 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLANet: A Lane Boundaries-Aware Approach For Robust Trajectory Prediction
Jul 02, 2025Accurate motion forecasting is critical for safe and efficient autonomous driving, enabling vehicles to predict future trajectories and make informed decisions in complex traffic scenarios. Most of the current designs of motion prediction models are based on the major representation of lane centerlines, which limits their capability to capture critical road environments and traffic rules and constraints. In this work, we propose an enhanced motion forecasting model informed by multiple vector map elements, including lane boundaries and road edges, that facilitates a richer and more complete representation of driving environments. An effective feature fusion strategy is developed to merge information in different vector map components, where the model learns holistic information on road structures and their interactions with agents. Since encoding more information about the road environment increases memory usage and is computationally expensive, we developed an effective pruning mechanism that filters the most relevant map connections to the target agent, ensuring computational efficiency while maintaining essential spatial and semantic relationships for accurate trajectory prediction. Overcoming the limitations of lane centerline-based models, our method provides a more informative and efficient representation of the driving environment and advances the state of the art for autonomous vehicle motion forecasting. We verify our approach with extensive experiments on the Argoverse 2 motion forecasting dataset, where our method maintains competitiveness on AV2 while achieving improved performance. Index Terms-Autonomous driving, trajectory prediction, vector map elements, road topology, connection pruning, Argoverse 2.
Progressive Query Refinement Framework for Bird's-Eye-View Semantic Segmentation from Surrounding Images
Jul 24, 2024Expressing images with Multi-Resolution (MR) features has been widely adopted in many computer vision tasks. In this paper, we introduce the MR concept into Bird's-Eye-View (BEV) semantic segmentation for autonomous driving. This introduction enhances our model's ability to capture both global and local characteristics of driving scenes through our proposed residual learning. Specifically, given a set of MR BEV query maps, the lowest resolution query map is initially updated using a View Transformation (VT) encoder. This updated query map is then upscaled and merged with a higher resolution query map to undergo further updates in a subsequent VT encoder. This process is repeated until the resolution of the updated query map reaches the target. Finally, the lowest resolution map is added to the target resolution to generate the final query map. During training, we enforce both the lowest and final query maps to align with the ground-truth BEV semantic map to help our model effectively capture the global and local characteristics. We also propose a visual feature interaction network that promotes interactions between features across images and across feature levels, thus highly contributing to the performance improvement. We evaluate our model on a large-scale real-world dataset. The experimental results show that our model outperforms the SOTA models in terms of IoU metric. Codes are available at https://github.com/d1024choi/ProgressiveQueryRefineNet
Hierarchical Latent Structure for Multi-Modal Vehicle Trajectory Forecasting
Jul 11, 2022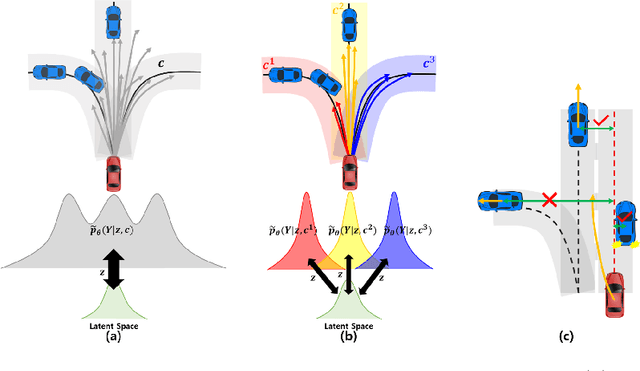

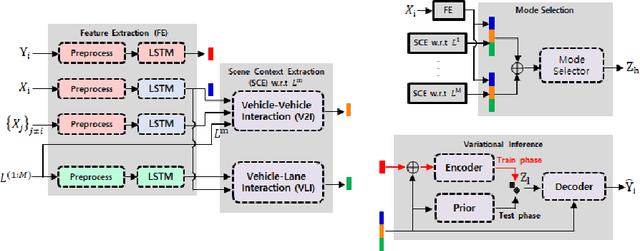
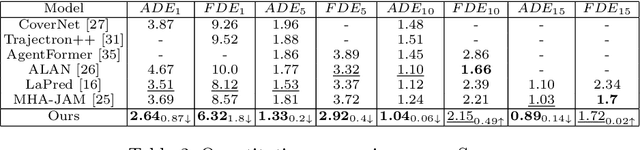
Variational autoencoder (VAE) has widely been utilized for modeling data distributions because it is theoretically elegant, easy to train, and has nice manifold representations. However, when applied to image reconstruction and synthesis tasks, VAE shows the limitation that the generated sample tends to be blurry. We observe that a similar problem, in which the generated trajectory is located between adjacent lanes, often arises in VAE-based trajectory forecasting models. To mitigate this problem, we introduce a hierarchical latent structure into the VAE-based forecasting model. Based on the assumption that the trajectory distribution can be approximated as a mixture of simple distributions (or modes), the low-level latent variable is employed to model each mode of the mixture and the high-level latent variable is employed to represent the weights for the modes. To model each mode accurately, we condition the low-level latent variable using two lane-level context vectors computed in novel ways, one corresponds to vehicle-lane interaction and the other to vehicle-vehicle interaction. The context vectors are also used to model the weights via the proposed mode selection network. To evaluate our forecasting model, we use two large-scale real-world datasets. Experimental results show that our model is not only capable of generating clear multi-modal trajectory distributions but also outperforms the state-of-the-art (SOTA) models in terms of prediction accuracy. Our code is available at https://github.com/d1024choi/HLSTrajForecast.