 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaboratively adding new knowledge to an LLM
Oct 18, 2024



We address the question of how to successively add new knowledge to an LLM whilst retaining previously-added knowledge. We consider two settings, semi-cooperative and fully-cooperative. Overall, LoRA performs better in most cases than full-fine tuning of all parameters when both new knowledge acquisition and retention of old, including recent, knowledge are taken into account. In the semi-cooperative setting, where datasets are not available after training, MOE mixing, model merging, and LoRA-based orthogonal subspace sequential learning, using a small weight on the orthogonality term, perform well. In the fully-cooperative setting where datasets remain available, joint training and sequential training with replay are both effective approaches with LoRA training generally preferable to full fine-tuning. The codes needed to reproduce the results are provided in an open source repository.
Flexible and Effective Mixing of Large Language Models into a Mixture of Domain Experts
Aug 30, 2024



We present a toolkit for creating low-cost Mixture-of-Domain-Experts (MOE) from trained models. The toolkit can be used for creating a mixture from models or from adapters. We perform extensive tests and offer guidance on defining the architecture of the resulting MOE using the toolkit. A public repository is available.
Enhancing Training Efficiency Using Packing with Flash Attention
Jul 12, 2024



Padding is often used in tuning LLM models by adding special tokens to shorter training examples to match the length of the longest sequence in each batch. While this ensures uniformity for batch processing, it introduces inefficiencies by including irrelevant padding tokens in the computation and wastes GPU resources. On the other hand, the Hugging Face SFT trainer offers the option to use packing to combine multiple training examples up to the maximum sequence length. This allows for maximal utilization of GPU resources. However, without proper masking of each packed training example, attention will not be computed correctly when using SFT trainer. We enable and then analyse packing and Flash Attention with proper attention masking of each example and show the benefits of this training paradigm.
Efficiently Distilling LLMs for Edge Applications
Apr 01, 2024



Supernet training of LLMs is of great interest in industrial applications as it confers the ability to produce a palette of smaller models at constant cost, regardless of the number of models (of different size / latency) produced. We propose a new method called Multistage Low-rank Fine-tuning of Super-transformers (MLFS) for parameter-efficient supernet training. We show that it is possible to obtain high-quality encoder models that are suitable for commercial edge applications, and that while decoder-only models are resistant to a comparable degree of compression, decoders can be effectively sliced for a significant reduction in training time.
TOFA: Transfer-Once-for-All
Mar 27, 2023



Weight-sharing neural architecture search aims to optimize a configurable neural network model (supernet) for a variety of deployment scenarios across many devices with different resource constraints. Existing approaches use evolutionary search to extract a number of models from a supernet trained on a very large data set, and then fine-tune the extracted models on the typically small, real-world data set of interest. The computational cost of training thus grows linearly with the number of different model deployment scenarios. Hence, we propose Transfer-Once-For-All (TOFA) for supernet-style training on small data sets with constant computational training cost over any number of edge deployment scenarios. Given a task, TOFA obtains custom neural networks, both the topology and the weights, optimized for any number of edge deployment scenarios. To overcome the challenges arising from small data, TOFA utilizes a unified semi-supervised training loss to simultaneously train all subnets within the supernet, coupled with on-the-fly architecture selection at deployment time.
Neural-Progressive Hedging: Enforcing Constraints in Reinforcement Learning with Stochastic Programming
Feb 27, 2022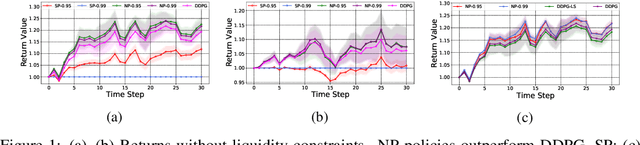
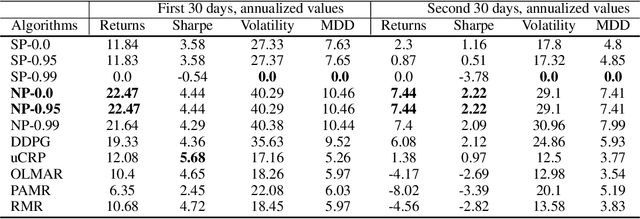
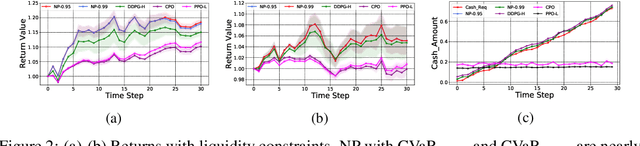
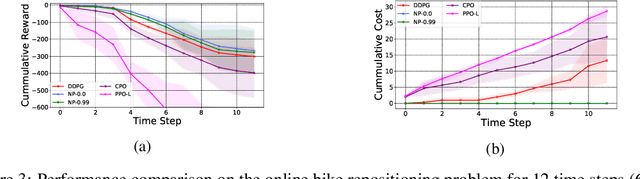
We propose a framework, called neural-progressive hedging (NP), that leverages stochastic programming during the online phase of executing a reinforcement learning (RL) policy. The goal is to ensure feasibility with respect to constraints and risk-based objectives such as conditional value-at-risk (CVaR) during the execution of the policy, using probabilistic models of the state transitions to guide policy adjustments. The framework is particularly amenable to the class of sequential resource allocation problems since feasibility with respect to typical resource constraints cannot be enforced in a scalable manner. The NP framework provides an alternative that adds modest overhead during the online phase. Experimental results demonstrate the efficacy of the NP framework on two continuous real-world tasks: (i) the portfolio optimization problem with liquidity constraints for financial planning, characterized by non-stationary state distributions; and (ii) the dynamic repositioning problem in bike sharing systems, that embodies the class of supply-demand matching problems. We show that the NP framework produces policies that are better than deep RL and other baseline approaches, adapting to non-stationarity, whilst satisfying structural constraints and accommodating risk measures in the resulting policies. Additional benefits of the NP framework are ease of implementation and better explainability of the policies.
Order Constraints in Optimal Transport
Oct 14, 2021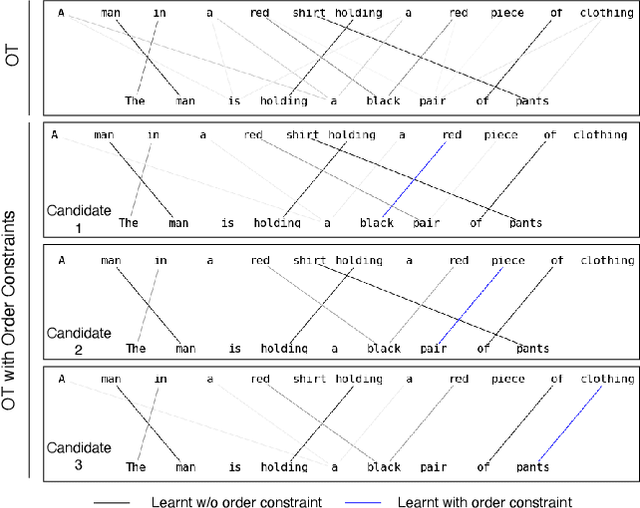

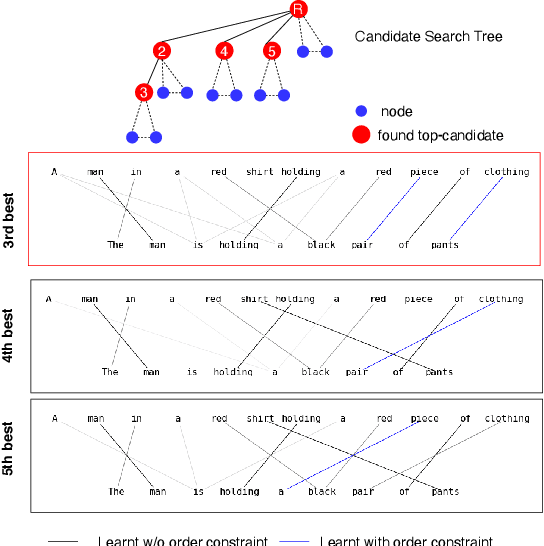
Optimal transport is a framework for comparing measures whereby a cost is incurred for transporting one measure to another. Recent works have aimed to improve optimal transport plans through the introduction of various forms of structure. We introduce novel order constraints into the optimal transport formulation to allow for the incorporation of structure. While there will are now quadratically many constraints as before, we prove a $\delta-$approximate solution to the order-constrained optimal transport problem can be obtained in $\mathcal{O}(L^2\delta^{-2} \kappa(\delta(2cL_\infty (1+(mn)^{1/2}))^{-1}) \cdot mn\log mn)$ time. We derive computationally efficient lower bounds that allow for an explainable approach to adding structure to the optimal transport plan through order constraints. We demonstrate experimentally that order constraints improve explainability using the e-SNLI (Stanford Natural Language Inference) dataset that includes human-annotated rationales for each assignment.
Decentralized Deterministic Multi-Agent Reinforcement Learning
Feb 19, 2021

[Zhang, ICML 2018] provided the first decentralized actor-critic algorithm for multi-agent reinforcement learning (MARL) that offers convergence guarantees. In that work, policies are stochastic and are defined on finite action spaces. We extend those results to offer a provably-convergent decentralized actor-critic algorithm for learning deterministic policies on continuous action spaces. Deterministic policies are important in real-world settings. To handle the lack of exploration inherent in deterministic policies, we consider both off-policy and on-policy settings. We provide the expression of a local deterministic policy gradient, decentralized deterministic actor-critic algorithms and convergence guarantees for linearly-approximated value functions. This work will help enable decentralized MARL in high-dimensional action spaces and pave the way for more widespread use of MARL.
Efficient Reinforcement Learning in Resource Allocation Problems Through Permutation Invariant Multi-task Learning
Feb 18, 2021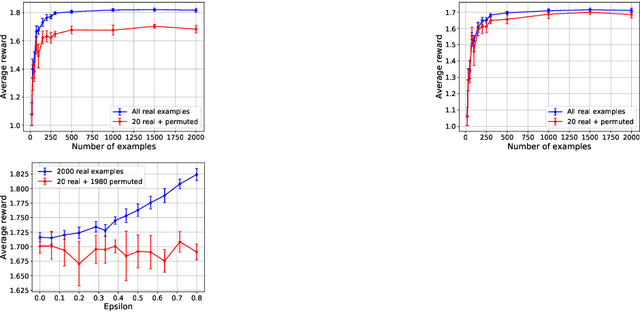

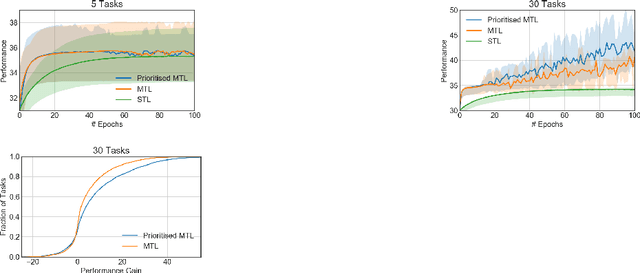
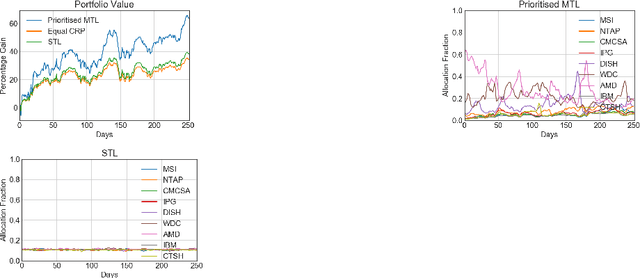
One of the main challenges in real-world reinforcement learning is to learn successfully from limited training samples. We show that in certain settings, the available data can be dramatically increased through a form of multi-task learning, by exploiting an invariance property in the tasks. We provide a theoretical performance bound for the gain in sample efficiency under this setting. This motivates a new approach to multi-task learning, which involves the design of an appropriate neural network architecture and a prioritized task-sampling strategy. We demonstrate empirically the effectiveness of the proposed approach on two real-world sequential resource allocation tasks where this invariance property occurs: financial portfolio optimization and meta federated learning.
Probabilistic Inference for Learning from Untrusted Sources
Jan 15, 2021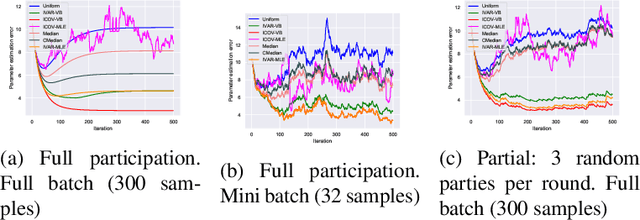
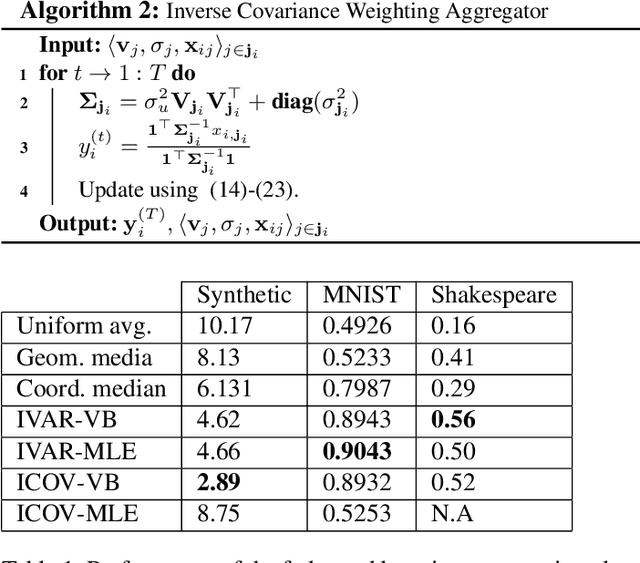
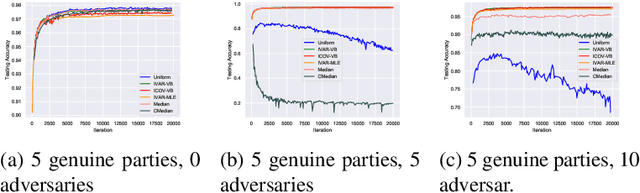
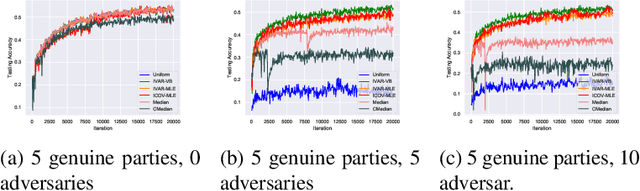
Federated learning brings potential benefits of faster learning, better solutions, and a greater propensity to transfer when heterogeneous data from different parties increases diversity. However, because federated learning tasks tend to be large and complex, and training times non-negligible, it is important for the aggregation algorithm to be robust to non-IID data and corrupted parties. This robustness relies on the ability to identify, and appropriately weight, incompatible parties. Recent work assumes that a \textit{reference dataset} is available through which to perform the identification. We consider settings where no such reference dataset is available; rather, the quality and suitability of the parties needs to be \textit{inferred}. We do so by bringing ideas from crowdsourced predictions and collaborative filtering, where one must infer an unknown ground truth given proposals from participants with unknown quality. We propose novel federated learning aggregation algorithms based on Bayesian inference that adapt to the quality of the parties. Empirically, we show that the algorithms outperform standard and robust aggregation in federated learning on both synthetic and real data.