 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Needles in Document Haystacks: Sensitivity Testing of LLM-as-a-Judge Similarity Scoring
Apr 20, 2026We propose a scalable, multifactorial experimental framework that systematically probes LLM sensitivity to subtle semantic changes in pairwise document comparison. We analogize this as a needle-in-a-haystack problem: a single semantically altered sentence (the needle) is embedded within surrounding context (the hay), and we vary the perturbation type (negation, conjunction swap, named entity replacement), context type (original vs. topically unrelated), needle position, and document length across all combinations, testing five LLMs on tens of thousands of document pairs. Our analysis reveals several striking findings. First, LLMs exhibit a within-document positional bias distinct from previously studied candidate-order effects: most models penalize semantic differences more harshly when they occur earlier in a document. Second, when the altered sentence is surrounded by topically unrelated context, it systematically lowers similarity scores and induces bipolarized scores that indicate either very low or very high similarity. This is consistent with an interpretive frame account in which topically-related context may allow models to contextualize and downweight the alterations. Third, each LLM produces a qualitatively distinct scoring distribution, a stable "fingerprint" that is invariant to perturbation type, yet all models share a universal hierarchy in how leniently they treat different perturbation types. Together, these results demonstrate that LLM semantic similarity scores are sensitive to document structure, context coherence, and model identity in ways that go beyond the semantic change itself, and that the proposed framework offers a practical, LLM-agnostic toolkit for auditing and comparing scoring behavior across current and future models.
NukeLM: Pre-Trained and Fine-Tuned Language Models for the Nuclear and Energy Domains
May 25, 2021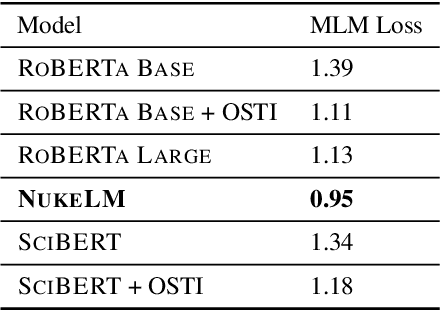
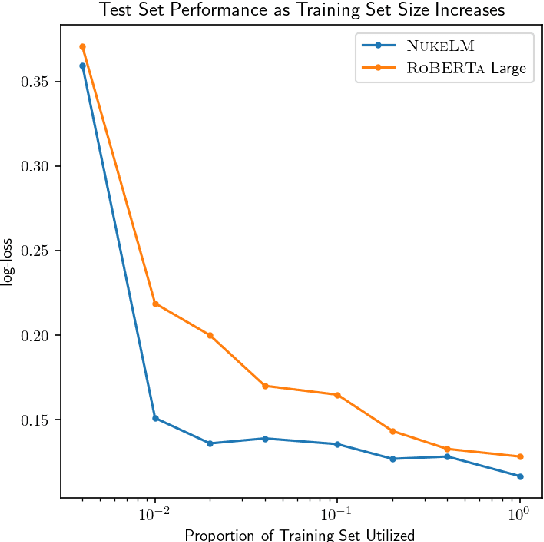
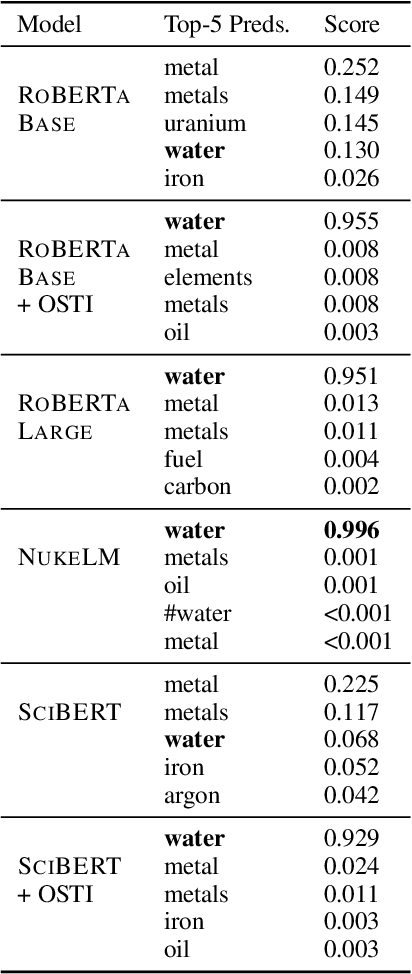
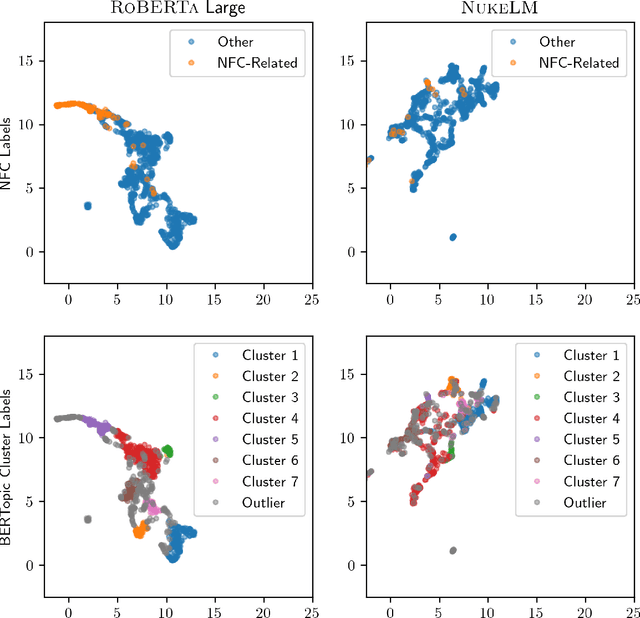
Natural language processing (NLP) tasks (text classification, named entity recognition, etc.) have seen revolutionary improvements over the last few years. This is due to language models such as BERT that achieve deep knowledge transfer by using a large pre-trained model, then fine-tuning the model on specific tasks. The BERT architecture has shown even better performance on domain-specific tasks when the model is pre-trained using domain-relevant texts. Inspired by these recent advancements, we have developed NukeLM, a nuclear-domain language model pre-trained on 1.5 million abstracts from the U.S. Department of Energy Office of Scientific and Technical Information (OSTI) database. This NukeLM model is then fine-tuned for the classification of research articles into either binary classes (related to the nuclear fuel cycle [NFC] or not) or multiple categories related to the subject of the article. We show that continued pre-training of a BERT-style architecture prior to fine-tuning yields greater performance on both article classification tasks. This information is critical for properly triaging manuscripts, a necessary task for better understanding citation networks that publish in the nuclear space, and for uncovering new areas of research in the nuclear (or nuclear-relevant) domains.