 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Deficits in Language Models: Causal Explanations for Procedural Hallucinations
Feb 22, 2026Large language models can follow complex procedures yet fail at a seemingly trivial final step: reporting a value they themselves computed moments earlier. We study this phenomenon as \emph{procedural hallucination}: failure to execute a verifiable, prompt-grounded specification even when the correct value is present in context. In long-context binding tasks with a known single-token candidate set, we find that many errors are readout-stage routing failures. Specifically, failures decompose into Stage~2A (gating) errors, where the model does not enter answer mode, and Stage~2B (binding) errors, where it enters answer mode but selects the wrong candidate (often due to recency bias). In the hard regime, Stage~2B accounts for most errors across model families in our tasks (Table~1). On Stage~2B error trials, a linear probe on the final-layer residual stream recovers the correct value far above chance (e.g., 74\% vs.\ 2\% on Qwen2.5-3B; Table~2), indicating that the answer is encoded but not used. We formalize ``present but not used'' via available vs.\ used mutual information and pseudo-prior interventions, yielding output-computable diagnostics and information-budget certificates. Finally, an oracle checkpointing intervention that restates the true binding near the query can nearly eliminate Stage~2B failures at long distance (e.g., Qwen2.5-3B $0/400 \rightarrow 399/400$ at $k = 1024$; Table~8).
LLMs are Bayesian, in Expectation, not in Realization
Jul 15, 2025Large language models demonstrate remarkable in-context learning capabilities, adapting to new tasks without parameter updates. While this phenomenon has been successfully modeled as implicit Bayesian inference, recent empirical findings reveal a fundamental contradiction: transformers systematically violate the martingale property, a cornerstone requirement of Bayesian updating on exchangeable data. This violation challenges the theoretical foundations underlying uncertainty quantification in critical applications. Our theoretical analysis establishes four key results: (1) positional encodings induce martingale violations of order $\Theta(\log n / n)$; (2) transformers achieve information-theoretic optimality with excess risk $O(n^{-1/2})$ in expectation over orderings; (3) the implicit posterior representation converges to the true Bayesian posterior in the space of sufficient statistics; and (4) we derive the optimal chain-of-thought length as $k^* = \Theta(\sqrt{n}\log(1/\varepsilon))$ with explicit constants, providing a principled approach to reduce inference costs while maintaining performance. Empirical validation on GPT-3 confirms predictions (1)-(3), with transformers reaching 99\% of theoretical entropy limits within 20 examples. Our framework provides practical methods for extracting calibrated uncertainty estimates from position-aware architectures and optimizing computational efficiency in deployment.
Robust Multimodal Learning via Entropy-Gated Contrastive Fusion
May 21, 2025Real-world multimodal systems routinely face missing-input scenarios, and in reality, robots lose audio in a factory or a clinical record omits lab tests at inference time. Standard fusion layers either preserve robustness or calibration but never both. We introduce Adaptive Entropy-Gated Contrastive Fusion (AECF), a single light-weight layer that (i) adapts its entropy coefficient per instance, (ii) enforces monotone calibration across all modality subsets, and (iii) drives a curriculum mask directly from training-time entropy. On AV-MNIST and MS-COCO, AECF improves masked-input mAP by +18 pp at a 50% drop rate while reducing ECE by up to 200%, yet adds 1% run-time. All back-bones remain frozen, making AECF an easy drop-in layer for robust, calibrated multimodal inference.
Multitaper Spectral Estimation HDP-HMMs for EEG Sleep Inference
May 18, 2018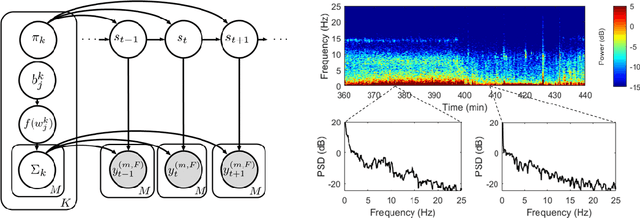
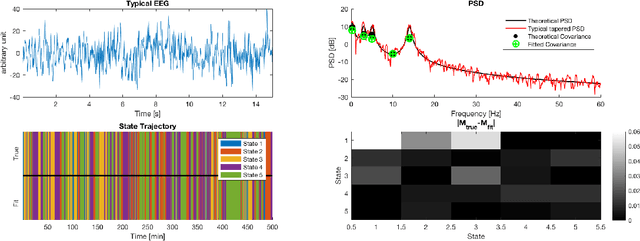
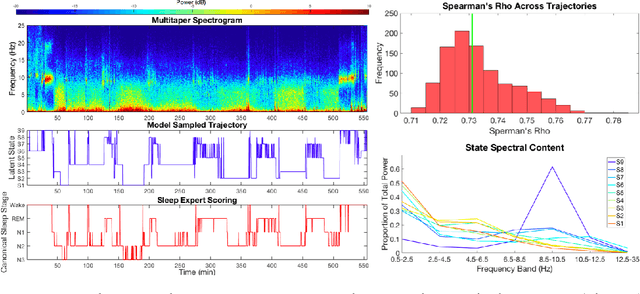
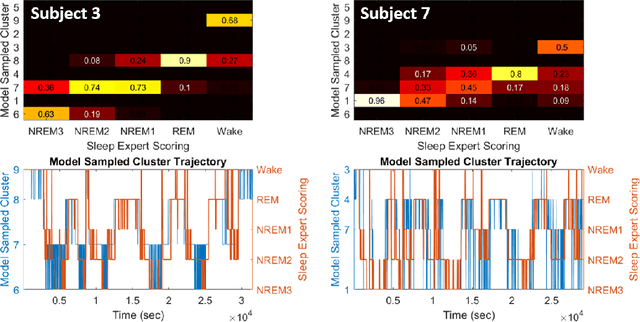
Electroencephalographic (EEG) monitoring of neural activity is widely used for sleep disorder diagnostics and research. The standard of care is to manually classify 30-second epochs of EEG time-domain traces into 5 discrete sleep stages. Unfortunately, this scoring process is subjective and time-consuming, and the defined stages do not capture the heterogeneous landscape of healthy and clinical neural dynamics. This motivates the search for a data-driven and principled way to identify the number and composition of salient, reoccurring brain states present during sleep. To this end, we propose a Hierarchical Dirichlet Process Hidden Markov Model (HDP-HMM), combined with wide-sense stationary (WSS) time series spectral estimation to construct a generative model for personalized subject sleep states. In addition, we employ multitaper spectral estimation to further reduce the large variance of the spectral estimates inherent to finite-length EEG measurements. By applying our method to both simulated and human sleep data, we arrive at three main results: 1) a Bayesian nonparametric automated algorithm that recovers general temporal dynamics of sleep, 2) identification of subject-specific "microstates" within canonical sleep stages, and 3) discovery of stage-dependent sub-oscillations with shared spectral signatures across subjects.