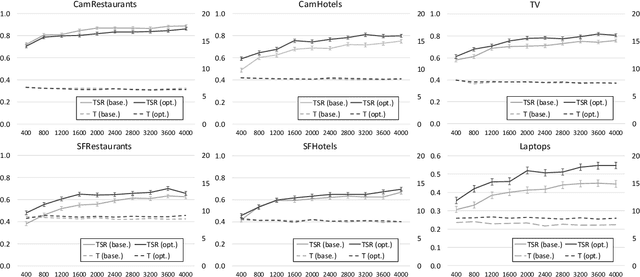
Jul 17, 2017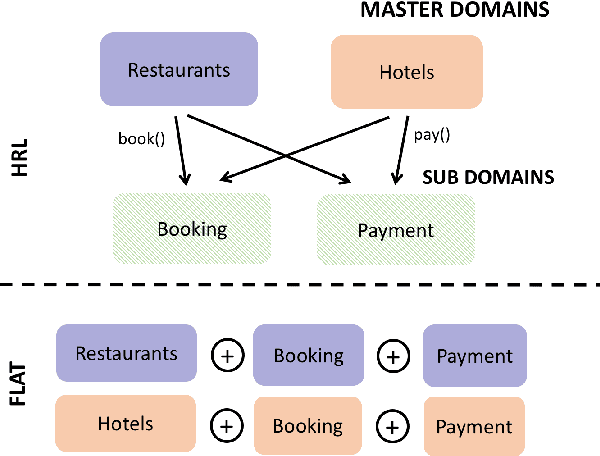
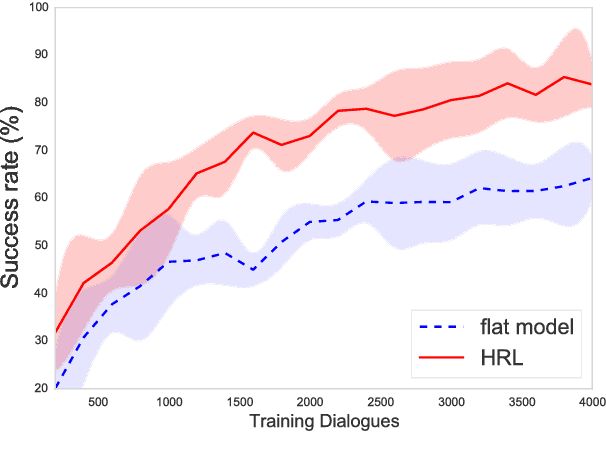
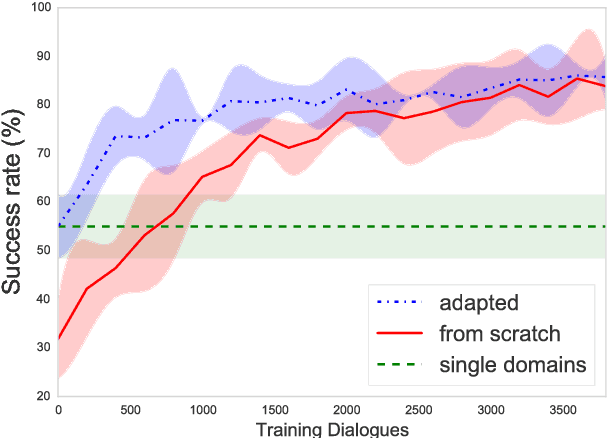

Human conversation is inherently complex, often spanning many different topics/domains. This makes policy learning for dialogue systems very challenging. Standard flat reinforcement learning methods do not provide an efficient framework for modelling such dialogues. In this paper, we focus on the under-explored problem of multi-domain dialogue management. First, we propose a new method for hierarchical reinforcement learning using the option framework. Next, we show that the proposed architecture learns faster and arrives at a better policy than the existing flat ones do. Moreover, we show how pretrained policies can be adapted to more complex systems with an additional set of new actions. In doing that, we show that our approach has the potential to facilitate policy optimisation for more sophisticated multi-domain dialogue systems.
Continuously Learning Neural Dialogue Management
Jun 08, 2016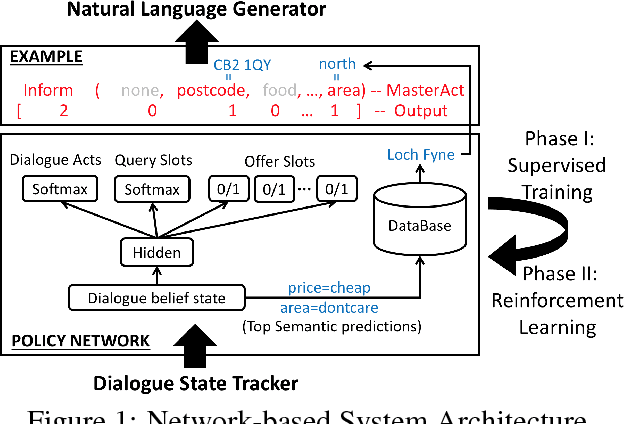

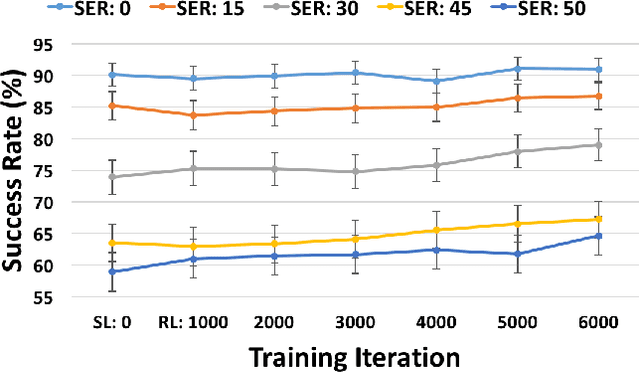

We describe a two-step approach for dialogue management in task-oriented spoken dialogue systems. A unified neural network framework is proposed to enable the system to first learn by supervision from a set of dialogue data and then continuously improve its behaviour via reinforcement learning, all using gradient-based algorithms on one single model. The experiments demonstrate the supervised model's effectiveness in the corpus-based evaluation, with user simulation, and with paid human subjects. The use of reinforcement learning further improves the model's performance in both interactive settings, especially under higher-noise conditions.
On-line Active Reward Learning for Policy Optimisation in Spoken Dialogue Systems
Jun 02, 2016
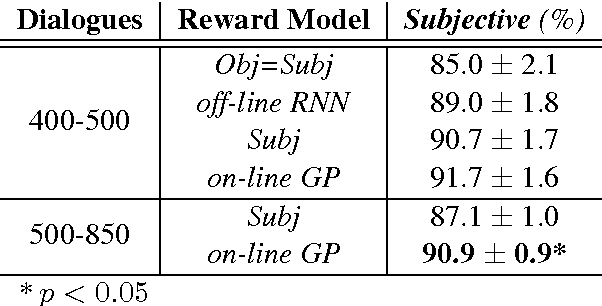
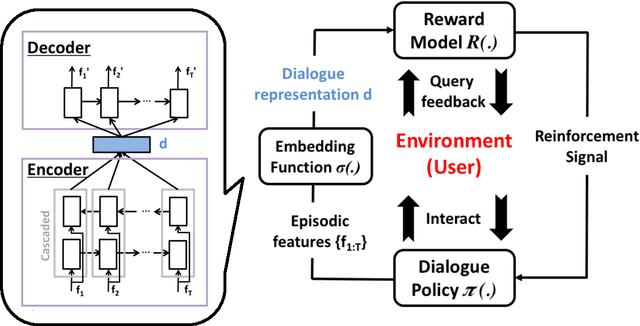
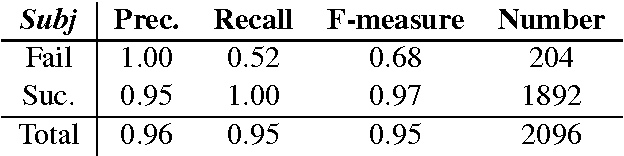
The ability to compute an accurate reward function is essential for optimising a dialogue policy via reinforcement learning. In real-world applications, using explicit user feedback as the reward signal is often unreliable and costly to collect. This problem can be mitigated if the user's intent is known in advance or data is available to pre-train a task success predictor off-line. In practice neither of these apply for most real world applications. Here we propose an on-line learning framework whereby the dialogue policy is jointly trained alongside the reward model via active learning with a Gaussian process model. This Gaussian process operates on a continuous space dialogue representation generated in an unsupervised fashion using a recurrent neural network encoder-decoder. The experimental results demonstrate that the proposed framework is able to significantly reduce data annotation costs and mitigate noisy user feedback in dialogue policy learning.