 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPU: High-Bandwidth Processing Unit for Scalable, Cost-effective LLM Inference via GPU Co-processing
Apr 18, 2025The attention layer, a core component of Transformer-based LLMs, brings out inefficiencies in current GPU systems due to its low operational intensity and the substantial memory requirements of KV caches. We propose a High-bandwidth Processing Unit (HPU), a memoryintensive co-processor that enhances GPU resource utilization during large-batched LLM inference. By offloading memory-bound operations, the HPU allows the GPU to focus on compute-intensive tasks, increasing overall efficiency. Also, the HPU, as an add-on card, scales out to accommodate surging memory demands driven by large batch sizes and extended sequence lengths. In this paper, we show the HPU prototype implemented with PCIe-based FPGA cards mounted on a GPU system. Our novel GPU-HPU heterogeneous system demonstrates up to 4.1x performance gains and 4.6x energy efficiency improvements over a GPUonly system, providing scalability without increasing the number of GPUs.
A$^3$: Accelerating Attention Mechanisms in Neural Networks with Approximation
Feb 22, 2020
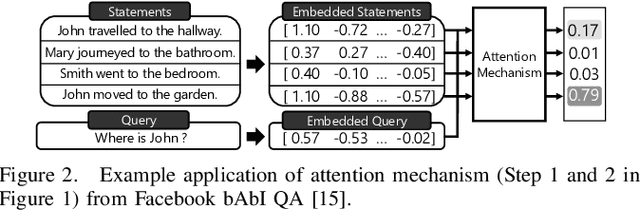
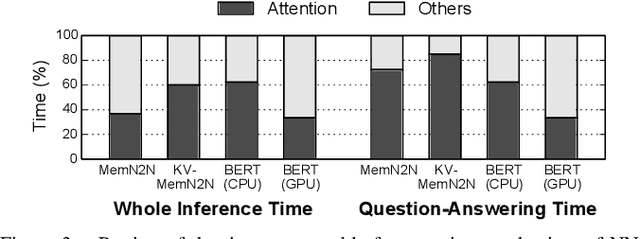

With the increasing computational demands of neural networks, many hardware accelerators for the neural networks have been proposed. Such existing neural network accelerators often focus on popular neural network types such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs); however, not much attention has been paid to attention mechanisms, an emerging neural network primitive that enables neural networks to retrieve most relevant information from a knowledge-base, external memory, or past states. The attention mechanism is widely adopted by many state-of-the-art neural networks for computer vision, natural language processing, and machine translation, and accounts for a large portion of total execution time. We observe today's practice of implementing this mechanism using matrix-vector multiplication is suboptimal as the attention mechanism is semantically a content-based search where a large portion of computations ends up not being used. Based on this observation, we design and architect A3, which accelerates attention mechanisms in neural networks with algorithmic approximation and hardware specialization. Our proposed accelerator achieves multiple orders of magnitude improvement in energy efficiency (performance/watt) as well as substantial speedup over the state-of-the-art conventional hardware.