 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasures of Distributional Similarity
Jan 18, 2000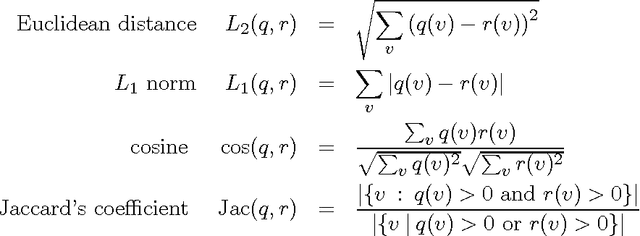

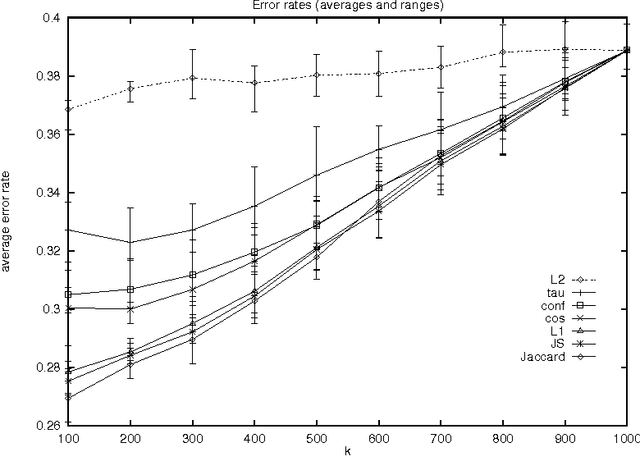
We study distributional similarity measures for the purpose of improving probability estimation for unseen cooccurrences. Our contributions are three-fold: an empirical comparison of a broad range of measures; a classification of similarity functions based on the information that they incorporate; and the introduction of a novel function that is superior at evaluating potential proxy distributions.
* 9 pages, 3 figures
Similarity-Based Models of Word Cooccurrence Probabilities
Sep 27, 1998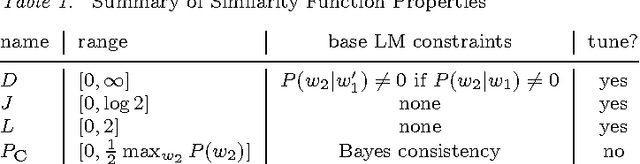
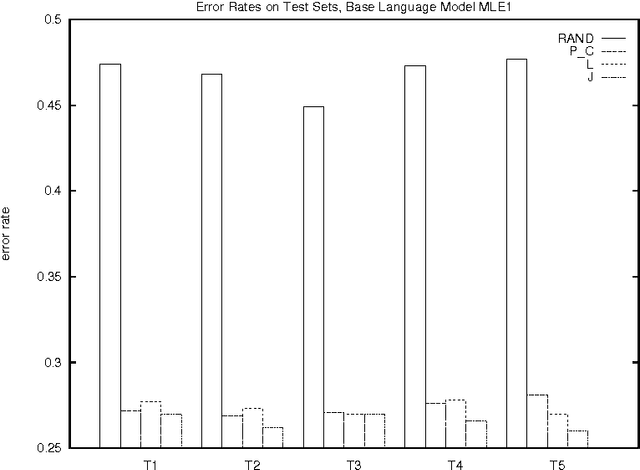

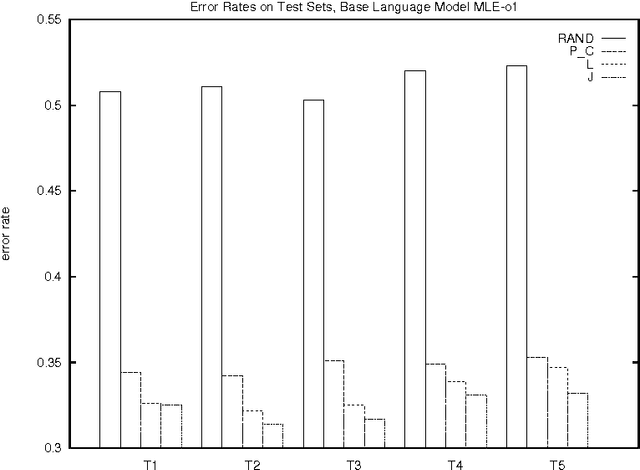
In many applications of natural language processing (NLP) it is necessary to determine the likelihood of a given word combination. For example, a speech recognizer may need to determine which of the two word combinations ``eat a peach'' and ``eat a beach'' is more likely. Statistical NLP methods determine the likelihood of a word combination from its frequency in a training corpus. However, the nature of language is such that many word combinations are infrequent and do not occur in any given corpus. In this work we propose a method for estimating the probability of such previously unseen word combinations using available information on ``most similar'' words. We describe probabilistic word association models based on distributional word similarity, and apply them to two tasks, language modeling and pseudo-word disambiguation. In the language modeling task, a similarity-based model is used to improve probability estimates for unseen bigrams in a back-off language model. The similarity-based method yields a 20% perplexity improvement in the prediction of unseen bigrams and statistically significant reductions in speech-recognition error. We also compare four similarity-based estimation methods against back-off and maximum-likelihood estimation methods on a pseudo-word sense disambiguation task in which we controlled for both unigram and bigram frequency to avoid giving too much weight to easy-to-disambiguate high-frequency configurations. The similarity-based methods perform up to 40% better on this particular task.
* 26 pages, 5 figures
Similarity-Based Approaches to Natural Language Processing
Aug 19, 1997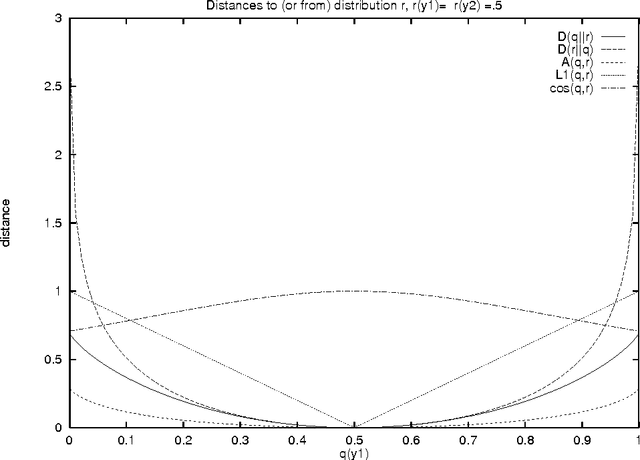

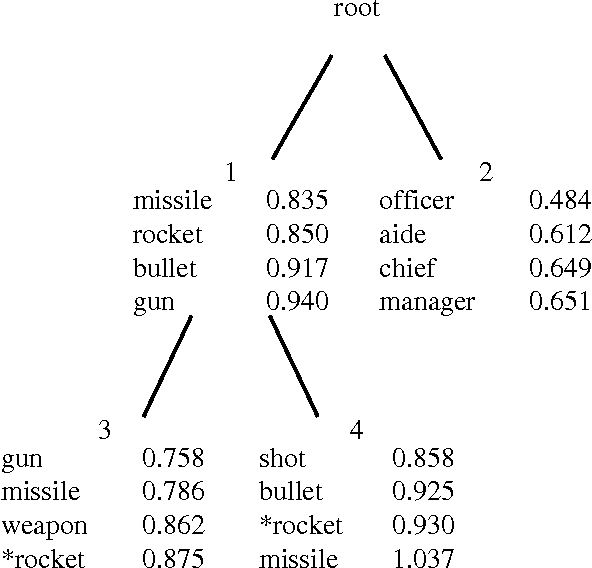
This thesis presents two similarity-based approaches to sparse data problems. The first approach is to build soft, hierarchical clusters: soft, because each event belongs to each cluster with some probability; hierarchical, because cluster centroids are iteratively split to model finer distinctions. Our second approach is a nearest-neighbor approach: instead of calculating a centroid for each class, as in the hierarchical clustering approach, we in essence build a cluster around each word. We compare several such nearest-neighbor approaches on a word sense disambiguation task and find that as a whole, their performance is far superior to that of standard methods. In another set of experiments, we show that using estimation techniques based on the nearest-neighbor model enables us to achieve perplexity reductions of more than 20 percent over standard techniques in the prediction of low-frequency events, and statistically significant speech recognition error-rate reduction.
Similarity-Based Methods For Word Sense Disambiguation
Aug 18, 1997
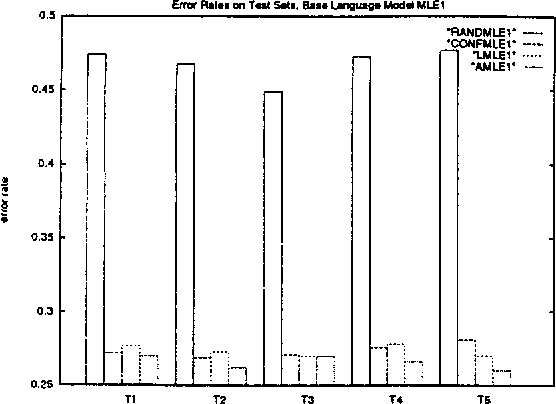
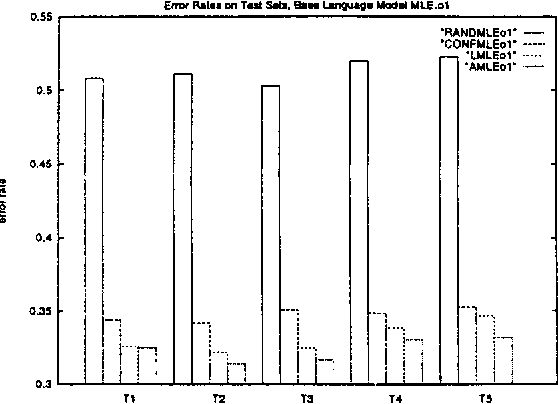
We compare four similarity-based estimation methods against back-off and maximum-likelihood estimation methods on a pseudo-word sense disambiguation task in which we controlled for both unigram and bigram frequency. The similarity-based methods perform up to 40% better on this particular task. We also conclude that events that occur only once in the training set have major impact on similarity-based estimates.
* 7 pages, uses psfig.tex and aclap.sty
Fast Context-Free Parsing Requires Fast Boolean Matrix Multiplication
Aug 14, 1997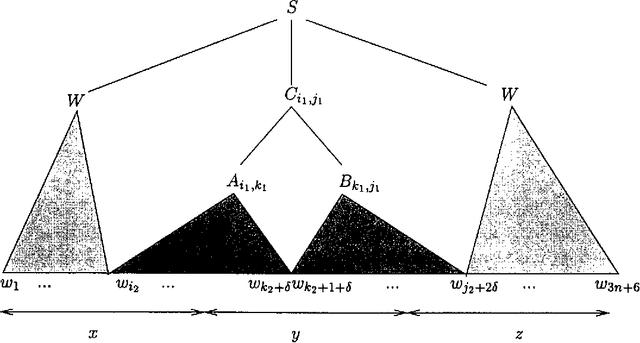
Valiant showed that Boolean matrix multiplication (BMM) can be used for CFG parsing. We prove a dual result: CFG parsers running in time $O(|G||w|^{3 - \myeps})$ on a grammar $G$ and a string $w$ can be used to multiply $m \times m$ Boolean matrices in time $O(m^{3 - \myeps/3})$. In the process we also provide a formal definition of parsing motivated by an informal notion due to Lang. Our result establishes one of the first limitations on general CFG parsing: a fast, practical CFG parser would yield a fast, practical BMM algorithm, which is not believed to exist.
* 6 pages, uses aclap.sty and eepic.sty
Distributional Clustering of English Words
Aug 22, 1994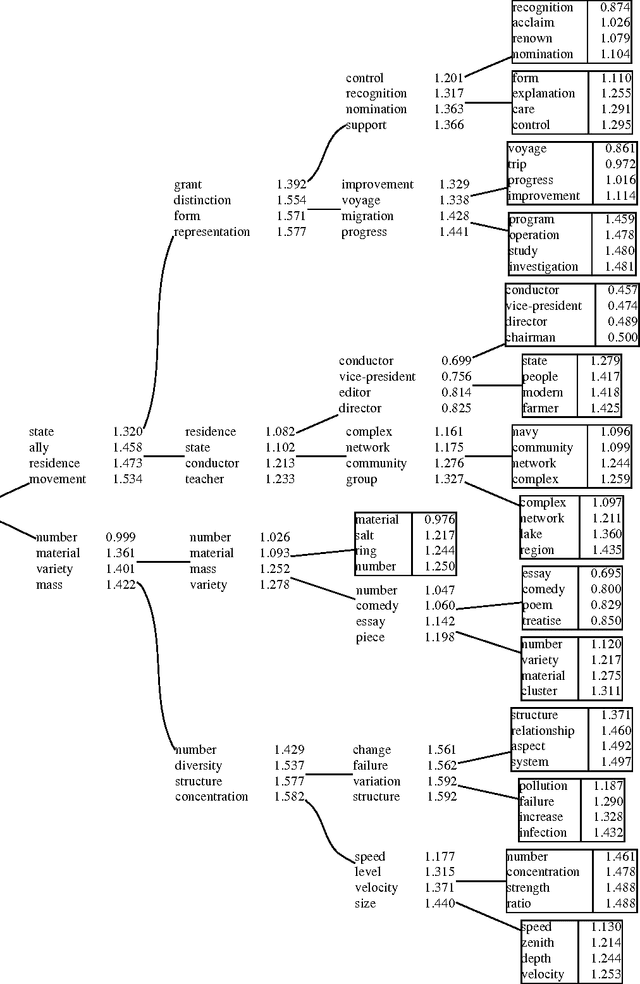
We describe and experimentally evaluate a method for automatically clustering words according to their distribution in particular syntactic contexts. Deterministic annealing is used to find lowest distortion sets of clusters. As the annealing parameter increases, existing clusters become unstable and subdivide, yielding a hierarchical ``soft'' clustering of the data. Clusters are used as the basis for class models of word coocurrence, and the models evaluated with respect to held-out test data.
Similarity-Based Estimation of Word Cooccurrence Probabilities
May 02, 1994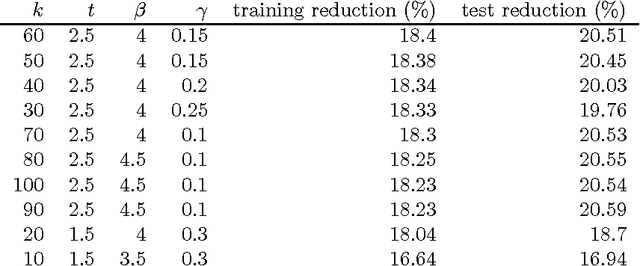

In many applications of natural language processing it is necessary to determine the likelihood of a given word combination. For example, a speech recognizer may need to determine which of the two word combinations ``eat a peach'' and ``eat a beach'' is more likely. Statistical NLP methods determine the likelihood of a word combination according to its frequency in a training corpus. However, the nature of language is such that many word combinations are infrequent and do not occur in a given corpus. In this work we propose a method for estimating the probability of such previously unseen word combinations using available information on ``most similar'' words. We describe a probabilistic word association model based on distributional word similarity, and apply it to improving probability estimates for unseen word bigrams in a variant of Katz's back-off model. The similarity-based method yields a 20% perplexity improvement in the prediction of unseen bigrams and statistically significant reductions in speech-recognition error.