 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimalist Genetic Programming
Jun 08, 2026Genetic programming (GP) is based on two important insights. First, that any learning task can fundamentally be posed as a program induction problem, where the goal is to construct a symbolic hierarchical model that is expressed as a syntax tree. Second, to pose this task as a search problem, and use evolution to locate the desired model. Since it was proposed, GP has produced notable results in a wide range of tasks and problem domains. This work presents an alternative view by modifying the second core insight of GP, posing the problem as a syntactic derivation task instead. In particular, this paper presents Minimalist Genetic Programming (MGP), an algorithm that like GP is biologically inspired, but instead of evolution it takes inspiration from the Minimalist Program to human language, in which syntax is understood as an optimal solution to the problem of linking two other mental systems. In minimalism, the core computational process is a binary set formation operator called $MERGE$, than can be used to incrementally construct complex syntactic structures using a simple Markovian process. MGP is able to discover the core building blocks of the symbolic expressions, and to incrementally combined them using $MERGE$. The proposed system is benchmarked on symbolic regression tasks that are known to be difficult to solve with standard GP systems because of the propensity for bloat. Results show that when a proper lexicon of atomic syntactic objects are chosen, MGP is able to consistently produce the exact ground truth model on a set of symbolic regression where standard GP struggles to do the same. The insights provided by minimalism are shown to be relevant to the problem of program induction, and should be explored further based on the potential exhibited by MGP in this work.
Highlights of Semantics in Multi-objective Genetic Programming
Jun 13, 2022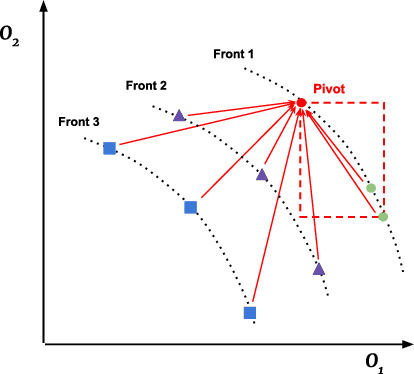
Semantics is a growing area of research in Genetic programming (GP) and refers to the behavioural output of a Genetic Programming individual when executed. This research expands upon the current understanding of semantics by proposing a new approach: Semantic-based Distance as an additional criteriOn (SDO), in the thus far, somewhat limited researched area of semantics in Multi-objective GP (MOGP). Our work included an expansive analysis of the GP in terms of performance and diversity metrics, using two additional semantic-based approaches, namely Semantic Similarity-based Crossover (SCC) and Semantic-based Crowding Distance (SCD). Each approach is integrated into two evolutionary multi-objective (EMO) frameworks: Non-dominated Sorting Genetic Algorithm II (NSGA-II) and the Strength Pareto Evolutionary Algorithm 2 (SPEA2), and along with the three semantic approaches, the canonical form of NSGA-II and SPEA2 are rigorously compared. Using highly-unbalanced binary classification datasets, we demonstrated that the newly proposed approach of SDO consistently generated more non-dominated solutions, with better diversity and improved hypervolume results.
GSGP-CUDA -- a CUDA framework for Geometric Semantic Genetic Programming
Jun 08, 2021
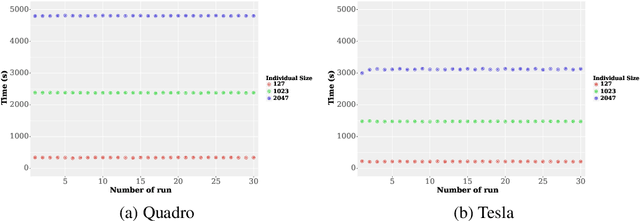
Geometric Semantic Genetic Programming (GSGP) is a state-of-the-art machine learning method based on evolutionary computation. GSGP performs search operations directly at the level of program semantics, which can be done more efficiently then operating at the syntax level like most GP systems. Efficient implementations of GSGP in C++ exploit this fact, but not to its full potential. This paper presents GSGP-CUDA, the first CUDA implementation of GSGP and the most efficient, which exploits the intrinsic parallelism of GSGP using GPUs. Results show speedups greater than 1,000X relative to the state-of-the-art sequential implementation.
Semantics in Multi-objective Genetic Programming
May 06, 2021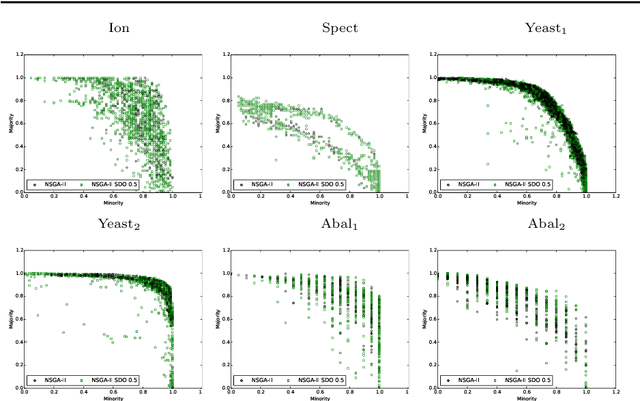
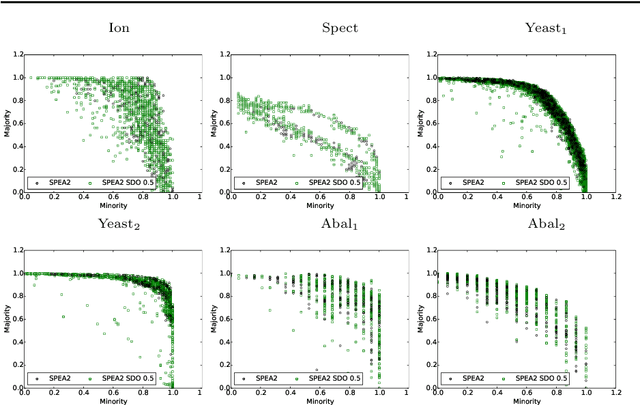
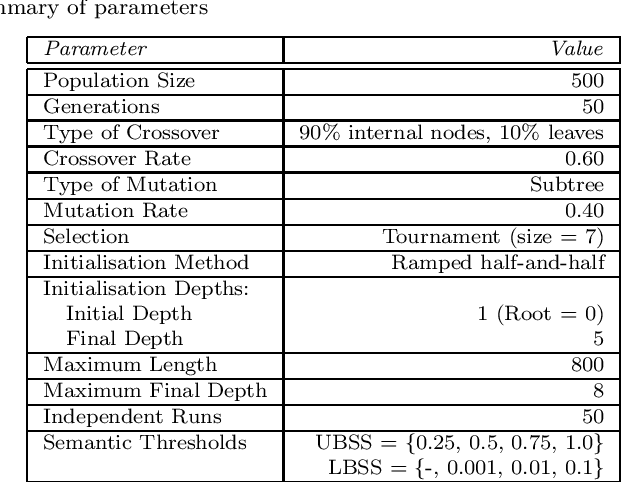
Semantics has become a key topic of research in Genetic Programming (GP). Semantics refers to the outputs (behaviour) of a GP individual when this is run on a data set. The majority of works that focus on semantic diversity in single-objective GP indicates that it is highly beneficial in evolutionary search. Surprisingly, there is minuscule research conducted in semantics in Multi-objective GP (MOGP). In this work we make a leap beyond our understanding of semantics in MOGP and propose SDO: Semantic-based Distance as an additional criteriOn. This naturally encourages semantic diversity in MOGP. To do so, we find a pivot in the less dense region of the first Pareto front (most promising front). This is then used to compute a distance between the pivot and every individual in the population. The resulting distance is then used as an additional criterion to be optimised to favour semantic diversity. We also use two other semantic-based methods as baselines, called Semantic Similarity-based Crossover and Semantic-based Crowding Distance. Furthermore, we also use the NSGA-II and the SPEA2 for comparison too. We use highly unbalanced binary classification problems and consistently show how our proposed SDO approach produces more non-dominated solutions and better diversity, leading to better statistically significant results, using the hypervolume results as evaluation measure, compared to the rest of the other four methods.
Plotting time: On the usage of CNNs for time series classification
Feb 08, 2021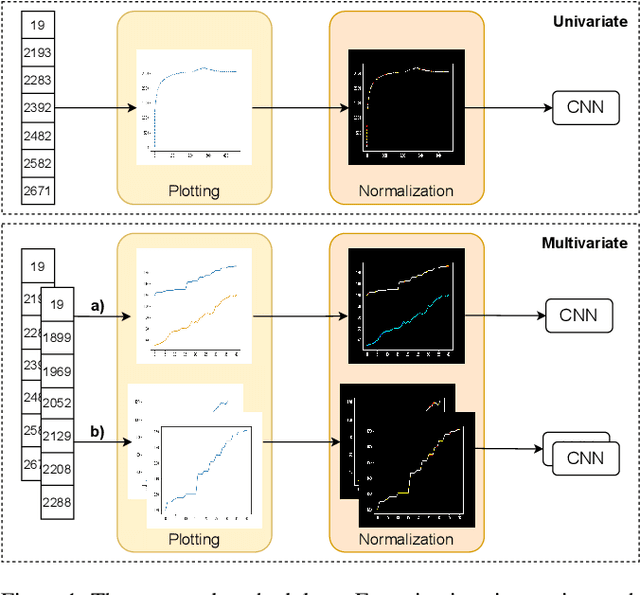
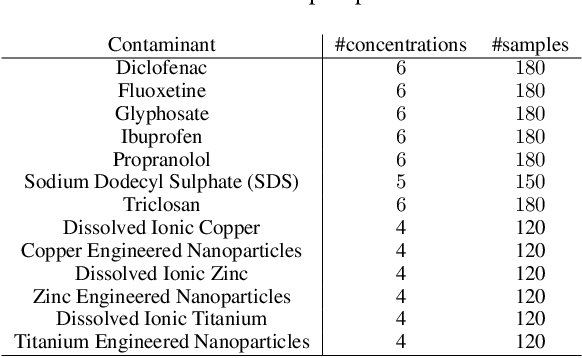

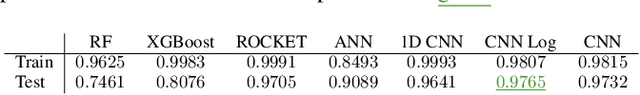
We present a novel approach for time series classification where we represent time series data as plot images and feed them to a simple CNN, outperforming several state-of-the-art methods. We propose a simple and highly replicable way of plotting the time series, and feed these images as input to a non-optimized shallow CNN, without any normalization or residual connections. These representations are no more than default line plots using the time series data, where the only pre-processing applied is to reduce the number of white pixels in the image. We compare our method with different state-of-the-art methods specialized in time series classification on two real-world non public datasets, as well as 98 datasets of the UCR dataset collection. The results show that our approach is very promising, achieving the best results on both real-world datasets and matching / beating the best state-of-the-art methods in six UCR datasets. We argue that, if a simple naive design like ours can obtain such good results, it is worth further exploring the capabilities of using image representation of time series data, along with more powerful CNNs, for classification and other related tasks.