 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Zero-Knowledge Task Planning via a Language-based Approach
Jan 06, 2026In this work, we introduce and formalize the Zero-Knowledge Task Planning (ZKTP) problem, i.e., formulating a sequence of actions to achieve some goal without task-specific knowledge. Additionally, we present a first investigation and approach for ZKTP that leverages a large language model (LLM) to decompose natural language instructions into subtasks and generate behavior trees (BTs) for execution. If errors arise during task execution, the approach also uses an LLM to adjust the BTs on-the-fly in a refinement loop. Experimental validation in the AI2-THOR simulator demonstrate our approach's effectiveness in improving overall task performance compared to alternative approaches that leverage task-specific knowledge. Our work demonstrates the potential of LLMs to effectively address several aspects of the ZKTP problem, providing a robust framework for automated behavior generation with no task-specific setup.
Sequential Discrete Action Selection via Blocking Conditions and Resolutions
Sep 12, 2024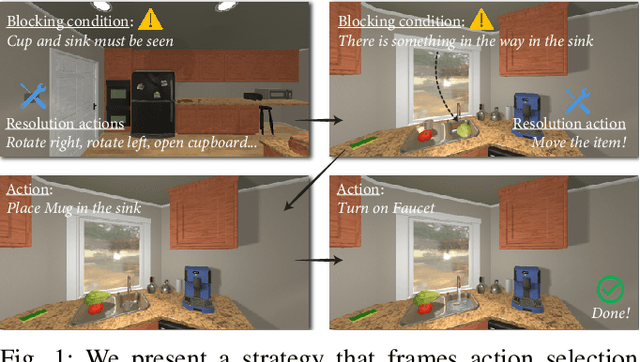
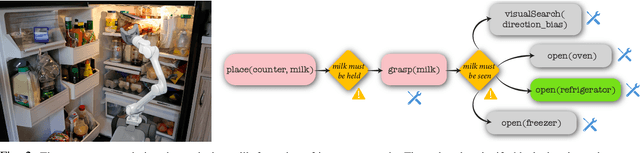
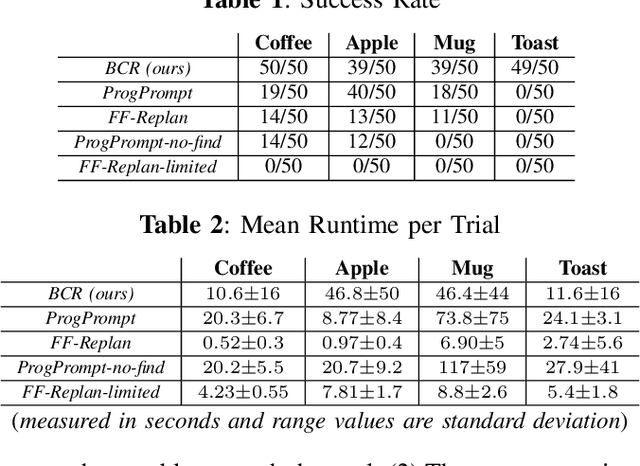
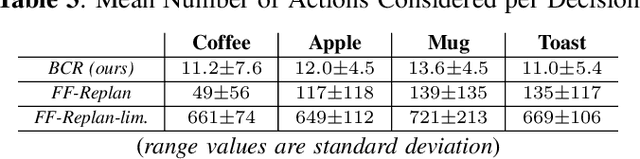
In this work, we introduce a strategy that frames the sequential action selection problem for robots in terms of resolving \textit{blocking conditions}, i.e., situations that impede progress on an action en route to a goal. This strategy allows a robot to make one-at-a-time decisions that take in pertinent contextual information and swiftly adapt and react to current situations. We present a first instantiation of this strategy that combines a state-transition graph and a zero-shot Large Language Model (LLM). The state-transition graph tracks which previously attempted actions are currently blocked and which candidate actions may resolve existing blocking conditions. This information from the state-transition graph is used to automatically generate a prompt for the LLM, which then uses the given context and set of possible actions to select a single action to try next. This selection process is iterative, with each chosen and executed action further refining the state-transition graph, continuing until the agent either fulfills the goal or encounters a termination condition. We demonstrate the effectiveness of our approach by comparing it to various LLM and traditional task-planning methods in a testbed of simulation experiments. We discuss the implications of our work based on our results.