 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTECM: Transfer Evidential C-means Clustering
Dec 19, 2021


Clustering is widely used in text analysis, natural language processing, image segmentation, and other data mining fields. As a promising clustering algorithm, the evidential c-means (ECM) can provide a deeper insight on the data by allowing an object to belong to several subsets of classes, which extends those of hard, fuzzy, and possibilistic clustering. However, as it needs to estimate much more parameters than the other classical partition-based algorithms, it only works well when the available data is sufficient and of good quality. In order to overcome these shortcomings, this paper proposes a transfer evidential c-means (TECM) algorithm, by introducing the strategy of transfer learning. The objective function of TECM is obtained by introducing barycenters in the source domain on the basis of the objective function of ECM, and the iterative optimization strategy is used to solve the objective function. In addition, the TECM can adapt to situation where the number of clusters in the source domain and the target domain is different. The proposed algorithm has been validated on synthetic and real-world datasets. Experimental results demonstrate the effectiveness of TECM in comparison with the original ECM as well as other representative multitask or transfer clustering algorithms.
EGMM: an Evidential Version of the Gaussian Mixture Model for Clustering
Oct 03, 2020

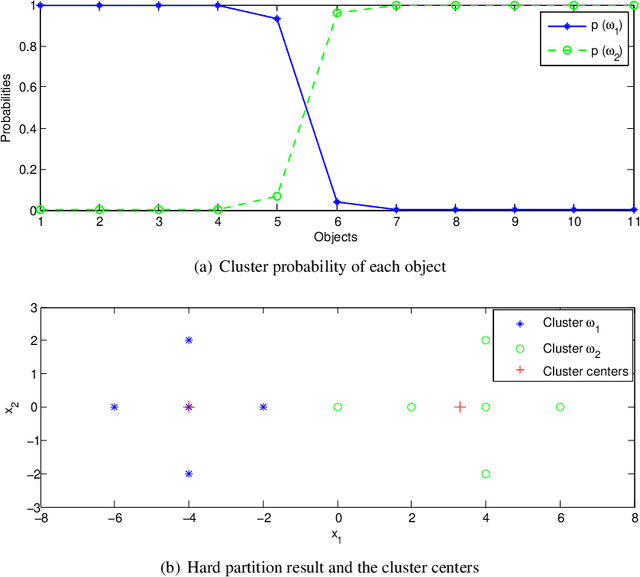
The Gaussian mixture model (GMM) provides a convenient yet principled framework for clustering, with properties suitable for statistical inference. In this paper, we propose a new model-based clustering algorithm, called EGMM (evidential GMM), in the theoretical framework of belief functions to better characterize cluster-membership uncertainty. With a mass function representing the cluster membership of each object, the evidential Gaussian mixture distribution composed of the components over the powerset of the desired clusters is proposed to model the entire dataset. The parameters in EGMM are estimated by a specially designed Expectation-Maximization (EM) algorithm. A validity index allowing automatic determination of the proper number of clusters is also provided. The proposed EGMM is as convenient as the classical GMM, but can generate a more informative evidential partition for the considered dataset. Experiments with synthetic and real datasets demonstrate the good performance of the proposed method as compared with some other prototype-based and model-based clustering techniques.
Analysis and Extension of the Evidential Reasoning Algorithm for Multiple Attribute Decision Analysis with Uncertainty
Mar 28, 2019
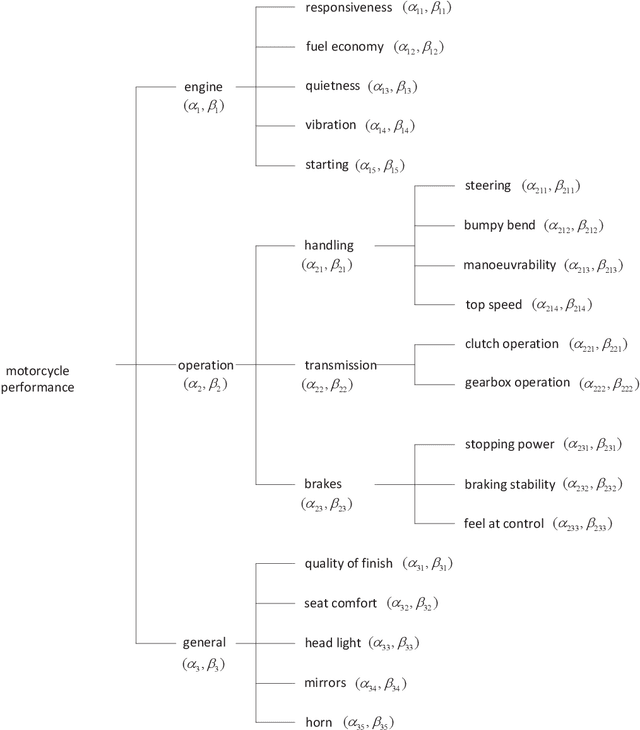
In multiple attribute decision analysis (MADA) problems, one often needs to deal with assessment information with uncertainty. The evidential reasoning approach is one of the most effective methods to deal with such MADA problems. As kernel of the evidential reasoning approach, an original evidential reasoning (ER) algorithm was firstly proposed by Yang et al, and later they modified the ER algorithm in order to satisfy the proposed four synthesis axioms with which a rational aggregation process needs to satisfy. However, up to present, the essential difference of the two ER algorithms as well as the rationality of the synthesis axioms are still unclear. In this paper, we analyze the ER algorithms in Dempster-Shafer theory (DST) framework and prove that the original ER algorithm follows the reliability discounting and combination scheme, while the modified one follows the importance discounting and combination scheme. Further we reveal that the four synthesis axioms are not valid criteria to check the rationality of one attribute aggregation algorithm. Based on these new findings, an extended ER algorithm is proposed to take into account both the reliability and importance of different attributes, which provides a more general attribute aggregation scheme for MADA with uncertainty. A motorcycle performance assessment problem is examined to illustrate the proposed algorithm.