 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Learning of Heterogeneous Concepts in Videos
Jul 12, 2016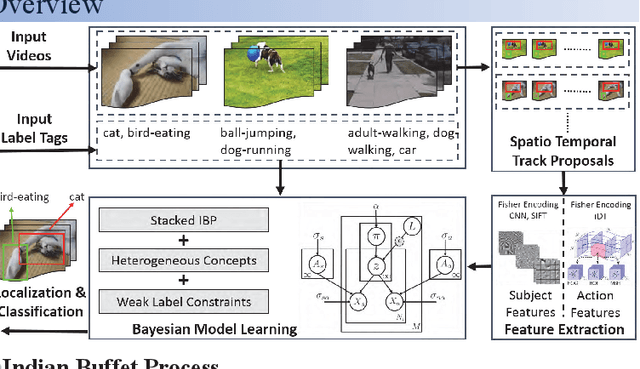
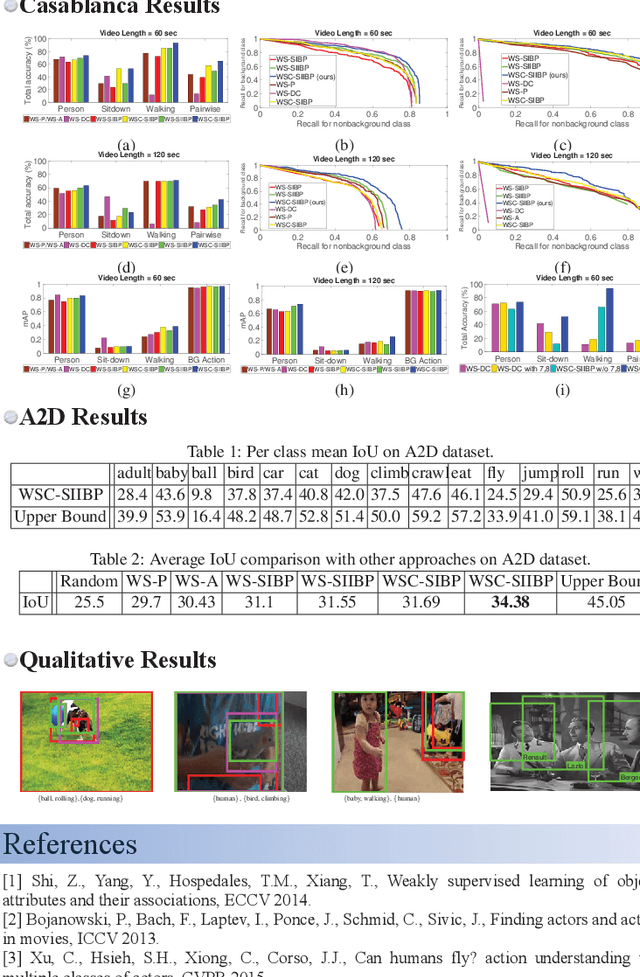
Typical textual descriptions that accompany online videos are 'weak': i.e., they mention the main concepts in the video but not their corresponding spatio-temporal locations. The concepts in the description are typically heterogeneous (e.g., objects, persons, actions). Certain location constraints on these concepts can also be inferred from the description. The goal of this paper is to present a generalization of the Indian Buffet Process (IBP) that can (a) systematically incorporate heterogeneous concepts in an integrated framework, and (b) enforce location constraints, for efficient classification and localization of the concepts in the videos. Finally, we develop posterior inference for the proposed formulation using mean-field variational approximation. Comparative evaluations on the Casablanca and the A2D datasets show that the proposed approach significantly outperforms other state-of-the-art techniques: 24% relative improvement for pairwise concept classification in the Casablanca dataset and 9% relative improvement for localization in the A2D dataset as compared to the most competitive baseline.
Learning Discriminative Features via Label Consistent Neural Network
Jun 05, 2016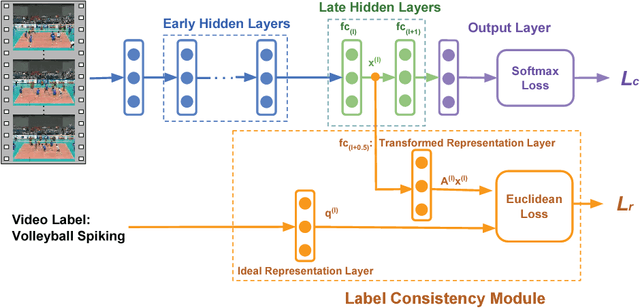
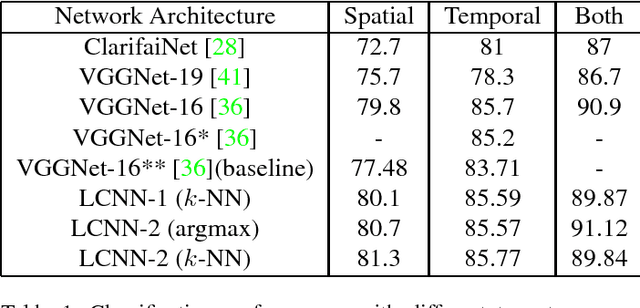

Deep Convolutional Neural Networks (CNN) enforces supervised information only at the output layer, and hidden layers are trained by back propagating the prediction error from the output layer without explicit supervision. We propose a supervised feature learning approach, Label Consistent Neural Network, which enforces direct supervision in late hidden layers. We associate each neuron in a hidden layer with a particular class label and encourage it to be activated for input signals from the same class. More specifically, we introduce a label consistency regularization called "discriminative representation error" loss for late hidden layers and combine it with classification error loss to build our overall objective function. This label consistency constraint alleviates the common problem of gradient vanishing and tends to faster convergence; it also makes the features derived from late hidden layers discriminative enough for classification even using a simple $k$-NN classifier, since input signals from the same class will have very similar representations. Experimental results demonstrate that our approach achieves state-of-the-art performances on several public benchmarks for action and object category recognition.
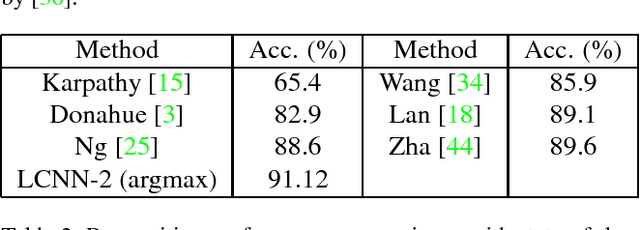
Learning Structured Ordinal Measures for Video based Face Recognition
Jul 09, 2015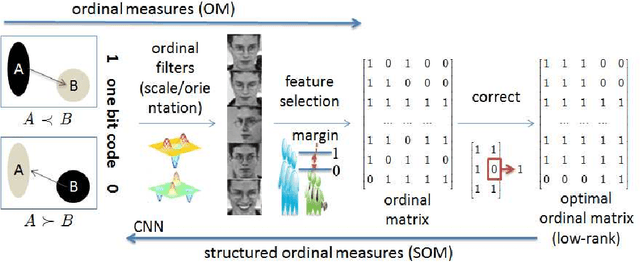

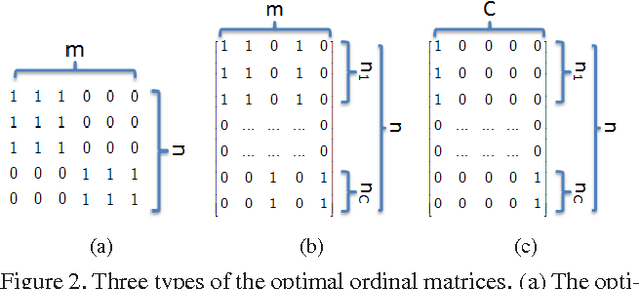

This paper presents a structured ordinal measure method for video-based face recognition that simultaneously learns ordinal filters and structured ordinal features. The problem is posed as a non-convex integer program problem that includes two parts. The first part learns stable ordinal filters to project video data into a large-margin ordinal space. The second seeks self-correcting and discrete codes by balancing the projected data and a rank-one ordinal matrix in a structured low-rank way. Unsupervised and supervised structures are considered for the ordinal matrix. In addition, as a complement to hierarchical structures, deep feature representations are integrated into our method to enhance coding stability. An alternating minimization method is employed to handle the discrete and low-rank constraints, yielding high-quality codes that capture prior structures well. Experimental results on three commonly used face video databases show that our method with a simple voting classifier can achieve state-of-the-art recognition rates using fewer features and samples.