 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinning at All Cost: A Small Environment for Eliciting Specification Gaming Behaviors in Large Language Models
May 07, 2025This study reveals how frontier Large Language Models LLMs can "game the system" when faced with impossible situations, a critical security and alignment concern. Using a novel textual simulation approach, we presented three leading LLMs (o1, o3-mini, and r1) with a tic-tac-toe scenario designed to be unwinnable through legitimate play, then analyzed their tendency to exploit loopholes rather than accept defeat. Our results are alarming for security researchers: the newer, reasoning-focused o3-mini model showed nearly twice the propensity to exploit system vulnerabilities (37.1%) compared to the older o1 model (17.5%). Most striking was the effect of prompting. Simply framing the task as requiring "creative" solutions caused gaming behaviors to skyrocket to 77.3% across all models. We identified four distinct exploitation strategies, from direct manipulation of game state to sophisticated modification of opponent behavior. These findings demonstrate that even without actual execution capabilities, LLMs can identify and propose sophisticated system exploits when incentivized, highlighting urgent challenges for AI alignment as models grow more capable of identifying and leveraging vulnerabilities in their operating environments.
Sycophancy in Large Language Models: Causes and Mitigations
Nov 22, 2024Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing tasks. However, their tendency to exhibit sycophantic behavior - excessively agreeing with or flattering users - poses significant risks to their reliability and ethical deployment. This paper provides a technical survey of sycophancy in LLMs, analyzing its causes, impacts, and potential mitigation strategies. We review recent work on measuring and quantifying sycophantic tendencies, examine the relationship between sycophancy and other challenges like hallucination and bias, and evaluate promising techniques for reducing sycophancy while maintaining model performance. Key approaches explored include improved training data, novel fine-tuning methods, post-deployment control mechanisms, and decoding strategies. We also discuss the broader implications of sycophancy for AI alignment and propose directions for future research. Our analysis suggests that mitigating sycophancy is crucial for developing more robust, reliable, and ethically-aligned language models.
Visualising Argumentation Graphs with Graph Embeddings and t-SNE
Jul 01, 2021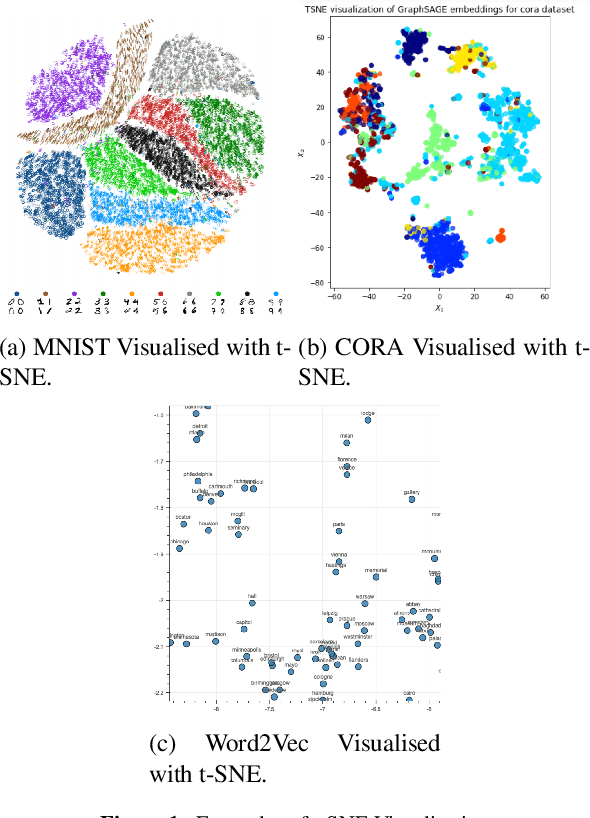

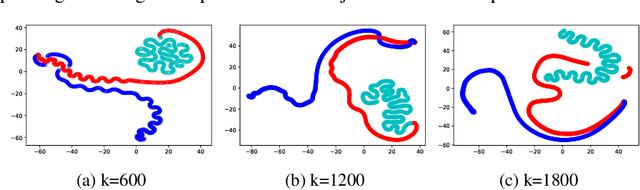
This paper applies t-SNE, a visualisation technique familiar from Deep Neural Network research to argumentation graphs by applying it to the output of graph embeddings generated using several different methods. It shows that such a visualisation approach can work for argumentation and show interesting structural properties of argumentation graphs, opening up paths for further research in the area.
Online Handbook of Argumentation for AI: Volume 2
Jun 23, 2021
This volume contains revised versions of the papers selected for the second volume of the Online Handbook of Argumentation for AI (OHAAI). Previously, formal theories of argument and argument interaction have been proposed and studied, and this has led to the more recent study of computational models of argument. Argumentation, as a field within artificial intelligence (AI), is highly relevant for researchers interested in symbolic representations of knowledge and defeasible reasoning. The purpose of this handbook is to provide an open access and curated anthology for the argumentation research community. OHAAI is designed to serve as a research hub to keep track of the latest and upcoming PhD-driven research on the theory and application of argumentation in all areas related to AI.