 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummon a Demon and Bind it: A Grounded Theory of LLM Red Teaming in the Wild
Nov 13, 2023



Engaging in the deliberate generation of abnormal outputs from large language models (LLMs) by attacking them is a novel human activity. This paper presents a thorough exposition of how and why people perform such attacks. Using a formal qualitative methodology, we interviewed dozens of practitioners from a broad range of backgrounds, all contributors to this novel work of attempting to cause LLMs to fail. We relate and connect this activity between its practitioners' motivations and goals; the strategies and techniques they deploy; and the crucial role the community plays. As a result, this paper presents a grounded theory of how and why people attack large language models: LLM red teaming in the wild.
Surveying (Dis)Parities and Concerns of Compute Hungry NLP Research
Jun 29, 2023



Many recent improvements in NLP stem from the development and use of large pre-trained language models (PLMs) with billions of parameters. Large model sizes makes computational cost one of the main limiting factors for training and evaluating such models; and has raised severe concerns about the sustainability, reproducibility, and inclusiveness for researching PLMs. These concerns are often based on personal experiences and observations. However, there had not been any large-scale surveys that investigate them. In this work, we provide a first attempt to quantify these concerns regarding three topics, namely, environmental impact, equity, and impact on peer reviewing. By conducting a survey with 312 participants from the NLP community, we capture existing (dis)parities between different and within groups with respect to seniority, academia, and industry; and their impact on the peer reviewing process. For each topic, we provide an analysis and devise recommendations to mitigate found disparities, some of which already successfully implemented. Finally, we discuss additional concerns raised by many participants in free-text responses.
Assessing Language Model Deployment with Risk Cards
Mar 31, 2023

This paper introduces RiskCards, a framework for structured assessment and documentation of risks associated with an application of language models. As with all language, text generated by language models can be harmful, or used to bring about harm. Automating language generation adds both an element of scale and also more subtle or emergent undesirable tendencies to the generated text. Prior work establishes a wide variety of language model harms to many different actors: existing taxonomies identify categories of harms posed by language models; benchmarks establish automated tests of these harms; and documentation standards for models, tasks and datasets encourage transparent reporting. However, there is no risk-centric framework for documenting the complexity of a landscape in which some risks are shared across models and contexts, while others are specific, and where certain conditions may be required for risks to manifest as harms. RiskCards address this methodological gap by providing a generic framework for assessing the use of a given language model in a given scenario. Each RiskCard makes clear the routes for the risk to manifest harm, their placement in harm taxonomies, and example prompt-output pairs. While RiskCards are designed to be open-source, dynamic and participatory, we present a "starter set" of RiskCards taken from a broad literature survey, each of which details a concrete risk presentation. Language model RiskCards initiate a community knowledge base which permits the mapping of risks and harms to a specific model or its application scenario, ultimately contributing to a better, safer and shared understanding of the risk landscape.
Training a T5 Using Lab-sized Resources
Aug 25, 2022
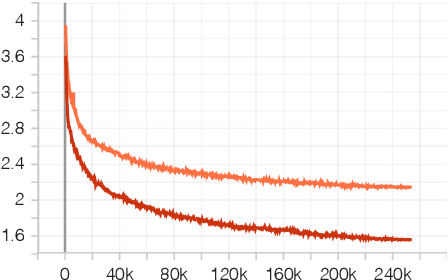
Training large neural language models on large datasets is resource- and time-intensive. These requirements create a barrier to entry, where those with fewer resources cannot build competitive models. This paper presents various techniques for making it possible to (a) train a large language model using resources that a modest research lab might have, and (b) train it in a reasonable amount of time. We provide concrete recommendations for practitioners, which we illustrate with a case study: a T5 model for Danish, the first for this language.
Sparse Probability of Agreement
Aug 12, 2022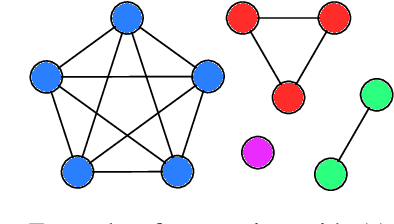
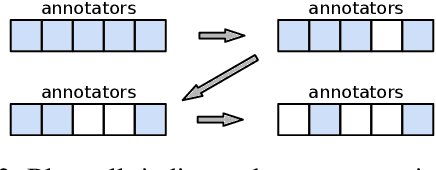
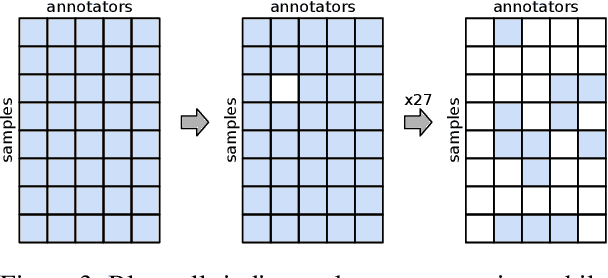
Measuring inter-annotator agreement is important for annotation tasks, but many metrics require a fully-annotated dataset (or subset), where all annotators annotate all samples. We define Sparse Probability of Agreement, SPA, which estimates the probability of agreement when no all annotator-item-pairs are available. We show that SPA, with some assumptions, is an unbiased estimator and provide multiple different weighing schemes for handling samples with different numbers of annotation, evaluated over a range of datasets.
The ITU Faroese Pairs Dataset
Jun 17, 2022This article documents a dataset of sentence pairs between Faroese and Danish, produced at ITU Copenhagen. The data covers tranlsation from both source languages, and is intended for use as training data for machine translation systems in this language pair.
Set Interdependence Transformer: Set-to-Sequence Neural Networks for Permutation Learning and Structure Prediction
Jun 08, 2022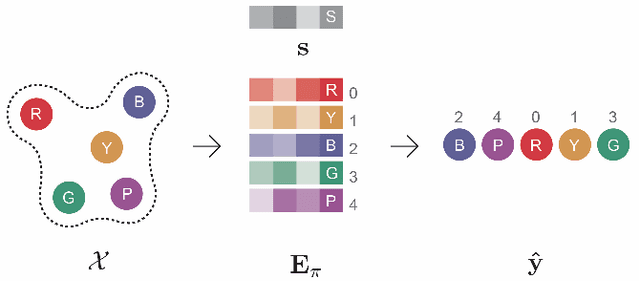
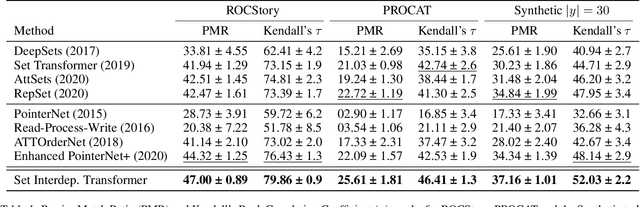
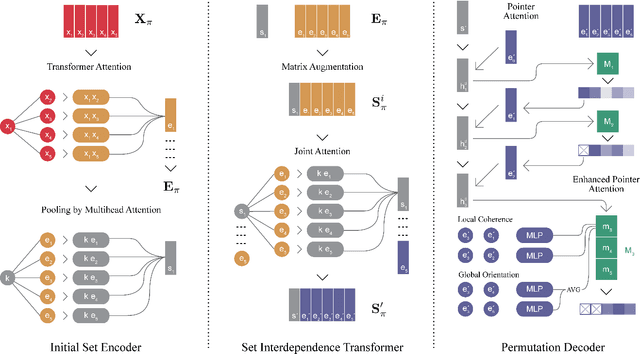
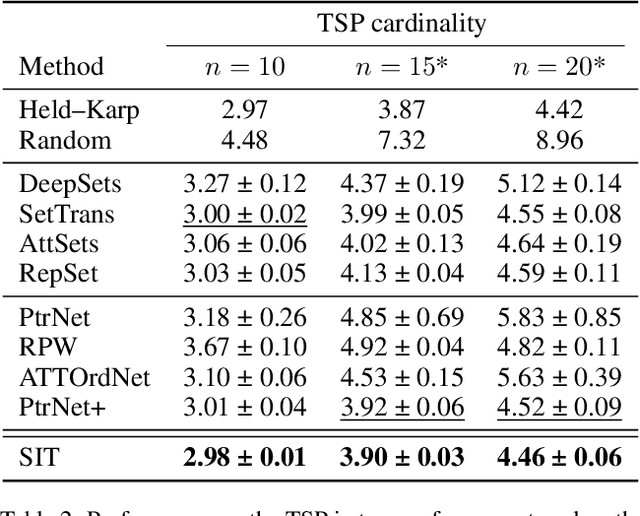
The task of learning to map an input set onto a permuted sequence of its elements is challenging for neural networks. Set-to-sequence problems occur in natural language processing, computer vision and structure prediction, where interactions between elements of large sets define the optimal output. Models must exhibit relational reasoning, handle varying cardinalities and manage combinatorial complexity. Previous attention-based methods require $n$ layers of their set transformations to explicitly represent $n$-th order relations. Our aim is to enhance their ability to efficiently model higher-order interactions through an additional interdependence component. We propose a novel neural set encoding method called the Set Interdependence Transformer, capable of relating the set's permutation invariant representation to its elements within sets of any cardinality. We combine it with a permutation learning module into a complete, 3-part set-to-sequence model and demonstrate its state-of-the-art performance on a number of tasks. These range from combinatorial optimization problems, through permutation learning challenges on both synthetic and established NLP datasets for sentence ordering, to a novel domain of product catalog structure prediction. Additionally, the network's ability to generalize to unseen sequence lengths is investigated and a comparative empirical analysis of the existing methods' ability to learn higher-order interactions is provided.
Bridging the Domain Gap for Stance Detection for the Zulu language
May 06, 2022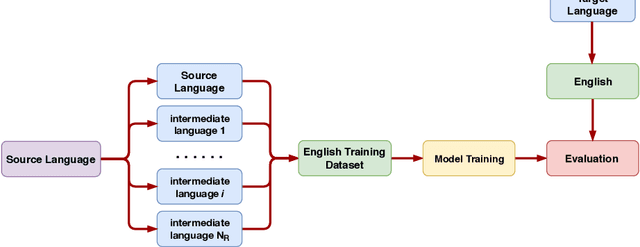
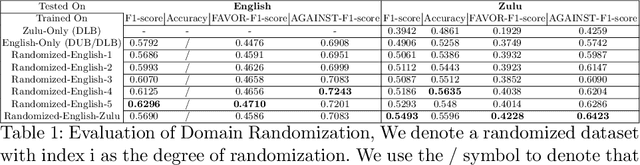
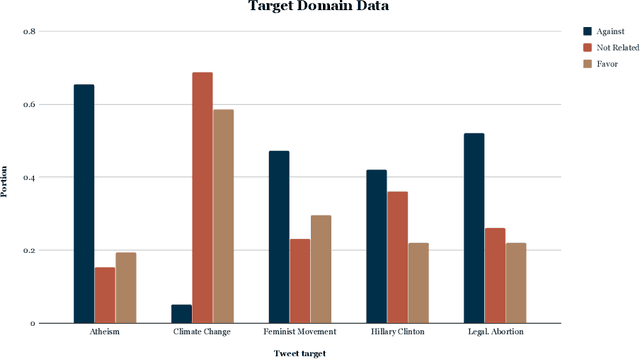

Misinformation has become a major concern in recent last years given its spread across our information sources. In the past years, many NLP tasks have been introduced in this area, with some systems reaching good results on English language datasets. Existing AI based approaches for fighting misinformation in literature suggest automatic stance detection as an integral first step to success. Our paper aims at utilizing this progress made for English to transfers that knowledge into other languages, which is a non-trivial task due to the domain gap between English and the target languages. We propose a black-box non-intrusive method that utilizes techniques from Domain Adaptation to reduce the domain gap, without requiring any human expertise in the target language, by leveraging low-quality data in both a supervised and unsupervised manner. This allows us to rapidly achieve similar results for stance detection for the Zulu language, the target language in this work, as are found for English. We also provide a stance detection dataset in the Zulu language. Our experimental results show that by leveraging English datasets and machine translation we can increase performances on both English data along with other languages.
Handling and Presenting Harmful Text
Apr 29, 2022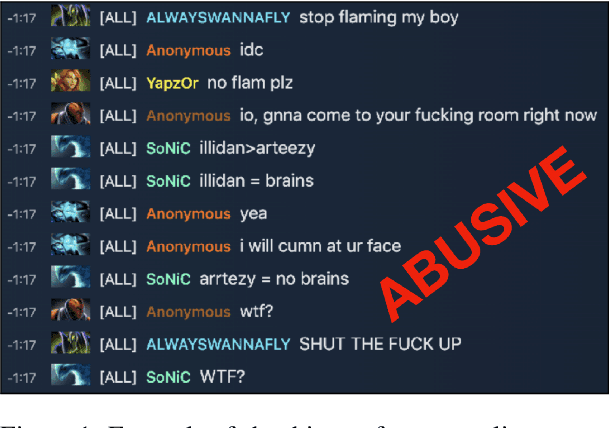
Textual data can pose a risk of serious harm. These harms can be categorised along three axes: (1) the harm type (e.g. misinformation, hate speech or racial stereotypes) (2) whether it is \textit{elicited} as a feature of the research design from directly studying harmful content (e.g. training a hate speech classifier or auditing unfiltered large-scale datasets) versus \textit{spuriously} invoked from working on unrelated problems (e.g. language generation or part of speech tagging) but with datasets that nonetheless contain harmful content, and (3) who it affects, from the humans (mis)represented in the data to those handling or labelling the data to readers and reviewers of publications produced from the data. It is an unsolved problem in NLP as to how textual harms should be handled, presented, and discussed; but, stopping work on content which poses a risk of harm is untenable. Accordingly, we provide practical advice and introduce \textsc{HarmCheck}, a resource for reflecting on research into textual harms. We hope our work encourages ethical, responsible, and respectful research in the NLP community.
Detecting Abusive Albanian
Jul 30, 2021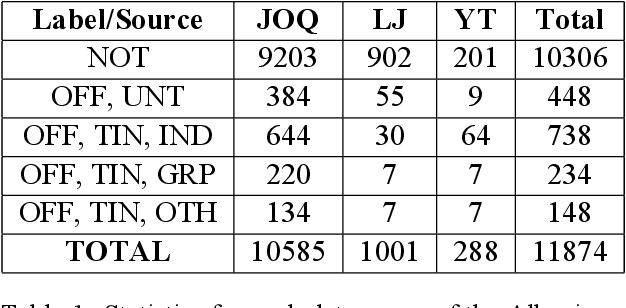
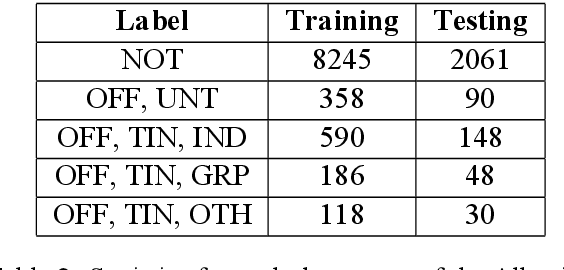
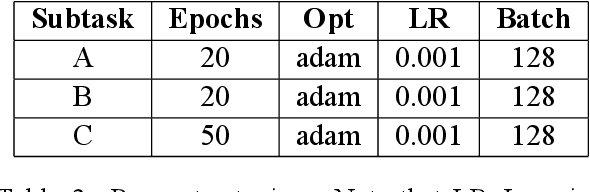
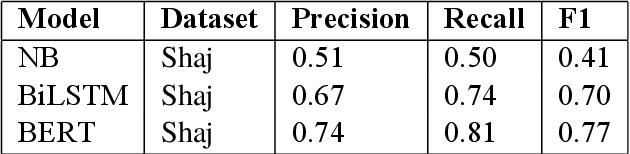
The ever growing usage of social media in the recent years has had a direct impact on the increased presence of hate speech and offensive speech in online platforms. Research on effective detection of such content has mainly focused on English and a few other widespread languages, while the leftover majority fail to have the same work put into them and thus cannot benefit from the steady advancements made in the field. In this paper we present \textsc{Shaj}, an annotated Albanian dataset for hate speech and offensive speech that has been constructed from user-generated content on various social media platforms. Its annotation follows the hierarchical schema introduced in OffensEval. The dataset is tested using three different classification models, the best of which achieves an F1 score of 0.77 for the identification of offensive language, 0.64 F1 score for the automatic categorization of offensive types and lastly, 0.52 F1 score for the offensive language target identification.