 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuxiliary Deep Generative Models
Jun 16, 2016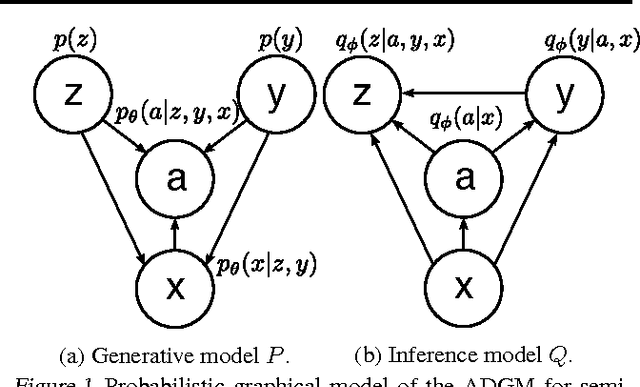
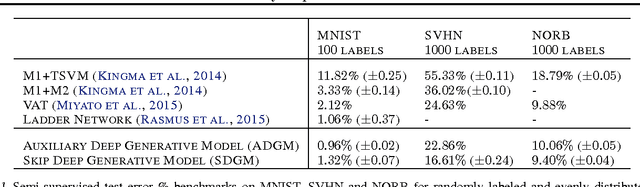
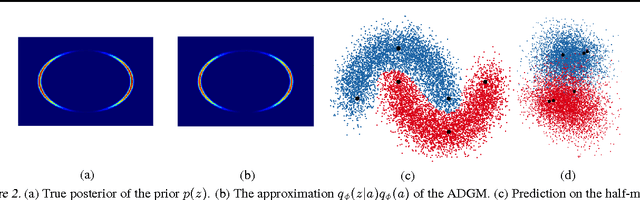

Deep generative models parameterized by neural networks have recently achieved state-of-the-art performance in unsupervised and semi-supervised learning. We extend deep generative models with auxiliary variables which improves the variational approximation. The auxiliary variables leave the generative model unchanged but make the variational distribution more expressive. Inspired by the structure of the auxiliary variable we also propose a model with two stochastic layers and skip connections. Our findings suggest that more expressive and properly specified deep generative models converge faster with better results. We show state-of-the-art performance within semi-supervised learning on MNIST, SVHN and NORB datasets.
Ladder Variational Autoencoders
May 27, 2016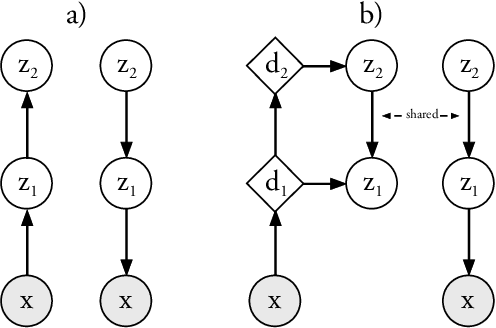

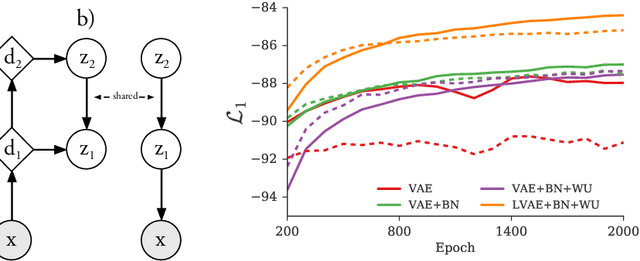
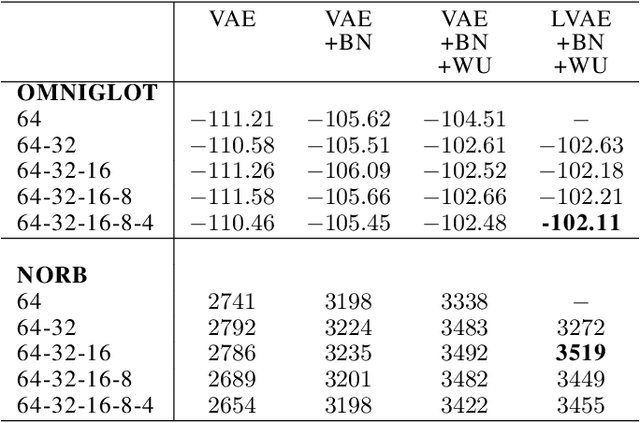
Variational Autoencoders are powerful models for unsupervised learning. However deep models with several layers of dependent stochastic variables are difficult to train which limits the improvements obtained using these highly expressive models. We propose a new inference model, the Ladder Variational Autoencoder, that recursively corrects the generative distribution by a data dependent approximate likelihood in a process resembling the recently proposed Ladder Network. We show that this model provides state of the art predictive log-likelihood and tighter log-likelihood lower bound compared to the purely bottom-up inference in layered Variational Autoencoders and other generative models. We provide a detailed analysis of the learned hierarchical latent representation and show that our new inference model is qualitatively different and utilizes a deeper more distributed hierarchy of latent variables. Finally, we observe that batch normalization and deterministic warm-up (gradually turning on the KL-term) are crucial for training variational models with many stochastic layers.
Recurrent Spatial Transformer Networks
Sep 17, 2015
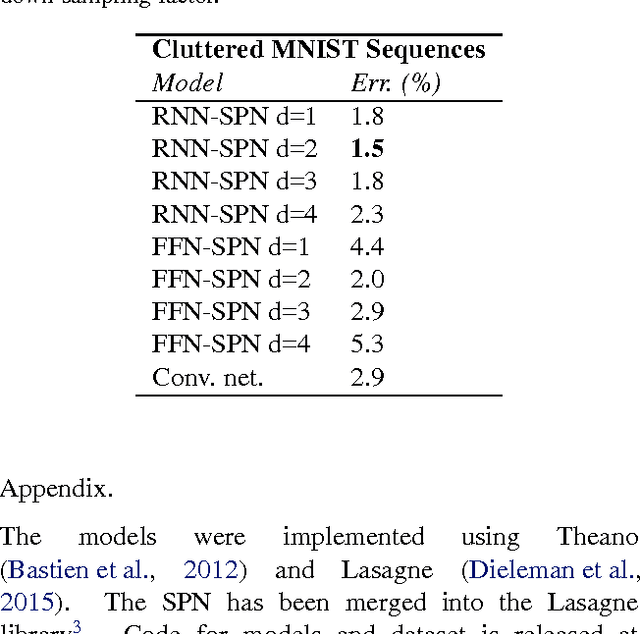

We integrate the recently proposed spatial transformer network (SPN) [Jaderberg et. al 2015] into a recurrent neural network (RNN) to form an RNN-SPN model. We use the RNN-SPN to classify digits in cluttered MNIST sequences. The proposed model achieves a single digit error of 1.5% compared to 2.9% for a convolutional networks and 2.0% for convolutional networks with SPN layers. The SPN outputs a zoomed, rotated and skewed version of the input image. We investigate different down-sampling factors (ratio of pixel in input and output) for the SPN and show that the RNN-SPN model is able to down-sample the input images without deteriorating performance. The down-sampling in RNN-SPN can be thought of as adaptive down-sampling that minimizes the information loss in the regions of interest. We attribute the superior performance of the RNN-SPN to the fact that it can attend to a sequence of regions of interest.