 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Approaches to Automated Flow Cytometry Diagnosis of Chronic Lymphocytic Leukemia
Jul 22, 2021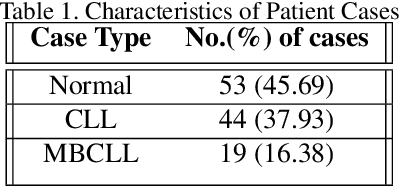
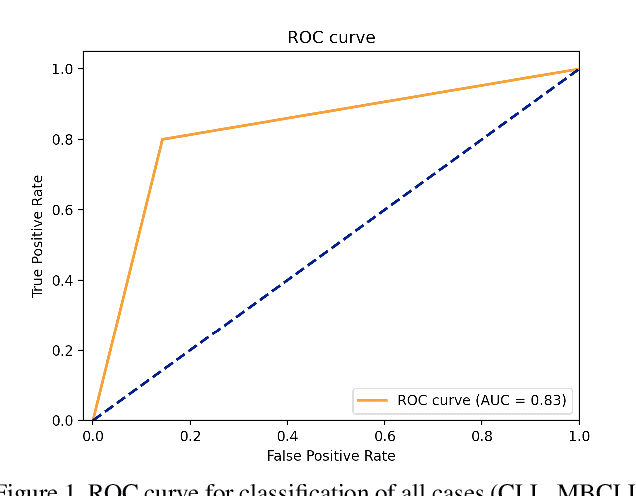
Flow cytometry is a technique that measures multiple fluorescence and light scatter-associated parameters from individual cells as they flow a single file through an excitation light source. These cells are labeled with antibodies to detect various antigens and the fluorescence signals reflect antigen expression. Interpretation of the multiparameter flow cytometry data is laborious, time-consuming, and expensive. It involves manual interpretation of cell distribution and pattern recognition on two-dimensional plots by highly trained medical technologists and pathologists. Using various machine learning algorithms, we attempted to develop an automated analysis for clinical flow cytometry cases that would automatically classify normal and chronic lymphocytic leukemia cases. We achieved the best success with the Gradient Boosting. The XGBoost classifier achieved a specificity of 1.00 and a sensitivity of 0.67, a negative predictive value of 0.75, a positive predictive value of 1.00, and an overall accuracy of 0.83 in prospectively classifying cases with malignancies.
Lung and Colon Cancer Histopathological Image Dataset (LC25000)
Dec 16, 2019The field of Machine Learning, a subset of Artificial Intelligence, has led to remarkable advancements in many areas, including medicine. Machine Learning algorithms require large datasets to train computer models successfully. Although there are medical image datasets available, more image datasets are needed from a variety of medical entities, especially cancer pathology. Even more scarce are ML-ready image datasets. To address this need, we created an image dataset (LC25000) with 25,000 color images in 5 classes. Each class contains 5,000 images of the following histologic entities: colon adenocarcinoma, benign colonic tissue, lung adenocarcinoma, lung squamous cell carcinoma, and benign lung tissue. All images are de-identified, HIPAA compliant, validated, and freely available for download to AI researchers.