 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedRep: Medical Concept Representation for General Electronic Health Record Foundation Models
Apr 11, 2025



Electronic health record (EHR) foundation models have been an area ripe for exploration with their improved performance in various medical tasks. Despite the rapid advances, there exists a fundamental limitation: Processing unseen medical codes out of the vocabulary. This problem limits the generality of EHR foundation models and the integration of models trained with different vocabularies. To deal with this problem, we propose MedRep for EHR foundation models based on the observational medical outcome partnership (OMOP) common data model (CDM), providing the integrated medical concept representations and the basic data augmentation strategy for patient trajectories. For concept representation learning, we enrich the information of each concept with a minimal definition through large language model (LLM) prompts and enhance the text-based representations through graph ontology of OMOP vocabulary. Trajectory augmentation randomly replaces selected concepts with other similar concepts that have closely related representations to let the model practice with the concepts out-of-vocabulary. Finally, we demonstrate that EHR foundation models trained with MedRep better maintain the prediction performance in external datasets. Our code implementation is publicly available at https://github.com/kicarussays/MedRep.
Review Learning: Alleviating Catastrophic Forgetting with Generative Replay without Generator
Oct 17, 2022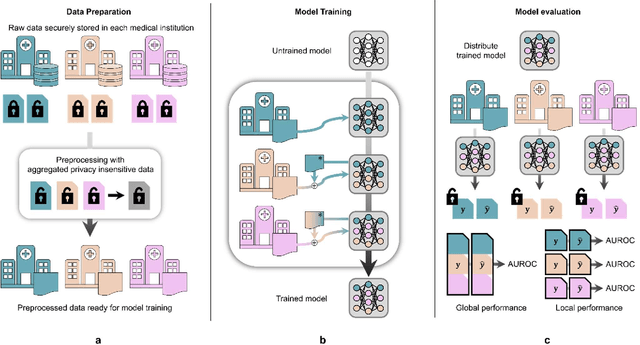
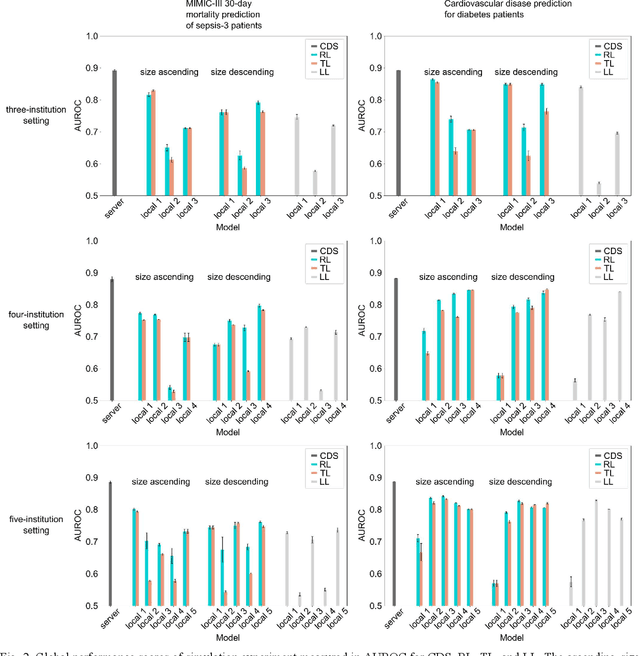
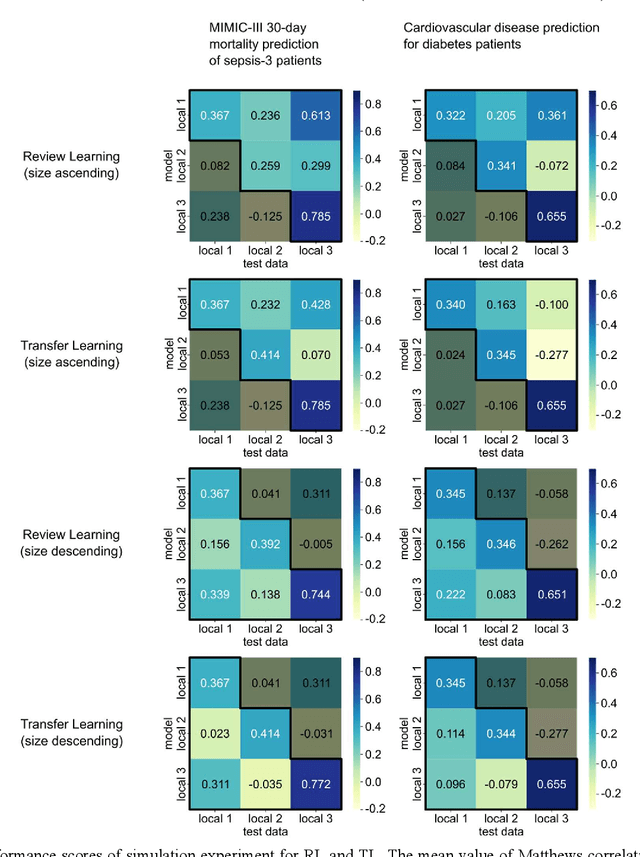
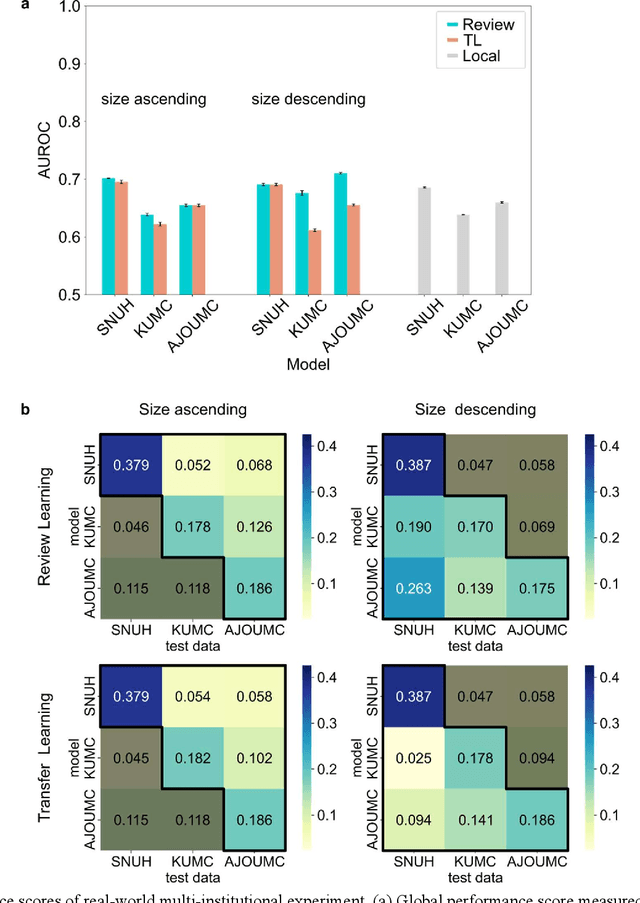
When a deep learning model is sequentially trained on different datasets, it forgets the knowledge acquired from previous data, a phenomenon known as catastrophic forgetting. It deteriorates performance of the deep learning model on diverse datasets, which is critical in privacy-preserving deep learning (PPDL) applications based on transfer learning (TL). To overcome this, we propose review learning (RL), a generative-replay-based continual learning technique that does not require a separate generator. Data samples are generated from the memory stored within the synaptic weights of the deep learning model which are used to review knowledge acquired from previous datasets. The performance of RL was validated through PPDL experiments. Simulations and real-world medical multi-institutional experiments were conducted using three types of binary classification electronic health record data. In the real-world experiments, the global area under the receiver operating curve was 0.710 for RL and 0.655 for TL. Thus, RL was highly effective in retaining previously learned knowledge.
Privacy-Preserving Deep Learning Computation for Geo-Distributed Medical Big-Data Platforms
Jan 09, 2020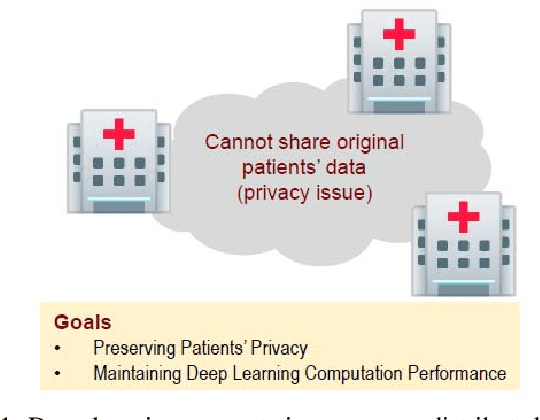
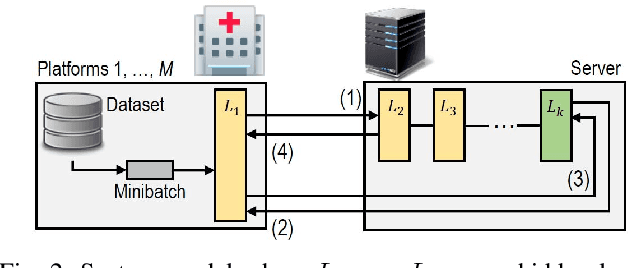
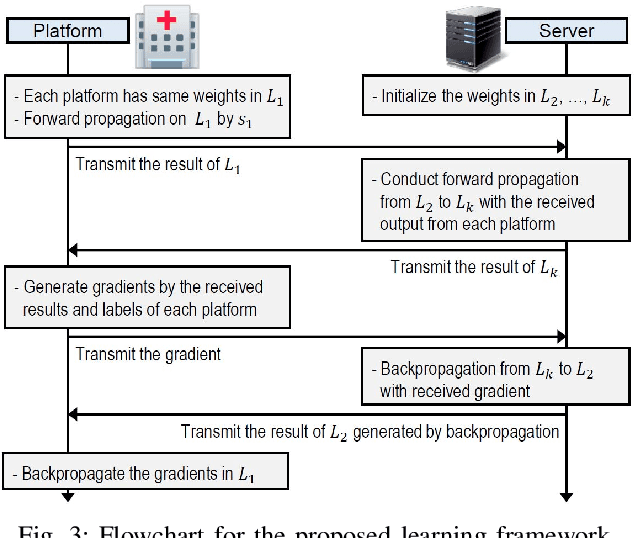
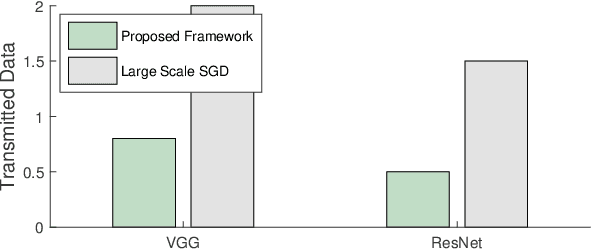
This paper proposes a distributed deep learning framework for privacy-preserving medical data training. In order to avoid patients' data leakage in medical platforms, the hidden layers in the deep learning framework are separated and where the first layer is kept in platform and others layers are kept in a centralized server. Whereas keeping the original patients' data in local platforms maintain their privacy, utilizing the server for subsequent layers improves learning performance by using all data from each platform during training.