 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARBITER: Reasoning Trajectory Basins and Majority Vote Failures in Test-Time Sampling
May 25, 2026When language models use test-time sampling, they generate multiple reasoning trajectories and select an answer by majority vote. We show that these trajectories are not independent: for a given question, they concentrate into a small number of clusters, or reasoning basins, each defined by a normalized final answer and the solutions that reach it. A majority vote therefore selects the most stable basin rather than the most accurate one, which creates wrong-majority failures where the correct answer is present but outvoted. We introduce ARBITER, a model-agnostic approach that models interactions between basins using only the base model's own sampled outputs, hidden states, and derived evidence. Most direct correction strategies fail; ARBITER instead uses conservative additive evidence on top of consensus. In its simplest parameter-free form, ARBITER-Δ adds same-model evidence to the majority prior, while ARBITER-Enc augments this with bounded residual signals from hidden states over complete solutions. On GSM8K with Qwen3-4B, consensus over K=24 samples achieves around the mid-94% range, while a same-pool top-2 oracle reaches around the mid-96% range. ARBITER recovers a subset of these cases using zero external information. Across three model families and three math benchmarks, it yields consistent gains with no net-negative cases; for example, on Llama-3.1-8B MMLU-HS-Math, it improves accuracy from the mid-78% range to the mid-82% range, recovering about 22% of the available oracle headroom, indicating that this headroom can be partially recovered from the sample pool itself.
Fast, Accurate and Interpretable Time Series Classification Through Randomization
May 31, 2021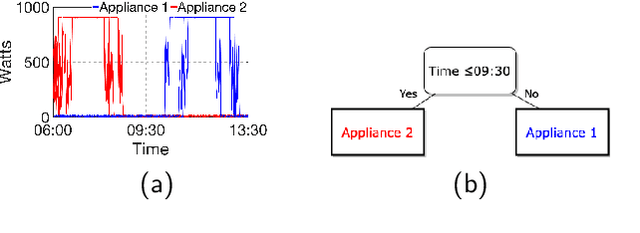
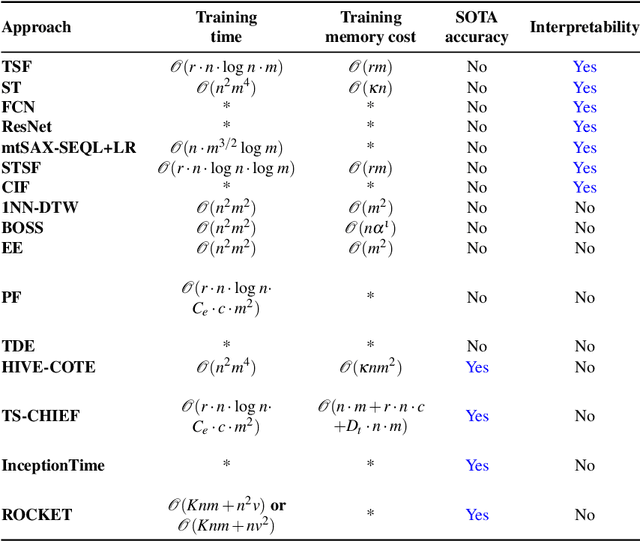
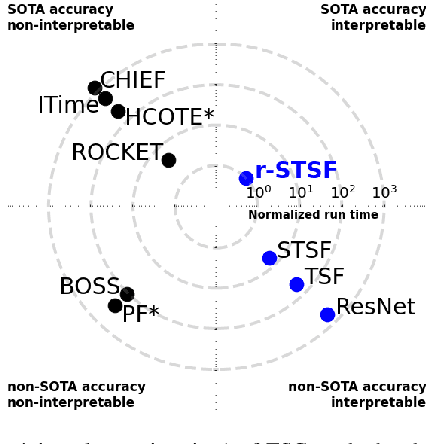

Time series classification (TSC) aims to predict the class label of a given time series, which is critical to a rich set of application areas such as economics and medicine. State-of-the-art TSC methods have mostly focused on classification accuracy and efficiency, without considering the interpretability of their classifications, which is an important property required by modern applications such as appliance modeling and legislation such as the European General Data Protection Regulation. To address this gap, we propose a novel TSC method - the Randomized-Supervised Time Series Forest (r-STSF). r-STSF is highly efficient, achieves state-of-the-art classification accuracy and enables interpretability. r-STSF takes an efficient interval-based approach to classify time series according to aggregate values of discriminatory sub-series (intervals). To achieve state-of-the-art accuracy, r-STSF builds an ensemble of randomized trees using the discriminatory sub-series. It uses four time series representations, nine aggregation functions and a supervised binary-inspired search combined with a feature ranking metric to identify highly discriminatory sub-series. The discriminatory sub-series enable interpretable classifications. Experiments on extensive datasets show that r-STSF achieves state-of-the-art accuracy while being orders of magnitude faster than most existing TSC methods. It is the only classifier from the state-of-the-art group that enables interpretability. Our findings also highlight that r-STSF is the best TSC method when classifying complex time series datasets.