 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Symbolic Models of Stochastic Domains
Oct 10, 2011
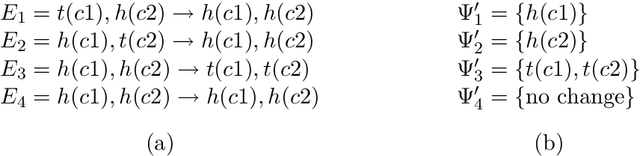
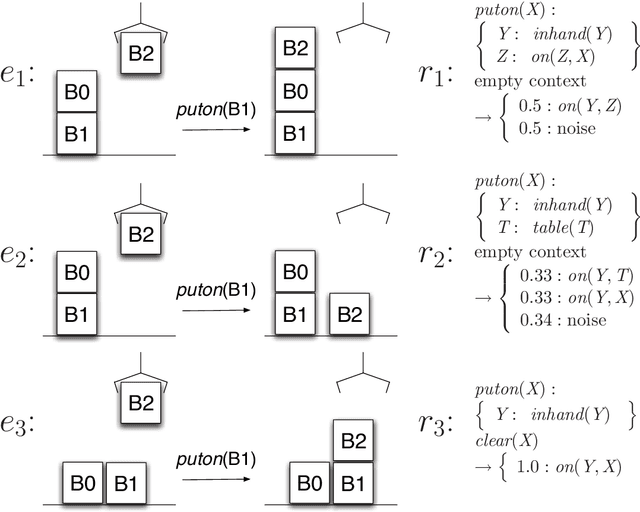

In this article, we work towards the goal of developing agents that can learn to act in complex worlds. We develop a probabilistic, relational planning rule representation that compactly models noisy, nondeterministic action effects, and show how such rules can be effectively learned. Through experiments in simple planning domains and a 3D simulated blocks world with realistic physics, we demonstrate that this learning algorithm allows agents to effectively model world dynamics.
Learning Geometrically-Constrained Hidden Markov Models for Robot Navigation: Bridging the Topological-Geometrical Gap
Jun 03, 2011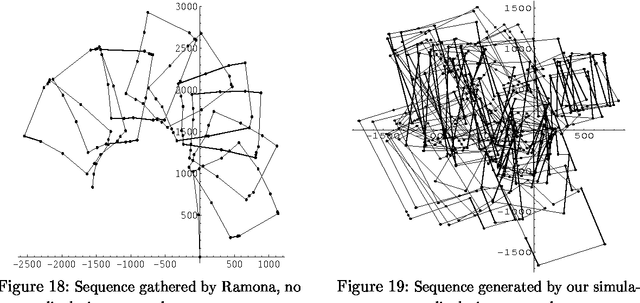
Hidden Markov models (HMMs) and partially observable Markov decision processes (POMDPs) provide useful tools for modeling dynamical systems. They are particularly useful for representing the topology of environments such as road networks and office buildings, which are typical for robot navigation and planning. The work presented here describes a formal framework for incorporating readily available odometric information and geometrical constraints into both the models and the algorithm that learns them. By taking advantage of such information, learning HMMs/POMDPs can be made to generate better solutions and require fewer iterations, while being robust in the face of data reduction. Experimental results, obtained from both simulated and real robot data, demonstrate the effectiveness of the approach.
Reinforcement Learning: A Survey
May 01, 1996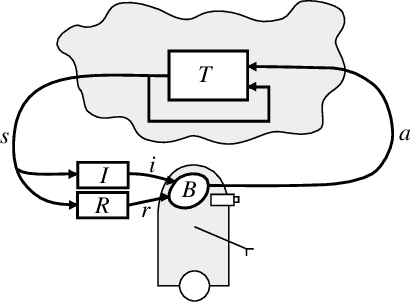
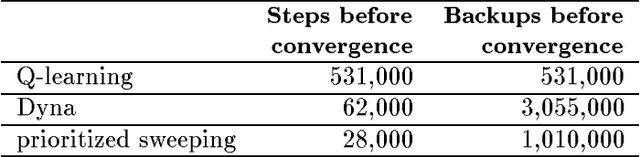
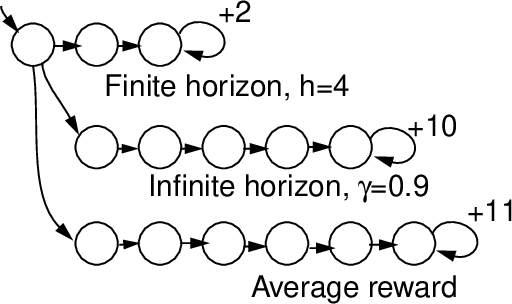
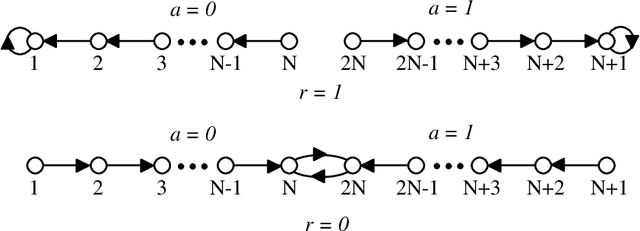
This paper surveys the field of reinforcement learning from a computer-science perspective. It is written to be accessible to researchers familiar with machine learning. Both the historical basis of the field and a broad selection of current work are summarized. Reinforcement learning is the problem faced by an agent that learns behavior through trial-and-error interactions with a dynamic environment. The work described here has a resemblance to work in psychology, but differs considerably in the details and in the use of the word ``reinforcement.'' The paper discusses central issues of reinforcement learning, including trading off exploration and exploitation, establishing the foundations of the field via Markov decision theory, learning from delayed reinforcement, constructing empirical models to accelerate learning, making use of generalization and hierarchy, and coping with hidden state. It concludes with a survey of some implemented systems and an assessment of the practical utility of current methods for reinforcement learning.
* See http://www.jair.org/ for any accompanying files