 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Complexity in Part-of-Speech Induction
Jan 16, 2014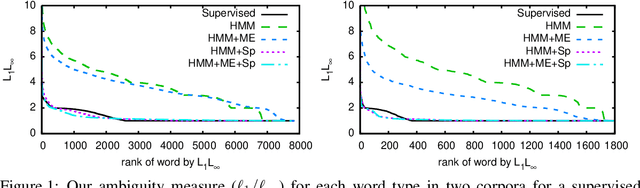
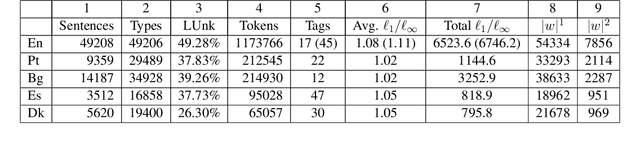
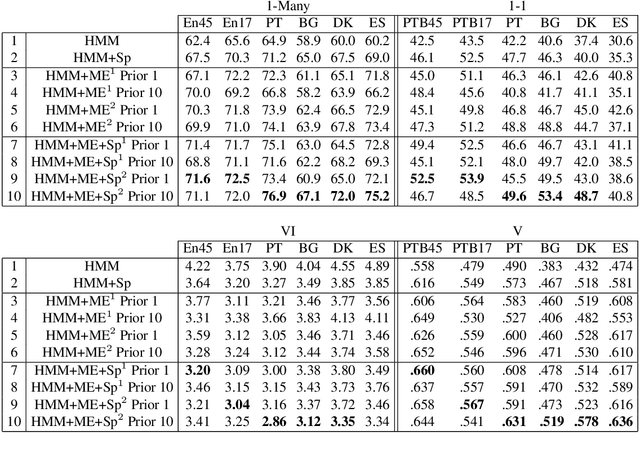
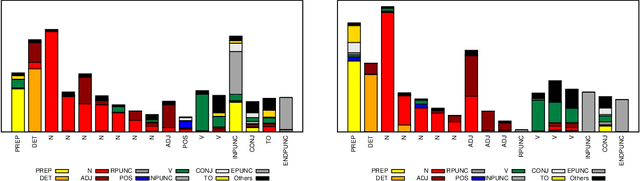
We consider the problem of fully unsupervised learning of grammatical (part-of-speech) categories from unlabeled text. The standard maximum-likelihood hidden Markov model for this task performs poorly, because of its weak inductive bias and large model capacity. We address this problem by refining the model and modifying the learning objective to control its capacity via para- metric and non-parametric constraints. Our approach enforces word-category association sparsity, adds morphological and orthographic features, and eliminates hard-to-estimate parameters for rare words. We develop an efficient learning algorithm that is not much more computationally intensive than standard training. We also provide an open-source implementation of the algorithm. Our experiments on five diverse languages (Bulgarian, Danish, English, Portuguese, Spanish) achieve significant improvements compared with previous methods for the same task.
Multi-View Learning over Structured and Non-Identical Outputs
Jun 13, 2012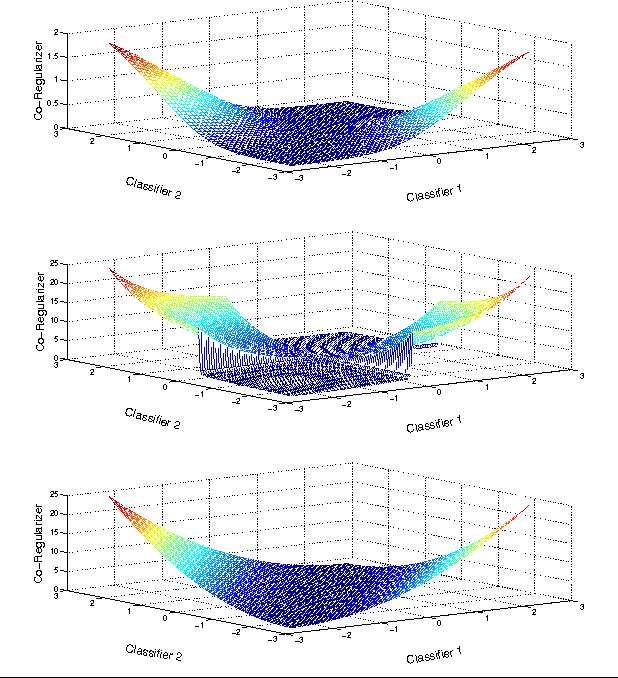
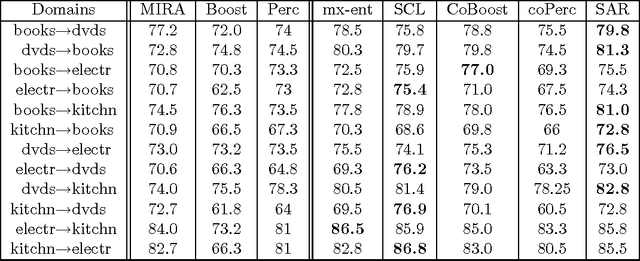
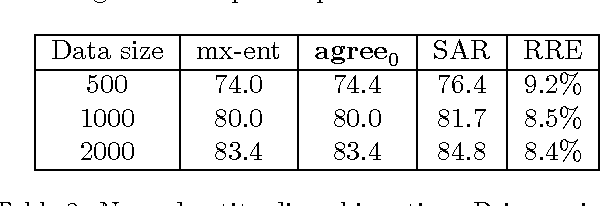
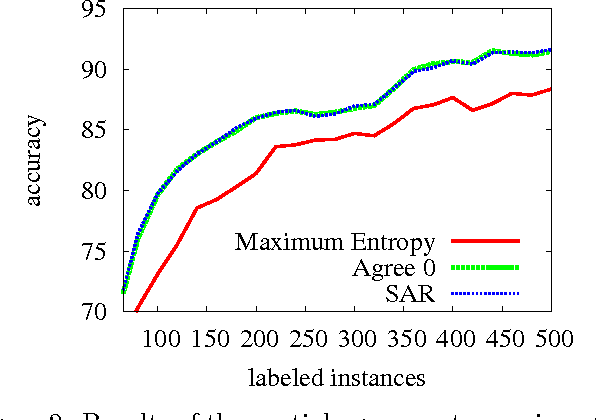
In many machine learning problems, labeled training data is limited but unlabeled data is ample. Some of these problems have instances that can be factored into multiple views, each of which is nearly sufficent in determining the correct labels. In this paper we present a new algorithm for probabilistic multi-view learning which uses the idea of stochastic agreement between views as regularization. Our algorithm works on structured and unstructured problems and easily generalizes to partial agreement scenarios. For the full agreement case, our algorithm minimizes the Bhattacharyya distance between the models of each view, and performs better than CoBoosting and two-view Perceptron on several flat and structured classification problems.
Censored Exploration and the Dark Pool Problem
May 09, 2012

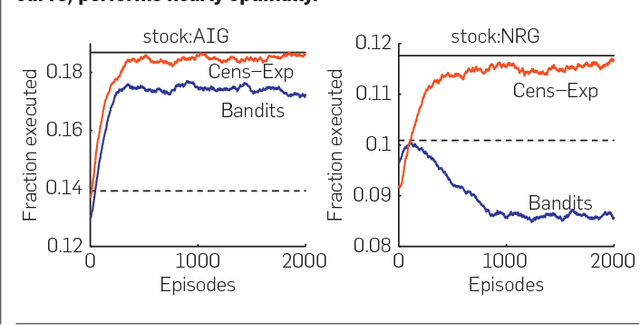
We introduce and analyze a natural algorithm for multi-venue exploration from censored data, which is motivated by the Dark Pool Problem of modern quantitative finance. We prove that our algorithm converges in polynomial time to a near-optimal allocation policy; prior results for similar problems in stochastic inventory control guaranteed only asymptotic convergence and examined variants in which each venue could be treated independently. Our analysis bears a strong resemblance to that of efficient exploration/ exploitation schemes in the reinforcement learning literature. We describe an extensive experimental evaluation of our algorithm on the Dark Pool Problem using real trading data.