 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Model Cascades for Semantic SQL
Apr 01, 2026Modern data warehouses extend SQL with semantic operators that invoke large language models on each qualifying row, but the per-row inference cost is prohibitive at scale. Model cascades reduce this cost by routing most rows through a fast proxy model and delegating uncertain cases to an expensive oracle. Existing frameworks, however, require global dataset access and optimize a single quality metric, limiting their applicability in distributed systems where data is partitioned across independent workers. We present two adaptive cascade algorithms designed for streaming, per-partition execution in which each worker processes its partition independently without inter-worker communication. SUPG-IT extends the SUPG statistical framework to streaming execution with iterative threshold refinement and joint precision-recall guarantees. GAMCAL replaces user-specified quality targets with a learned calibration model: a Generalized Additive Model maps proxy scores to calibrated probabilities with uncertainty quantification, enabling direct optimization of a cost-quality tradeoff through a single parameter. Experiments on six datasets in a production semantic SQL engine show that both algorithms achieve F1 > 0.95 on every dataset. GAMCAL achieves higher F1 per oracle call at cost-sensitive operating points, while SUPG-IT reaches a higher quality ceiling with formal guarantees on precision and recall.
Cortex AISQL: A Production SQL Engine for Unstructured Data
Nov 19, 2025Snowflake's Cortex AISQL is a production SQL engine that integrates native semantic operations directly into SQL. This integration allows users to write declarative queries that combine relational operations with semantic reasoning, enabling them to query both structured and unstructured data effortlessly. However, making semantic operations efficient at production scale poses fundamental challenges. Semantic operations are more expensive than traditional SQL operations, possess distinct latency and throughput characteristics, and their cost and selectivity are unknown during query compilation. Furthermore, existing query engines are not designed to optimize semantic operations. The AISQL query execution engine addresses these challenges through three novel techniques informed by production deployment data from Snowflake customers. First, AI-aware query optimization treats AI inference cost as a first-class optimization objective, reasoning about large language model (LLM) cost directly during query planning to achieve 2-8$\times$ speedups. Second, adaptive model cascades reduce inference costs by routing most rows through a fast proxy model while escalating uncertain cases to a powerful oracle model, achieving 2-6$\times$ speedups while maintaining 90-95% of oracle model quality. Third, semantic join query rewriting lowers the quadratic time complexity of join operations to linear through reformulation as multi-label classification tasks, achieving 15-70$\times$ speedups with often improved prediction quality. AISQL is deployed in production at Snowflake, where it powers diverse customer workloads across analytics, search, and content understanding.
Fitting a deeply-nested hierarchical model to a large book review dataset using a moment-based estimator
Jun 01, 2018
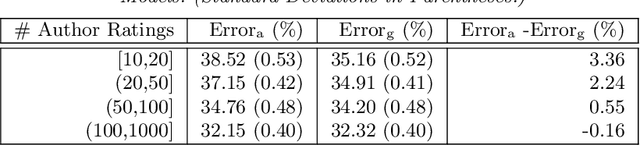
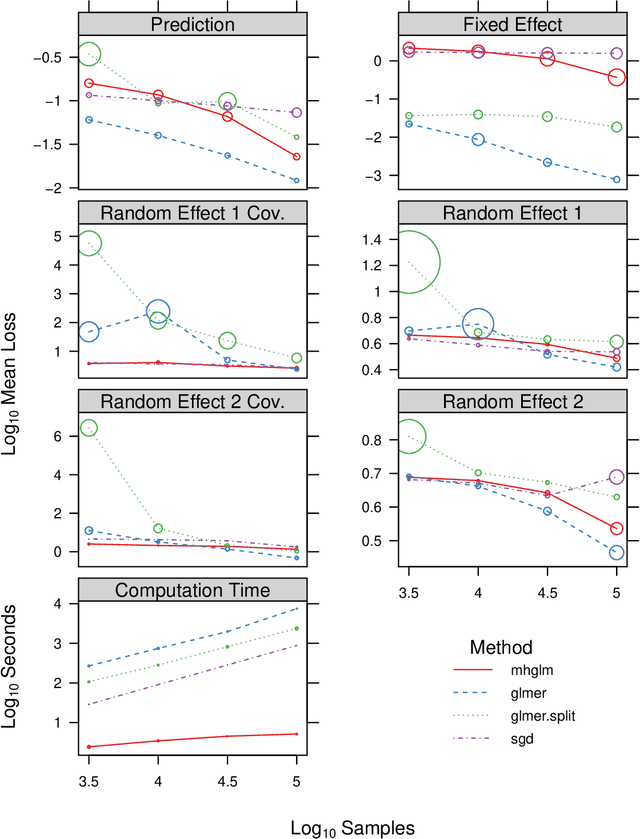
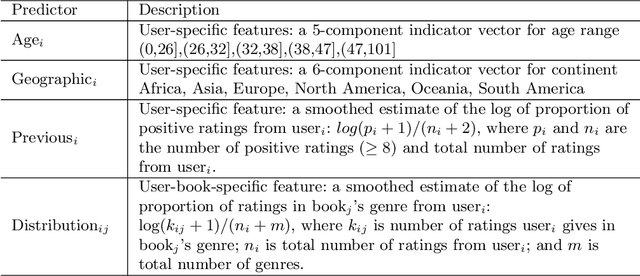
We consider a particular instance of a common problem in recommender systems: using a database of book reviews to inform user-targeted recommendations. In our dataset, books are categorized into genres and sub-genres. To exploit this nested taxonomy, we use a hierarchical model that enables information pooling across across similar items at many levels within the genre hierarchy. The main challenge in deploying this model is computational: the data sizes are large, and fitting the model at scale using off-the-shelf maximum likelihood procedures is prohibitive. To get around this computational bottleneck, we extend a moment-based fitting procedure proposed for fitting single-level hierarchical models to the general case of arbitrarily deep hierarchies. This extension is an order of magnetite faster than standard maximum likelihood procedures. The fitting method can be deployed beyond recommender systems to general contexts with deeply-nested hierarchical generalized linear mixed models.