 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the regularity and conditioning of low rank semidefinite programs
Feb 25, 2020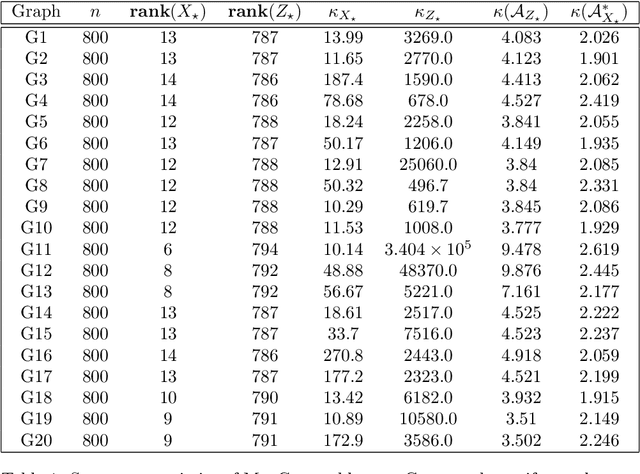
Low rank matrix recovery problems appear widely in statistics, combinatorics, and imaging. One celebrated method for solving these problems is to formulate and solve a semidefinite program (SDP). It is often known that the exact solution to the SDP with perfect data recovers the solution to the original low rank matrix recovery problem. It is more challenging to show that an approximate solution to the SDP formulated with noisy problem data acceptably solves the original problem; arguments are usually ad hoc for each problem setting, and can be complex. In this note, we identify a set of conditions that we call regularity that limit the error due to noisy problem data or incomplete convergence. In this sense, regular SDPs are robust: regular SDPs can be (approximately) solved efficiently at scale; and the resulting approximate solutions, even with noisy data, can be trusted. Moreover, we show that regularity holds generically, and also for many structured low rank matrix recovery problems, including the stochastic block model, $\mathbb{Z}_2$ synchronization, and matrix completion. Formally, we call an SDP regular if it has a surjective constraint map, admits a unique primal and dual solution pair, and satisfies strong duality and strict complementarity. However, regularity is not a panacea: we show the Burer-Monteiro formulation of the SDP may have spurious second-order critical points, even for a regular SDP with a rank 1 solution.
Factor Group-Sparse Regularization for Efficient Low-Rank Matrix Recovery
Nov 18, 2019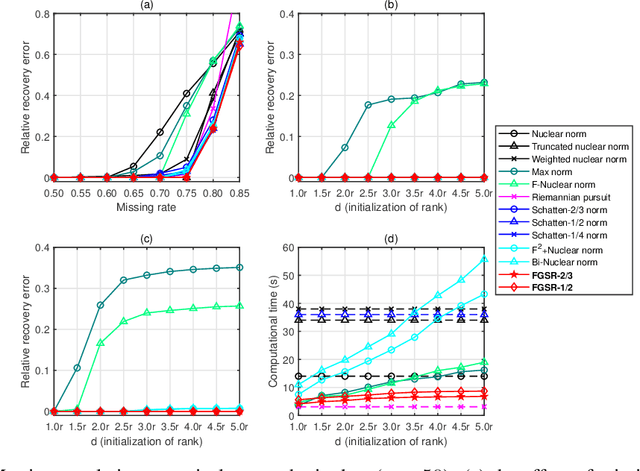
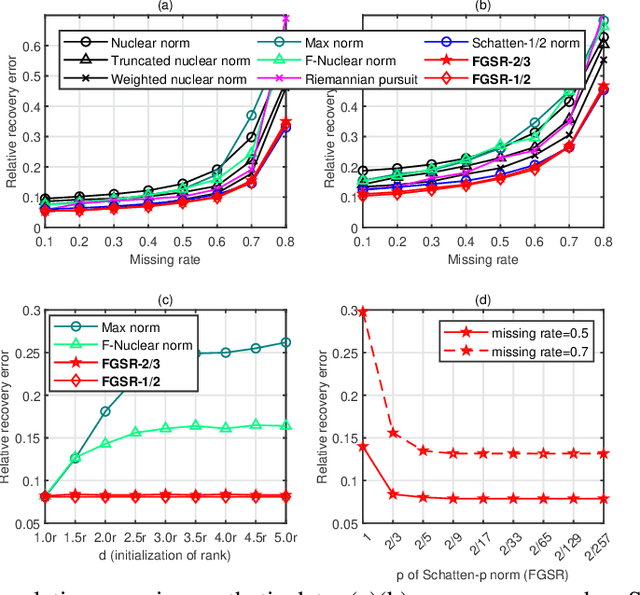
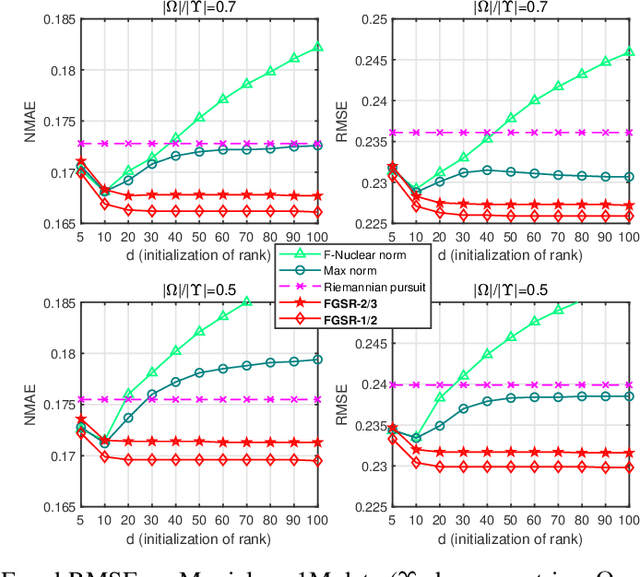
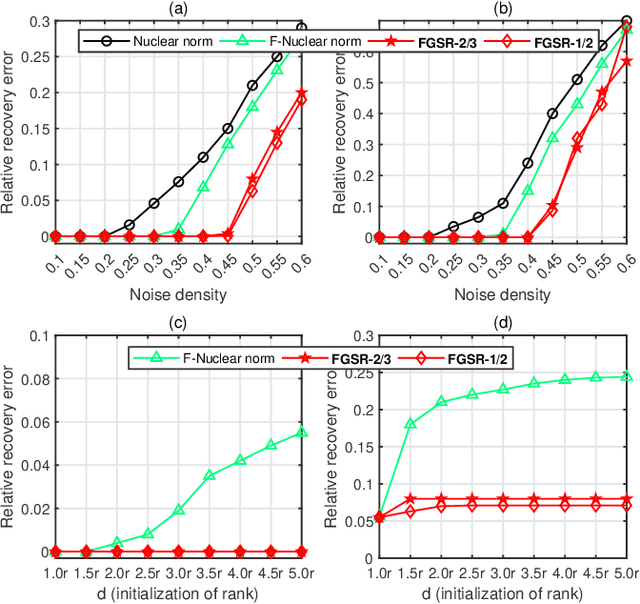
This paper develops a new class of nonconvex regularizers for low-rank matrix recovery. Many regularizers are motivated as convex relaxations of the matrix rank function. Our new factor group-sparse regularizers are motivated as a relaxation of the number of nonzero columns in a factorization of the matrix. These nonconvex regularizers are sharper than the nuclear norm; indeed, we show they are related to Schatten-$p$ norms with arbitrarily small $0 < p \leq 1$. Moreover, these factor group-sparse regularizers can be written in a factored form that enables efficient and effective nonconvex optimization; notably, the method does not use singular value decomposition. We provide generalization error bounds for low-rank matrix completion which show improved upper bounds for Schatten-$p$ norm reglarization as $p$ decreases. Compared to the max norm and the factored formulation of the nuclear norm, factor group-sparse regularizers are more efficient, accurate, and robust to the initial guess of rank. Experiments show promising performance of factor group-sparse regularization for low-rank matrix completion and robust principal component analysis.
Bundle Method Sketching for Low Rank Semidefinite Programming
Nov 11, 2019
In this paper, we show that the bundle method can be applied to solve semidefinite programming problems with a low rank solution without ever constructing a full matrix. To accomplish this, we use recent results from randomly sketching matrix optimization problems and from the analysis of bundle methods. Under strong duality and strict complementarity of SDP, we achieve $\tilde{O}(\frac{1}{\epsilon})$ convergence rates for both the primal and the dual sequences, and the algorithm proposed outputs a $O(\sqrt{\epsilon})$ approximate solution $\hat{X}$ (measured by distances) with a low rank representation with at most $\tilde{O}(\frac{1}{\epsilon})$ many iterations.
Low-rank matrix recovery with composite optimization: good conditioning and rapid convergence
Apr 22, 2019
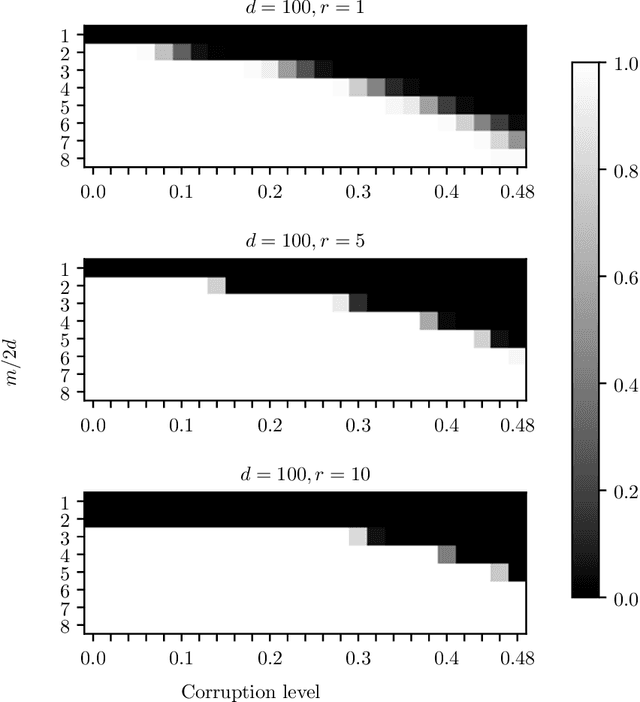
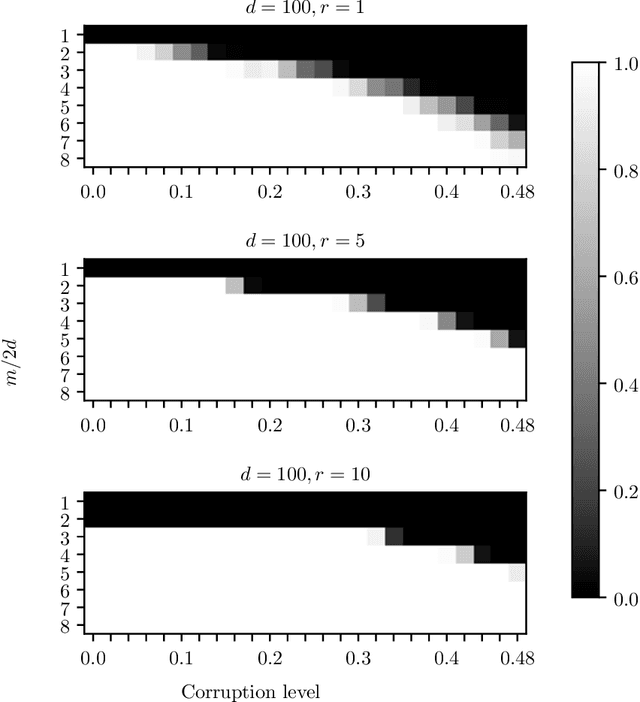
The task of recovering a low-rank matrix from its noisy linear measurements plays a central role in computational science. Smooth formulations of the problem often exhibit an undesirable phenomenon: the condition number, classically defined, scales poorly with the dimension of the ambient space. In contrast, we here show that in a variety of concrete circumstances, nonsmooth penalty formulations do not suffer from the same type of ill-conditioning. Consequently, standard algorithms for nonsmooth optimization, such as subgradient and prox-linear methods, converge at a rapid dimension-independent rate when initialized within constant relative error of the solution. Moreover, nonsmooth formulations are naturally robust against outliers. Our framework subsumes such important computational tasks as phase retrieval, blind deconvolution, quadratic sensing, matrix completion, and robust PCA. Numerical experiments on these problems illustrate the benefits of the proposed approach.
An Optimal-Storage Approach to Semidefinite Programming using Approximate Complementarity
Feb 09, 2019
This paper develops a new storage-optimal algorithm that provably solves generic semidefinite programs (SDPs) in standard form. This method is particularly effective for weakly constrained SDPs. The key idea is to formulate an approximate complementarity principle: Given an approximate solution to the dual SDP, the primal SDP has an approximate solution whose range is contained in the eigenspace with small eigenvalues of the dual slack matrix. For weakly constrained SDPs, this eigenspace has very low dimension, so this observation significantly reduces the search space for the primal solution. This result suggests an algorithmic strategy that can be implemented with minimal storage: (1) Solve the dual SDP approximately; (2) compress the primal SDP to the eigenspace with small eigenvalues of the dual slack matrix; (3) solve the compressed primal SDP. The paper also provides numerical experiments showing that this approach is successful for a range of interesting large-scale SDPs.
Frank-Wolfe Style Algorithms for Large Scale Optimization
Aug 15, 2018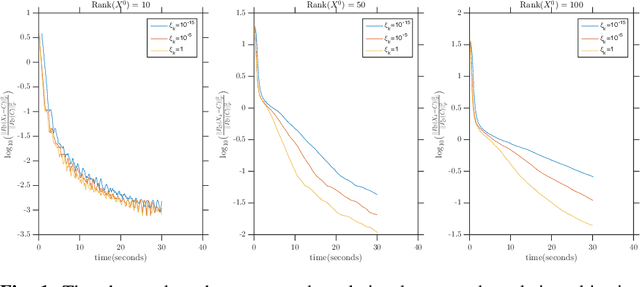
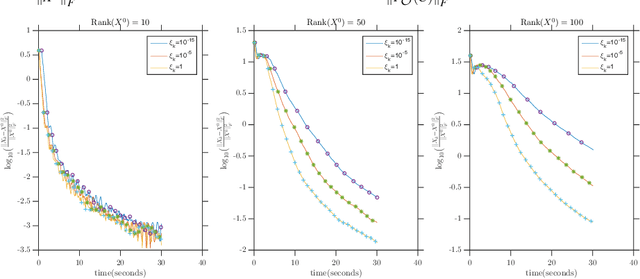
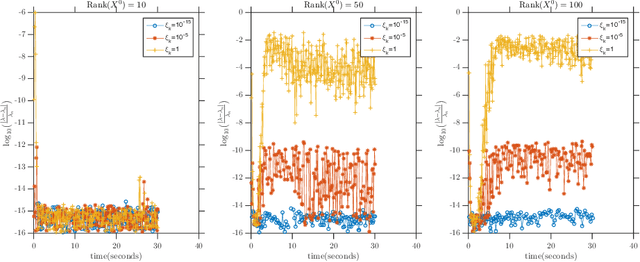
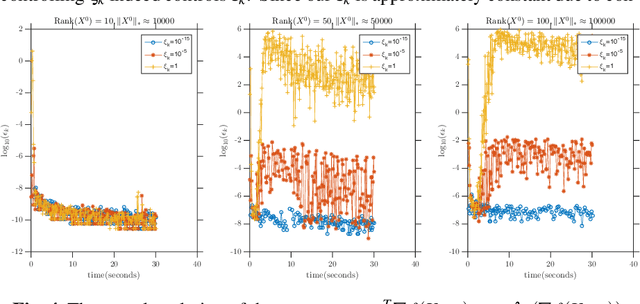
We introduce a few variants on Frank-Wolfe style algorithms suitable for large scale optimization. We show how to modify the standard Frank-Wolfe algorithm using stochastic gradients, approximate subproblem solutions, and sketched decision variables in order to scale to enormous problems while preserving (up to constants) the optimal convergence rate $\mathcal{O}(\frac{1}{k})$.
The Leave-one-out Approach for Matrix Completion: Primal and Dual Analysis
Mar 20, 2018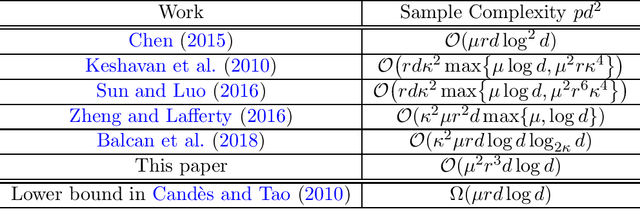
In this paper, we introduce a powerful technique, Leave-One-Out, to the analysis of low-rank matrix completion problems. Using this technique, we develop a general approach for obtaining fine-grained, entry-wise bounds on iterative stochastic procedures. We demonstrate the power of this approach in analyzing two of the most important algorithms for matrix completion: the non-convex approach based on Singular Value Projection (SVP), and the convex relaxation approach based on nuclear norm minimization (NNM). In particular, we prove for the first time that the original form of SVP, without re-sampling or sample splitting, converges linearly in the infinity norm. We further apply our leave-one-out approach to an iterative procedure that arises in the analysis of the dual solutions of NNM. Our results show that NNM recovers the true $ d $-by-$ d $ rank-$ r $ matrix with $\mathcal{O}(\mu^2 r^3d \log d )$ observed entries, which has optimal dependence on the dimension and is independent of the condition number of the matrix. To the best of our knowledge, this is the first sample complexity result for a tractable matrix completion algorithm that satisfies these two properties simultaneously.