 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRank-Constrained Deep Matrix Completion for Group Recommendation
Jun 01, 2026The growing popularity of group activities has increased the need for methods that provide recommendations to groups of users given their individual preferences. Many existing group recommender systems rely on aggregating individual user preferences, but they often struggle with high-dimensional and highly sparse rating data commonly found in real-world scenarios. We propose Group Rank-Constrained Deep Matrix Completion (Group RC-DMC), a novel framework that extends RC-DMC by integrating group-level representation learning via a Set-Transformer aggregator, jointly leveraging low-rank structure and attention-based nonlinear modeling. Unlike most existing group recommender systems, Group RC-DMC unifies explicit low-rank regularization, linear encoder-decoder architectures, and attention-based nonlinear group modeling within a single framework, yielding accurate predictions at both the individual and group levels. Group RC-DMC addresses data sparsity through low-rank matrix completion, computing per-user latent representations from observed ratings only, and enforcing a rank constraint on the latent space using a nuclear-norm proximal step based on periodic singular value thresholding. The decoder is parametrized as a low-rank factorization, enabling efficient inference. Experimental results on the MovieLens and Goodbooks datasets demonstrate that Group RC-DMC achieves superior reconstruction accuracy, measured by lower group RMSE, while remaining computationally efficient and competitive in group-level performance in terms of precision, recall, and F1 score compared with weighted-before-factorization (WBF) and after-factorization (AF) baselines. The results highlight the model's ability to recover the underlying low-rank structure of user-item interactions and provide robust group recommendations across small, medium, and large user groups.
Standardized feature extraction from pairwise conflicts applied to the train rescheduling problem
Apr 12, 2022


We propose a train rescheduling algorithm which applies a standardized feature selection based on pairwise conflicts in order to serve as input for the reinforcement learning framework. We implement an analytical method which identifies and optimally solves every conflict arising between two trains, then we design a corresponding observation space which features the most relevant information considering these conflicts. The data obtained this way then translates to actions in the context of the reinforcement learning framework. We test our preliminary model using the evaluation metrics of the Flatland Challenge. The empirical results indicate that the suggested feature space provides meaningful observations, from which a sensible scheduling policy can be learned.
Pruning CNN's with linear filter ensembles
Mar 03, 2020


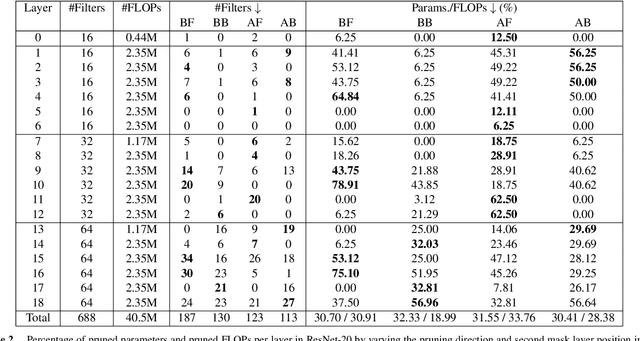
Despite the promising results of convolutional neural networks (CNNs), their application on devices with limited resources is still a big challenge; this is mainly due to the huge memory and computation requirements of the CNN. To counter the limitation imposed by the network size, we use pruning to reduce the network size and -- implicitly -- the number of floating point operations (FLOPs). Contrary to the filter norm method -- used in ``conventional`` network pruning -- based on the assumption that a smaller norm implies ``less importance'' to its associated component, we develop a novel filter importance norm that is based on the change in the empirical loss caused by the presence or removal of a component from the network architecture. Since there are too many individual possibilities for filter configuration, we repeatedly sample from these architectural components and measure the system performance in the respective state of components being active or disabled. The result is a collection of filter ensembles -- filter masks -- and associated performance values. We rank the filters based on a linear and additive model and remove the least important ones such that the drop in network accuracy is minimal. We evaluate our method on a fully connected network, as well as on the ResNet architecture trained on the CIFAR-10 dataset. Using our pruning method, we managed to remove $60\%$ of the parameters and $64\%$ of the FLOPs from the ResNet with an accuracy drop of less than $0.6\%$.
Single View Distortion Correction using Semantic Guidance
Nov 15, 2019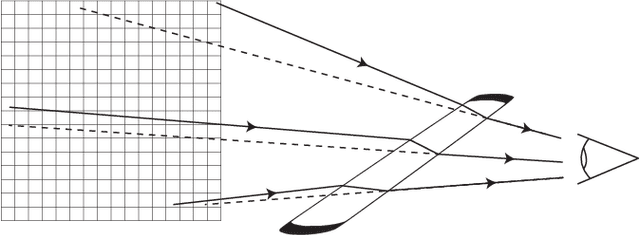
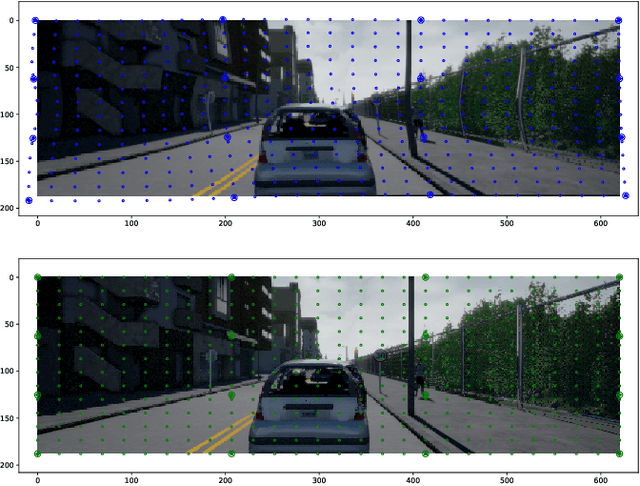


Most distortion correction methods focus on simple forms of distortion, such as radial or linear distortions. These works undistort images either based on measurements in the presence of a calibration grid, or use multiple views to find point correspondences and predict distortion parameters. When possible distortions are more complex, e.g. in the case of a camera being placed behind a refractive surface such as glass, the standard method is to use a calibration grid. Considering a high variety of distortions, it is nonviable to conduct these measurements. In this work, we present a single view distortion correction method which is capable of undistorting images containing arbitrarily complex distortions by exploiting recent advancements in differentiable image sampling and in the usage of semantic information to augment various tasks. The results of this work show that our model is able to estimate and correct highly complex distortions, and that incorporating semantic information mitigates the process of image undistortion.
Distortion Estimation Through Explicit Modeling of the Refractive Surface
Sep 24, 2019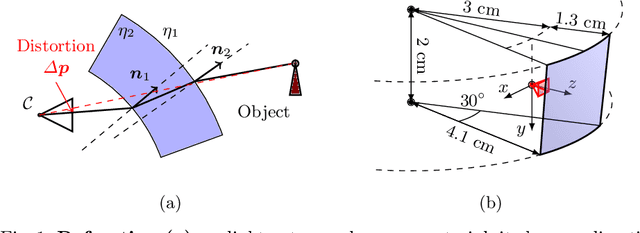
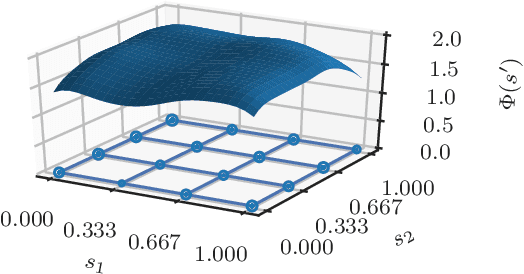
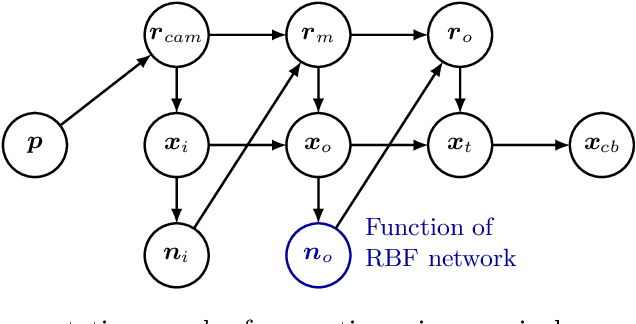

Precise calibration is a must for high reliance 3D computer vision algorithms. A challenging case is when the camera is behind a protective glass or transparent object: due to refraction, the image is heavily distorted; the pinhole camera model alone can not be used and a distortion correction step is required. By directly modeling the geometry of the refractive media, we build the image generation process by tracing individual light rays from the camera to a target. Comparing the generated images to their distorted - observed - counterparts, we estimate the geometry parameters of the refractive surface via model inversion by employing an RBF neural network. We present an image collection methodology that produces data suited for finding the distortion parameters and test our algorithm on synthetic and real-world data. We analyze the results of the algorithm.
* Accepted to ICANN 2019