 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts
Sep 29, 2004Sentiment analysis seeks to identify the viewpoint(s) underlying a text span; an example application is classifying a movie review as "thumbs up" or "thumbs down". To determine this sentiment polarity, we propose a novel machine-learning method that applies text-categorization techniques to just the subjective portions of the document. Extracting these portions can be implemented using efficient techniques for finding minimum cuts in graphs; this greatly facilitates incorporation of cross-sentence contextual constraints.
* Data available at http://www.cs.cornell.edu/people/pabo/movie-review-data/
Corpus structure, language models, and ad hoc information retrieval
May 12, 2004

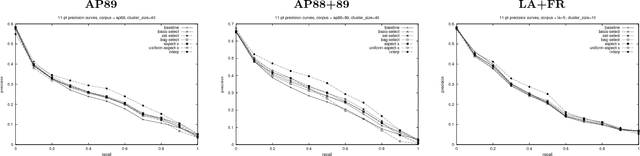

Most previous work on the recently developed language-modeling approach to information retrieval focuses on document-specific characteristics, and therefore does not take into account the structure of the surrounding corpus. We propose a novel algorithmic framework in which information provided by document-based language models is enhanced by the incorporation of information drawn from clusters of similar documents. Using this framework, we develop a suite of new algorithms. Even the simplest typically outperforms the standard language-modeling approach in precision and recall, and our new interpolation algorithm posts statistically significant improvements for both metrics over all three corpora tested.
Catching the Drift: Probabilistic Content Models, with Applications to Generation and Summarization
May 12, 2004
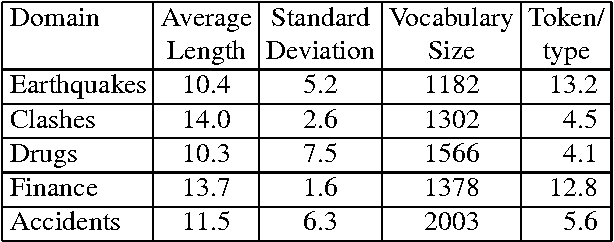
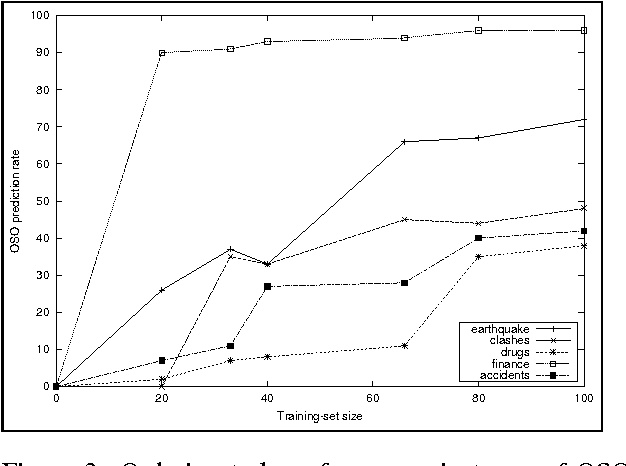
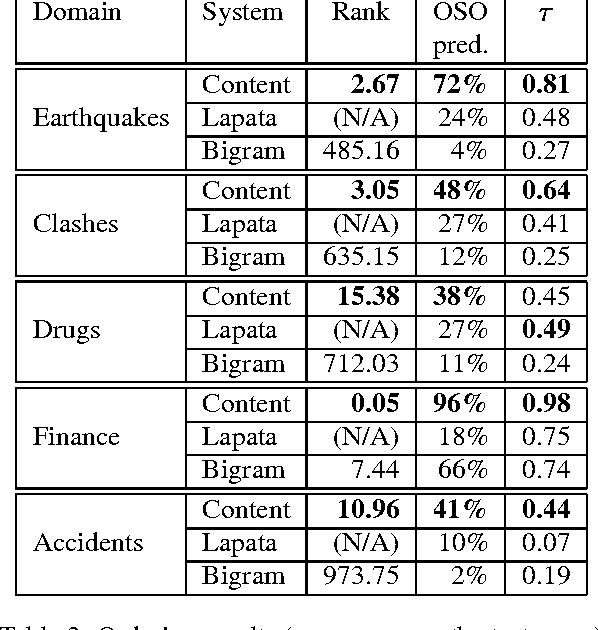
We consider the problem of modeling the content structure of texts within a specific domain, in terms of the topics the texts address and the order in which these topics appear. We first present an effective knowledge-lean method for learning content models from un-annotated documents, utilizing a novel adaptation of algorithms for Hidden Markov Models. We then apply our method to two complementary tasks: information ordering and extractive summarization. Our experiments show that incorporating content models in these applications yields substantial improvement over previously-proposed methods.
* Best paper award
"I'm sorry Dave, I'm afraid I can't do that": Linguistics, Statistics, and Natural Language Processing circa 2001
Apr 21, 2003A brief, general-audience overview of the history of natural language processing, focusing on data-driven approaches.Topics include "Ambiguity and language analysis", "Firth things first", "A 'C' change", and "The empiricists strike back".
* To appear, National Research Council study on the Fundamentals of Computer Science. 7 pages
Learning to Paraphrase: An Unsupervised Approach Using Multiple-Sequence Alignment
Apr 02, 2003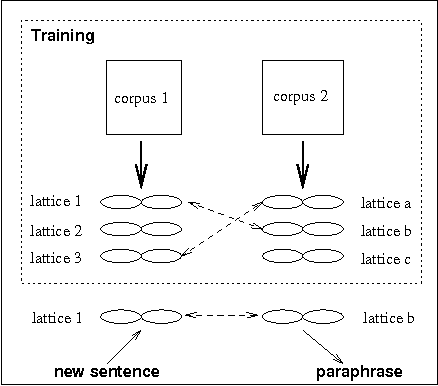



We address the text-to-text generation problem of sentence-level paraphrasing -- a phenomenon distinct from and more difficult than word- or phrase-level paraphrasing. Our approach applies multiple-sequence alignment to sentences gathered from unannotated comparable corpora: it learns a set of paraphrasing patterns represented by word lattice pairs and automatically determines how to apply these patterns to rewrite new sentences. The results of our evaluation experiments show that the system derives accurate paraphrases, outperforming baseline systems.
Thumbs up? Sentiment Classification using Machine Learning Techniques
May 28, 2002

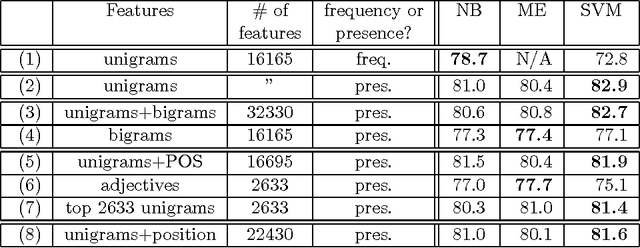
We consider the problem of classifying documents not by topic, but by overall sentiment, e.g., determining whether a review is positive or negative. Using movie reviews as data, we find that standard machine learning techniques definitively outperform human-produced baselines. However, the three machine learning methods we employed (Naive Bayes, maximum entropy classification, and support vector machines) do not perform as well on sentiment classification as on traditional topic-based categorization. We conclude by examining factors that make the sentiment classification problem more challenging.
Bootstrapping Lexical Choice via Multiple-Sequence Alignment
May 25, 2002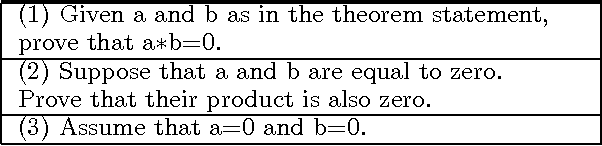
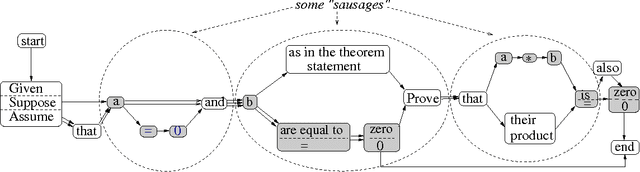
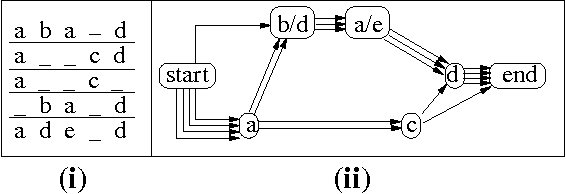
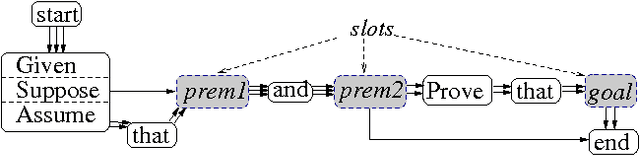
An important component of any generation system is the mapping dictionary, a lexicon of elementary semantic expressions and corresponding natural language realizations. Typically, labor-intensive knowledge-based methods are used to construct the dictionary. We instead propose to acquire it automatically via a novel multiple-pass algorithm employing multiple-sequence alignment, a technique commonly used in bioinformatics. Crucially, our method leverages latent information contained in multi-parallel corpora -- datasets that supply several verbalizations of the corresponding semantics rather than just one. We used our techniques to generate natural language versions of computer-generated mathematical proofs, with good results on both a per-component and overall-output basis. For example, in evaluations involving a dozen human judges, our system produced output whose readability and faithfulness to the semantic input rivaled that of a traditional generation system.
Mostly-Unsupervised Statistical Segmentation of Japanese Kanji Sequences
May 10, 2002
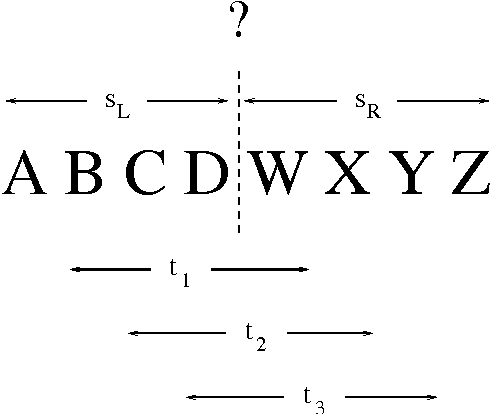
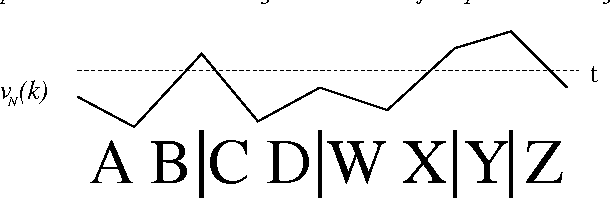
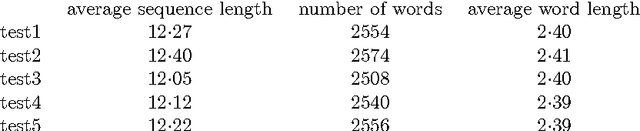
Given the lack of word delimiters in written Japanese, word segmentation is generally considered a crucial first step in processing Japanese texts. Typical Japanese segmentation algorithms rely either on a lexicon and syntactic analysis or on pre-segmented data; but these are labor-intensive, and the lexico-syntactic techniques are vulnerable to the unknown word problem. In contrast, we introduce a novel, more robust statistical method utilizing unsegmented training data. Despite its simplicity, the algorithm yields performance on long kanji sequences comparable to and sometimes surpassing that of state-of-the-art morphological analyzers over a variety of error metrics. The algorithm also outperforms another mostly-unsupervised statistical algorithm previously proposed for Chinese. Additionally, we present a two-level annotation scheme for Japanese to incorporate multiple segmentation granularities, and introduce two novel evaluation metrics, both based on the notion of a compatible bracket, that can account for multiple granularities simultaneously.
* 22 pages. To appear in Natural Language Engineering
Fast Context-Free Grammar Parsing Requires Fast Boolean Matrix Multiplication
Dec 15, 2001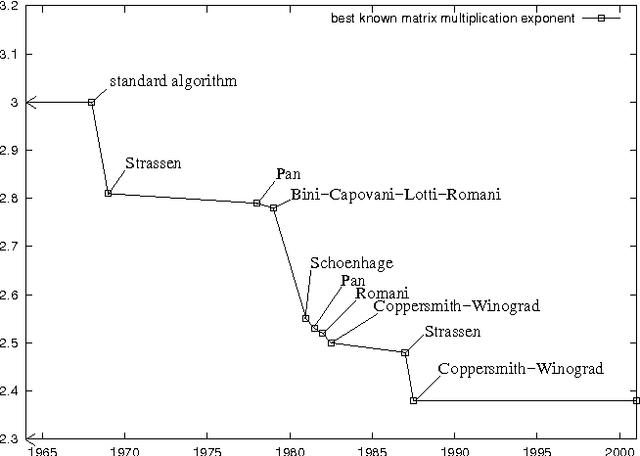
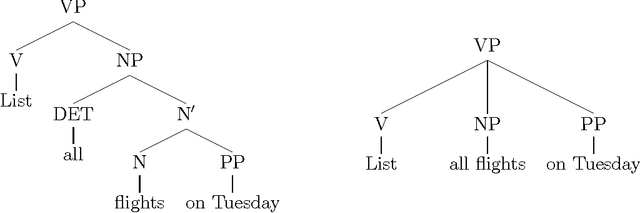
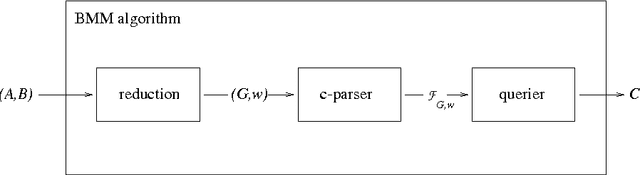
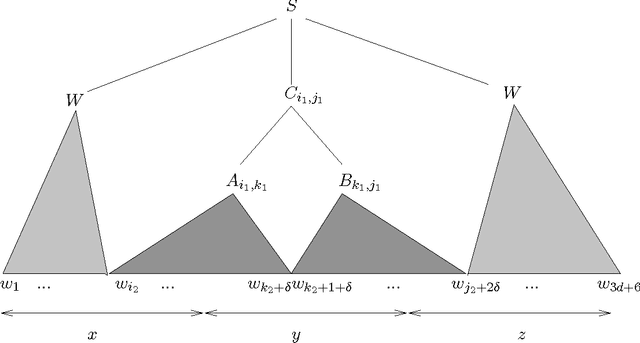
In 1975, Valiant showed that Boolean matrix multiplication can be used for parsing context-free grammars (CFGs), yielding the asympotically fastest (although not practical) CFG parsing algorithm known. We prove a dual result: any CFG parser with time complexity $O(g n^{3 - \epsilson})$, where $g$ is the size of the grammar and $n$ is the length of the input string, can be efficiently converted into an algorithm to multiply $m \times m$ Boolean matrices in time $O(m^{3 - \epsilon/3})$. Given that practical, substantially sub-cubic Boolean matrix multiplication algorithms have been quite difficult to find, we thus explain why there has been little progress in developing practical, substantially sub-cubic general CFG parsers. In proving this result, we also develop a formalization of the notion of parsing.
* To appear in Journal of the ACM
Iterative Residual Rescaling: An Analysis and Generalization of LSI
Jun 17, 2001We consider the problem of creating document representations in which inter-document similarity measurements correspond to semantic similarity. We first present a novel subspace-based framework for formalizing this task. Using this framework, we derive a new analysis of Latent Semantic Indexing (LSI), showing a precise relationship between its performance and the uniformity of the underlying distribution of documents over topics. This analysis helps explain the improvements gained by Ando's (2000) Iterative Residual Rescaling (IRR) algorithm: IRR can compensate for distributional non-uniformity. A further benefit of our framework is that it provides a well-motivated, effective method for automatically determining the rescaling factor IRR depends on, leading to further improvements. A series of experiments over various settings and with several evaluation metrics validates our claims.
* To appear in the proceedings of SIGIR 2001. 11 pages