 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't 'have a clue'? Unsupervised co-learning of downward-entailing operators
Nov 27, 2010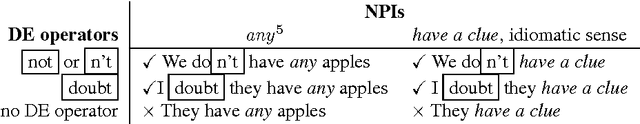
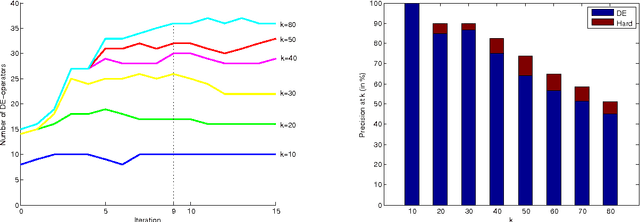
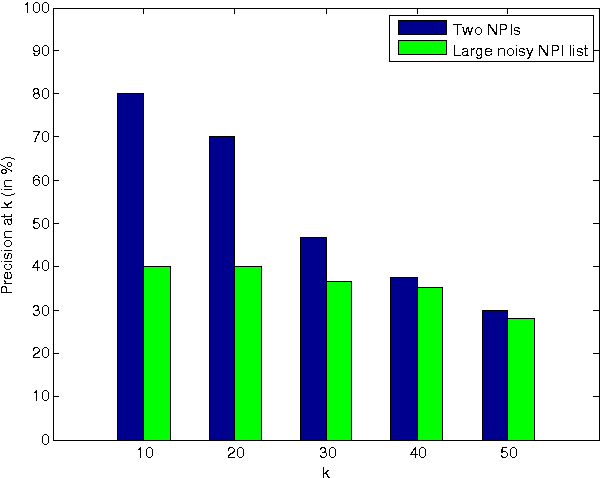
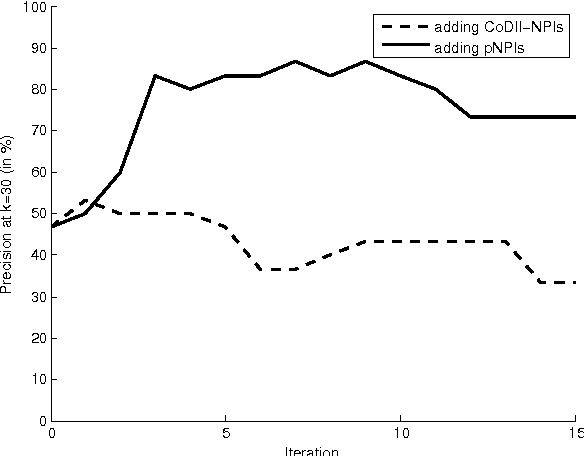
Researchers in textual entailment have begun to consider inferences involving 'downward-entailing operators', an interesting and important class of lexical items that change the way inferences are made. Recent work proposed a method for learning English downward-entailing operators that requires access to a high-quality collection of 'negative polarity items' (NPIs). However, English is one of the very few languages for which such a list exists. We propose the first approach that can be applied to the many languages for which there is no pre-existing high-precision database of NPIs. As a case study, we apply our method to Romanian and show that our method yields good results. Also, we perform a cross-linguistic analysis that suggests interesting connections to some findings in linguistic typology.
* pp 1-6 are identical to the ACL 2010 published version; pp. 7-8 are the "externally-available appendices". Revision contains an additional appendix correcting the origin of the term "pseudo-polarity item"
For the sake of simplicity: Unsupervised extraction of lexical simplifications from Wikipedia
Aug 11, 2010We report on work in progress on extracting lexical simplifications (e.g., "collaborate" -> "work together"), focusing on utilizing edit histories in Simple English Wikipedia for this task. We consider two main approaches: (1) deriving simplification probabilities via an edit model that accounts for a mixture of different operations, and (2) using metadata to focus on edits that are more likely to be simplification operations. We find our methods to outperform a reasonable baseline and yield many high-quality lexical simplifications not included in an independently-created manually prepared list.
* 4 pp; data available at http://www.cs.cornell.edu/home/llee/data/simple/
How opinions are received by online communities: A case study on Amazon.com helpfulness votes
Jun 21, 2009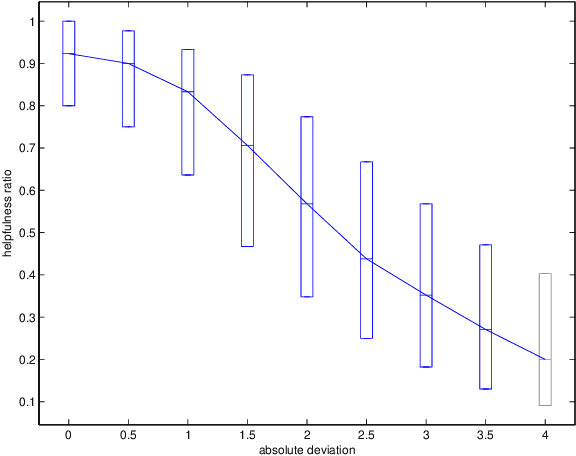
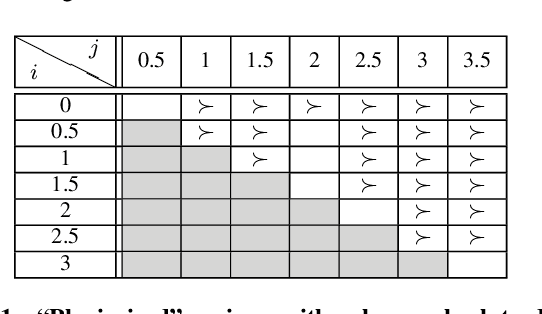
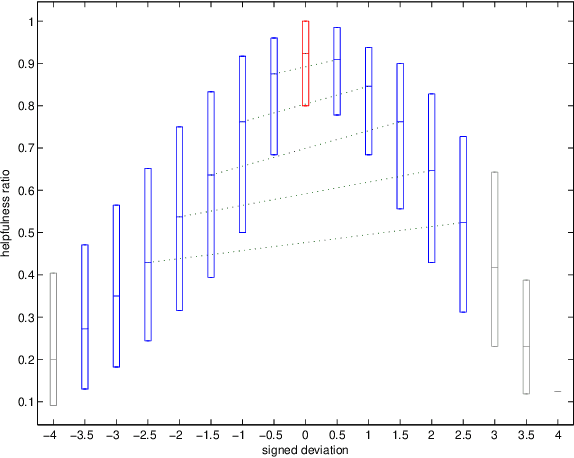
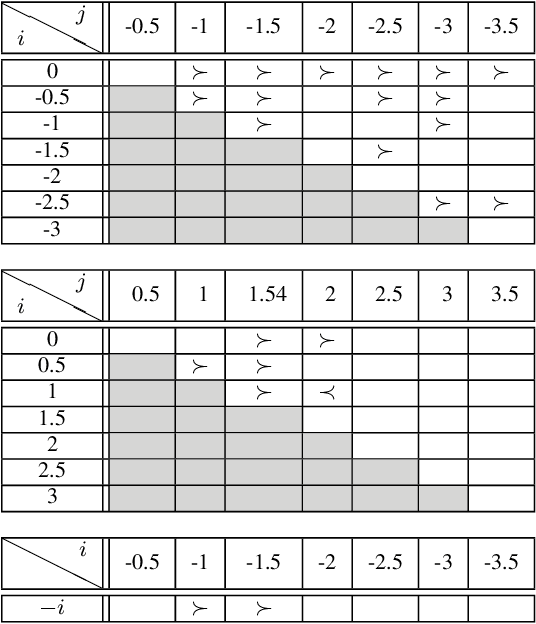
There are many on-line settings in which users publicly express opinions. A number of these offer mechanisms for other users to evaluate these opinions; a canonical example is Amazon.com, where reviews come with annotations like "26 of 32 people found the following review helpful." Opinion evaluation appears in many off-line settings as well, including market research and political campaigns. Reasoning about the evaluation of an opinion is fundamentally different from reasoning about the opinion itself: rather than asking, "What did Y think of X?", we are asking, "What did Z think of Y's opinion of X?" Here we develop a framework for analyzing and modeling opinion evaluation, using a large-scale collection of Amazon book reviews as a dataset. We find that the perceived helpfulness of a review depends not just on its content but also but also in subtle ways on how the expressed evaluation relates to other evaluations of the same product. As part of our approach, we develop novel methods that take advantage of the phenomenon of review "plagiarism" to control for the effects of text in opinion evaluation, and we provide a simple and natural mathematical model consistent with our findings. Our analysis also allows us to distinguish among the predictions of competing theories from sociology and social psychology, and to discover unexpected differences in the collective opinion-evaluation behavior of user populations from different countries.
Without a 'doubt'? Unsupervised discovery of downward-entailing operators
Jun 12, 2009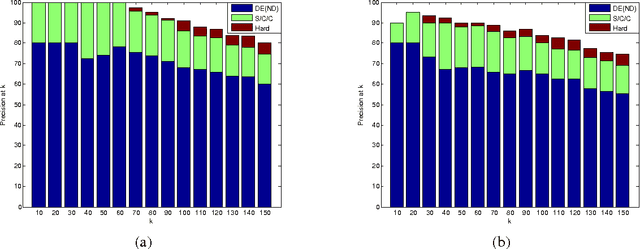


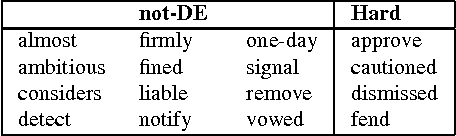
An important part of textual inference is making deductions involving monotonicity, that is, determining whether a given assertion entails restrictions or relaxations of that assertion. For instance, the statement 'We know the epidemic spread quickly' does not entail 'We know the epidemic spread quickly via fleas', but 'We doubt the epidemic spread quickly' entails 'We doubt the epidemic spread quickly via fleas'. Here, we present the first algorithm for the challenging lexical-semantics problem of learning linguistic constructions that, like 'doubt', are downward entailing (DE). Our algorithm is unsupervised, resource-lean, and effective, accurately recovering many DE operators that are missing from the hand-constructed lists that textual-inference systems currently use.
* System output available at http://www.cs.cornell.edu/~cristian/Without_a_doubt_-_Data.html
Respect My Authority! HITS Without Hyperlinks, Utilizing Cluster-Based Language Models
Apr 22, 2008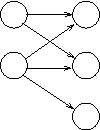

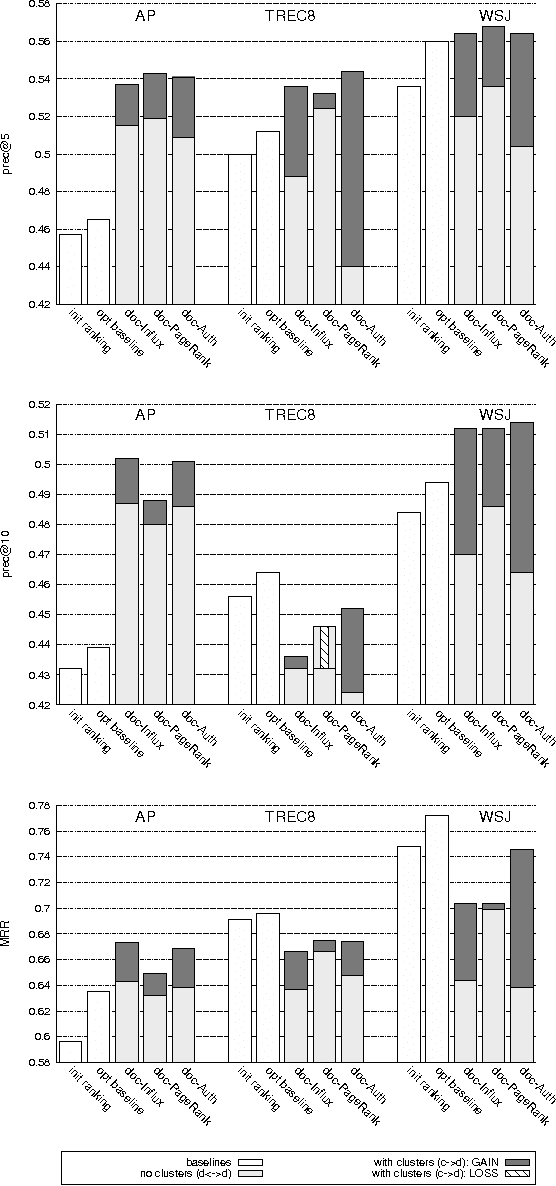
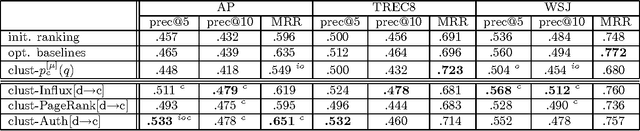
We present an approach to improving the precision of an initial document ranking wherein we utilize cluster information within a graph-based framework. The main idea is to perform re-ranking based on centrality within bipartite graphs of documents (on one side) and clusters (on the other side), on the premise that these are mutually reinforcing entities. Links between entities are created via consideration of language models induced from them. We find that our cluster-document graphs give rise to much better retrieval performance than previously proposed document-only graphs do. For example, authority-based re-ranking of documents via a HITS-style cluster-based approach outperforms a previously-proposed PageRank-inspired algorithm applied to solely-document graphs. Moreover, we also show that computing authority scores for clusters constitutes an effective method for identifying clusters containing a large percentage of relevant documents.
IDF revisited: A simple new derivation within the Robertson-Spärck Jones probabilistic model
May 08, 2007There have been a number of prior attempts to theoretically justify the effectiveness of the inverse document frequency (IDF). Those that take as their starting point Robertson and Sparck Jones's probabilistic model are based on strong or complex assumptions. We show that a more intuitively plausible assumption suffices. Moreover, the new assumption, while conceptually very simple, provides a solution to an estimation problem that had been deemed intractable by Robertson and Walker (1997).
Better than the real thing? Iterative pseudo-query processing using cluster-based language models
Jan 11, 2006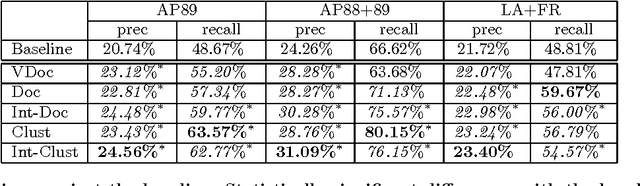
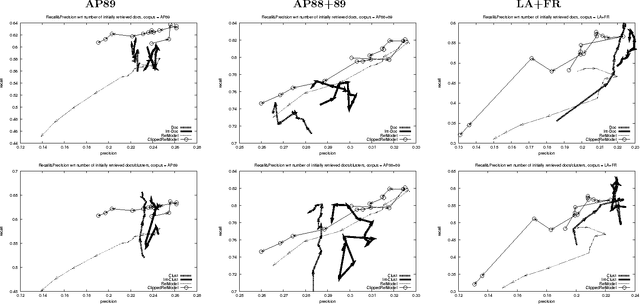
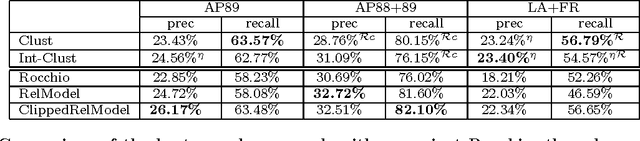
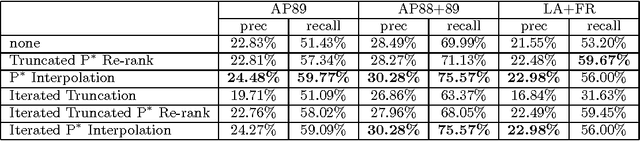
We present a novel approach to pseudo-feedback-based ad hoc retrieval that uses language models induced from both documents and clusters. First, we treat the pseudo-feedback documents produced in response to the original query as a set of pseudo-queries that themselves can serve as input to the retrieval process. Observing that the documents returned in response to the pseudo-queries can then act as pseudo-queries for subsequent rounds, we arrive at a formulation of pseudo-query-based retrieval as an iterative process. Experiments show that several concrete instantiations of this idea, when applied in conjunction with techniques designed to heighten precision, yield performance results rivaling those of a number of previously-proposed algorithms, including the standard language-modeling approach. The use of cluster-based language models is a key contributing factor to our algorithms' success.
PageRank without hyperlinks: Structural re-ranking using links induced by language models
Jan 11, 2006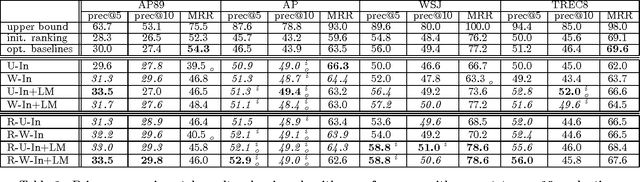
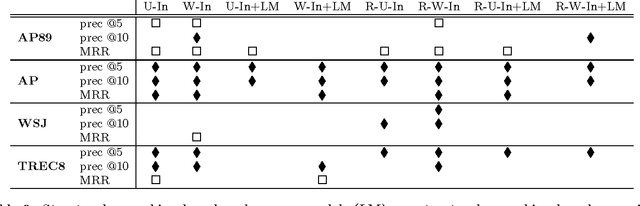
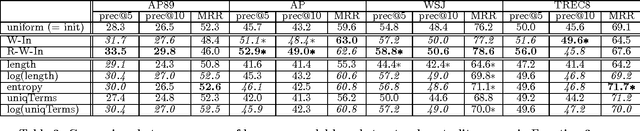
Inspired by the PageRank and HITS (hubs and authorities) algorithms for Web search, we propose a structural re-ranking approach to ad hoc information retrieval: we reorder the documents in an initially retrieved set by exploiting asymmetric relationships between them. Specifically, we consider generation links, which indicate that the language model induced from one document assigns high probability to the text of another; in doing so, we take care to prevent bias against long documents. We study a number of re-ranking criteria based on measures of centrality in the graphs formed by generation links, and show that integrating centrality into standard language-model-based retrieval is quite effective at improving precision at top ranks.
Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales
Jun 17, 2005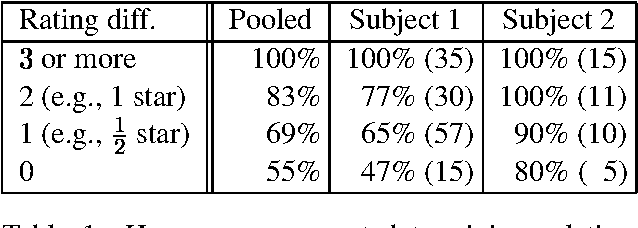
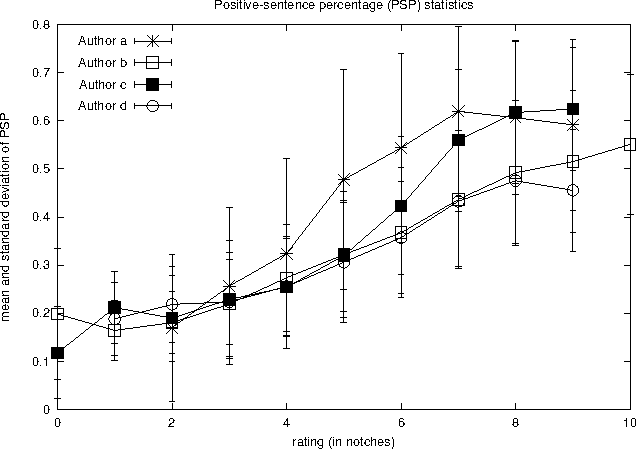
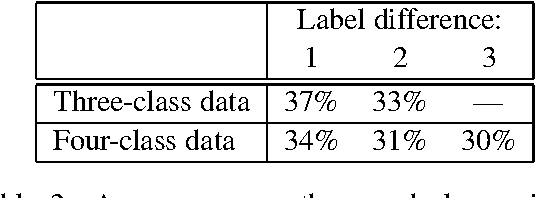

We address the rating-inference problem, wherein rather than simply decide whether a review is "thumbs up" or "thumbs down", as in previous sentiment analysis work, one must determine an author's evaluation with respect to a multi-point scale (e.g., one to five "stars"). This task represents an interesting twist on standard multi-class text categorization because there are several different degrees of similarity between class labels; for example, "three stars" is intuitively closer to "four stars" than to "one star". We first evaluate human performance at the task. Then, we apply a meta-algorithm, based on a metric labeling formulation of the problem, that alters a given n-ary classifier's output in an explicit attempt to ensure that similar items receive similar labels. We show that the meta-algorithm can provide significant improvements over both multi-class and regression versions of SVMs when we employ a novel similarity measure appropriate to the problem.
A Matter of Opinion: Sentiment Analysis and Business Intelligence
Apr 06, 2005A general-audience introduction to the area of "sentiment analysis", the computational treatment of subjective, opinion-oriented language (an example application is determining whether a review is "thumbs up" or "thumbs down"). Some challenges, applications to business-intelligence tasks, and potential future directions are described.
* 2 pages