 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Life Gives You BC, Make Q-functions: Extracting Q-values from Behavior Cloning for On-Robot Reinforcement Learning
May 06, 2026Behavior Cloning (BC) has emerged as a highly effective paradigm for robot learning. However, BC lacks a self-guided mechanism for online improvement after demonstrations have been collected. Existing offline-to-online learning methods often cause policies to replace previously learned good actions due to a distribution mismatch between offline data and online learning. In this work, we propose Q2RL, Q-Estimation and Q-Gating from BC for Reinforcement Learning, an algorithm for efficient offline-to-online learning. Our method consists of two parts: (1) Q-Estimation extracts a Q-function from a BC policy using a few interaction steps with the environment, followed by online RL with (2) Q-Gating, which switches between BC and RL policy actions based on their respective Q-values to collect samples for RL policy training. Across manipulation tasks from D4RL and robomimic benchmarks, Q2RL outperforms SOTA offline-to-online learning baselines on success rate and time to convergence. Q2RL is efficient enough to be applied in an on-robot RL setting, learning robust policies for contact-rich and high precision manipulation tasks such as pipe assembly and kitting, in 1-2 hours of online interaction, achieving success rates of up to 100% and up to 3.75x improvement against the original BC policy. Code and video are available at https://pages.rai-inst.com/q2rl_website/
Towards the design of user-centric strategy recommendation systems for collaborative Human-AI tasks
Jan 17, 2023



Artificial Intelligence is being employed by humans to collaboratively solve complicated tasks for search and rescue, manufacturing, etc. Efficient teamwork can be achieved by understanding user preferences and recommending different strategies for solving the particular task to humans. Prior work has focused on personalization of recommendation systems for relatively well-understood tasks in the context of e-commerce or social networks. In this paper, we seek to understand the important factors to consider while designing user-centric strategy recommendation systems for decision-making. We conducted a human-subjects experiment (n=60) for measuring the preferences of users with different personality types towards different strategy recommendation systems. We conducted our experiment across four types of strategy recommendation modalities that have been established in prior work: (1) Single strategy recommendation, (2) Multiple similar recommendations, (3) Multiple diverse recommendations, (4) All possible strategies recommendations. While these strategy recommendation schemes have been explored independently in prior work, our study is novel in that we employ all of them simultaneously and in the context of strategy recommendations, to provide us an in-depth overview of the perception of different strategy recommendation systems. We found that certain personality traits, such as conscientiousness, notably impact the preference towards a particular type of system (p < 0.01). Finally, we report an interesting relationship between usability, alignment and perceived intelligence wherein greater perceived alignment of recommendations with one's own preferences leads to higher perceived intelligence (p < 0.01) and higher usability (p < 0.01).
Commander's Intent: A Dataset and Modeling Approach for Human-AI Task Specification in Strategic Play
Aug 17, 2022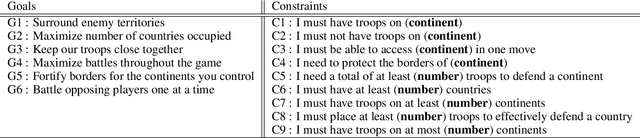
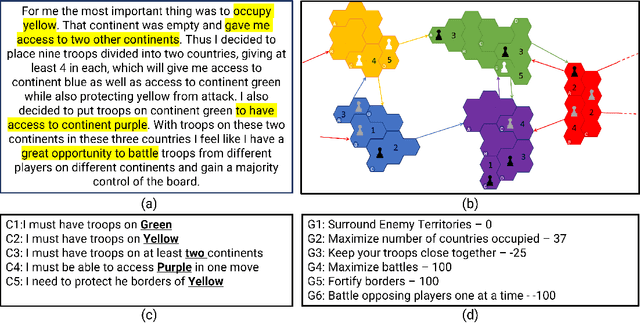
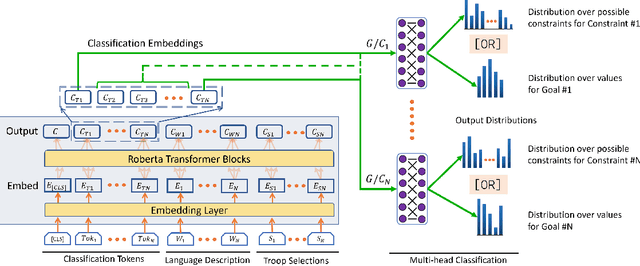
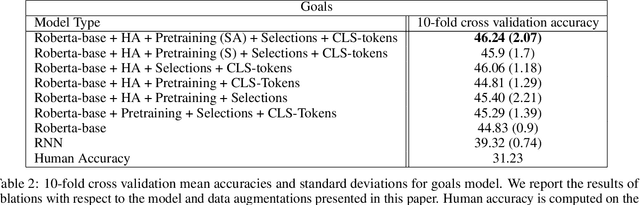
Effective Human-AI teaming requires the ability to communicate the goals of the team and constraints under which you need the agent to operate. Providing the ability to specify the shared intent or operation criteria of the team can enable an AI agent to perform its primary function while still being able to cater to the specific desires of the current team. While significant work has been conducted to instruct an agent to perform a task, via language or demonstrations, prior work lacks a focus on building agents which can operate within the parameters specified by a team. Worse yet, there is a dearth of research pertaining to enabling humans to provide their specifications through unstructured, naturalist language. In this paper, we propose the use of goals and constraints as a scaffold to modulate and evaluate autonomous agents. We contribute to this field by presenting a novel dataset, and an associated data collection protocol, which maps language descriptions to goals and constraints corresponding to specific strategies developed by human participants for the board game Risk. Leveraging state-of-the-art language models and augmentation procedures, we develop a machine learning framework which can be used to identify goals and constraints from unstructured strategy descriptions. To empirically validate our approach we conduct a human-subjects study to establish a human-baseline for our dataset. Our results show that our machine learning architecture is better able to interpret unstructured language descriptions into strategy specifications than human raters tasked with performing the same machine translation task (F(1,272.53) = 17.025, p < 0.001).