 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKush R. Varshney
Proceedings of the 2017 ICML Workshop on Human Interpretability in Machine Learning (WHI 2017)
Aug 08, 2017
This is the Proceedings of the 2017 ICML Workshop on Human Interpretability in Machine Learning (WHI 2017), which was held in Sydney, Australia, August 10, 2017. Invited speakers were Tony Jebara, Pang Wei Koh, and David Sontag.
Optimized Data Pre-Processing for Discrimination Prevention
Apr 11, 2017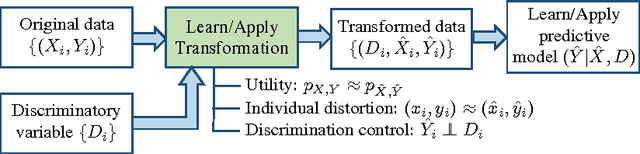

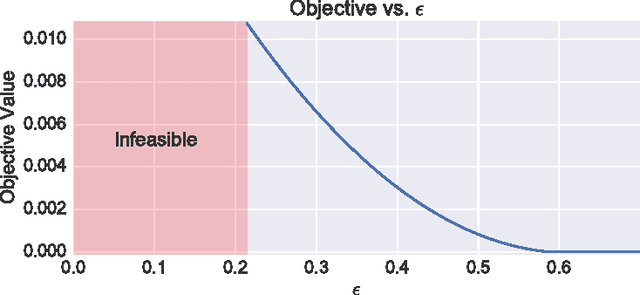
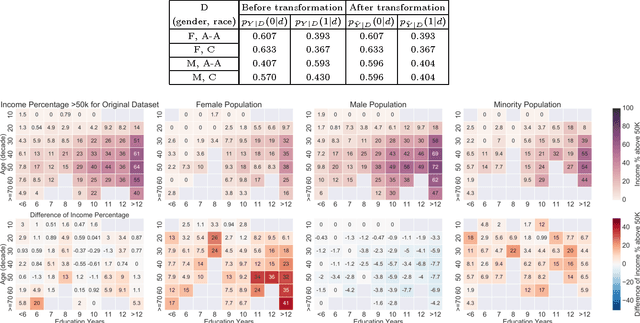
Non-discrimination is a recognized objective in algorithmic decision making. In this paper, we introduce a novel probabilistic formulation of data pre-processing for reducing discrimination. We propose a convex optimization for learning a data transformation with three goals: controlling discrimination, limiting distortion in individual data samples, and preserving utility. We characterize the impact of limited sample size in accomplishing this objective, and apply two instances of the proposed optimization to datasets, including one on real-world criminal recidivism. The results demonstrate that all three criteria can be simultaneously achieved and also reveal interesting patterns of bias in American society.
Proceedings of the 2016 ICML Workshop on #Data4Good: Machine Learning in Social Good Applications
Aug 28, 2016This is the Proceedings of the ICML Workshop on #Data4Good: Machine Learning in Social Good Applications, which was held on June 24, 2016 in New York.
Proceedings of the 2016 ICML Workshop on Human Interpretability in Machine Learning (WHI 2016)
Jul 27, 2016This is the Proceedings of the 2016 ICML Workshop on Human Interpretability in Machine Learning (WHI 2016), which was held in New York, NY, June 23, 2016. Invited speakers were Susan Athey, Rich Caruana, Jacob Feldman, Percy Liang, and Hanna Wallach.
Interpretable Two-level Boolean Rule Learning for Classification
Jun 18, 2016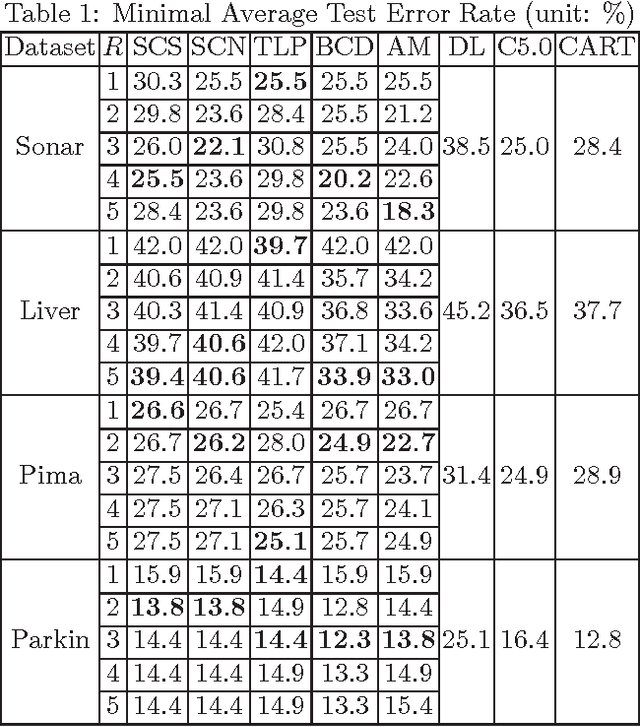
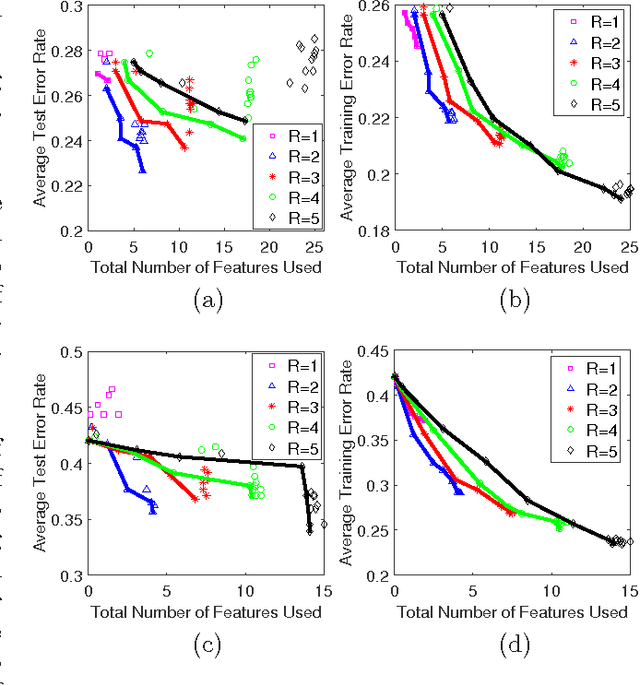
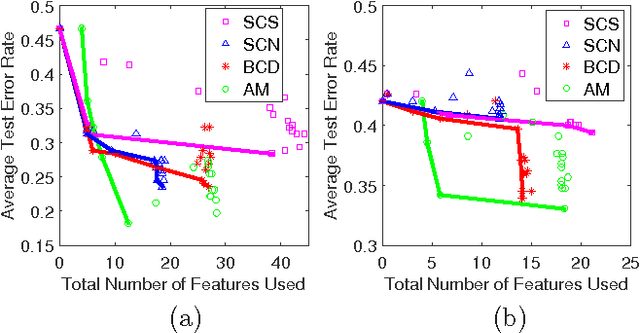
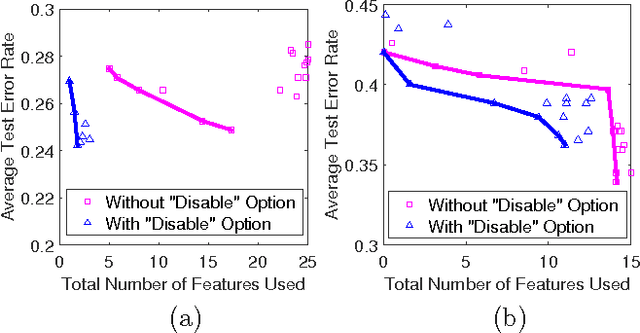
As a contribution to interpretable machine learning research, we develop a novel optimization framework for learning accurate and sparse two-level Boolean rules. We consider rules in both conjunctive normal form (AND-of-ORs) and disjunctive normal form (OR-of-ANDs). A principled objective function is proposed to trade classification accuracy and interpretability, where we use Hamming loss to characterize accuracy and sparsity to characterize interpretability. We propose efficient procedures to optimize these objectives based on linear programming (LP) relaxation, block coordinate descent, and alternating minimization. Experiments show that our new algorithms provide very good tradeoffs between accuracy and interpretability.
Understanding Innovation to Drive Sustainable Development
Jun 15, 2016


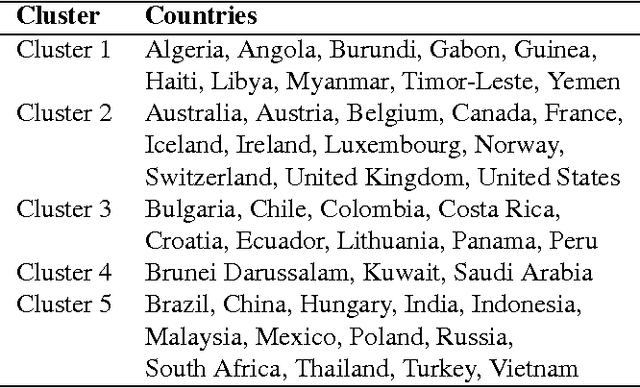
Innovation is among the key factors driving a country's economic and social growth. But what are the factors that make a country innovative? How do they differ across different parts of the world and different stages of development? In this work done in collaboration with the World Economic Forum (WEF), we analyze the scores obtained through executive opinion surveys that constitute the WEF's Global Competitiveness Index in conjunction with other country-level metrics and indicators to identify actionable levers of innovation. The findings can help country leaders and organizations shape the policies to drive developmental activities and increase the capacity of innovation.
Dynamic matrix factorization with social influence
Apr 21, 2016
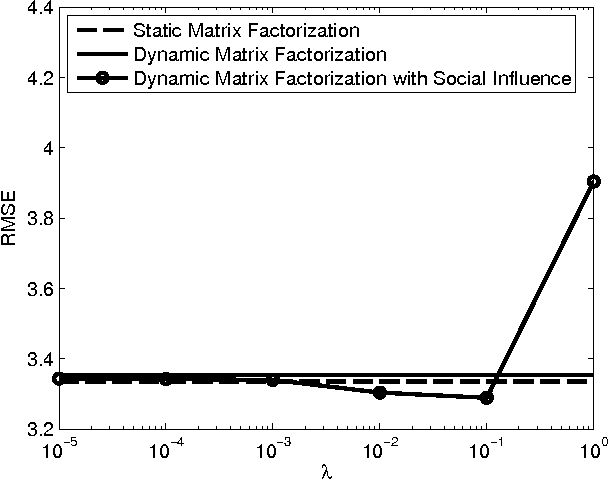
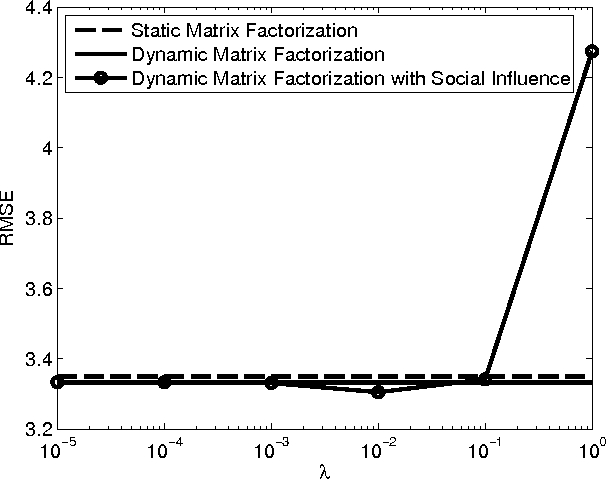
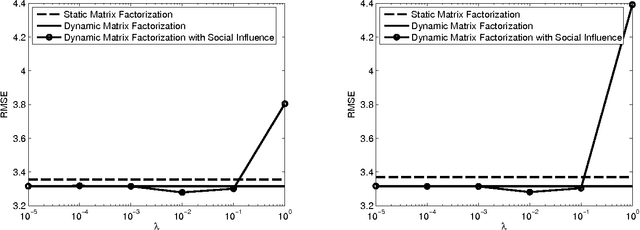
Matrix factorization is a key component of collaborative filtering-based recommendation systems because it allows us to complete sparse user-by-item ratings matrices under a low-rank assumption that encodes the belief that similar users give similar ratings and that similar items garner similar ratings. This paradigm has had immeasurable practical success, but it is not the complete story for understanding and inferring the preferences of people. First, peoples' preferences and their observable manifestations as ratings evolve over time along general patterns of trajectories. Second, an individual person's preferences evolve over time through influence of their social connections. In this paper, we develop a unified process model for both types of dynamics within a state space approach, together with an efficient optimization scheme for estimation within that model. The model combines elements from recent developments in dynamic matrix factorization, opinion dynamics and social learning, and trust-based recommendation. The estimation builds upon recent advances in numerical nonlinear optimization. Empirical results on a large-scale data set from the Epinions website demonstrate consistent reduction in root mean squared error by consideration of the two types of dynamics.
Engineering Safety in Machine Learning
Jan 16, 2016Machine learning algorithms are increasingly influencing our decisions and interacting with us in all parts of our daily lives. Therefore, just like for power plants, highways, and myriad other engineered sociotechnical systems, we must consider the safety of systems involving machine learning. In this paper, we first discuss the definition of safety in terms of risk, epistemic uncertainty, and the harm incurred by unwanted outcomes. Then we examine dimensions, such as the choice of cost function and the appropriateness of minimizing the empirical average training cost, along which certain real-world applications may not be completely amenable to the foundational principle of modern statistical machine learning: empirical risk minimization. In particular, we note an emerging dichotomy of applications: ones in which safety is important and risk minimization is not the complete story (we name these Type A applications), and ones in which safety is not so critical and risk minimization is sufficient (we name these Type B applications). Finally, we discuss how four different strategies for achieving safety in engineering (inherently safe design, safety reserves, safe fail, and procedural safeguards) can be mapped to the machine learning context through interpretability and causality of predictive models, objectives beyond expected prediction accuracy, human involvement for labeling difficult or rare examples, and user experience design of software.
A Big Data Approach to Computational Creativity
Nov 05, 2013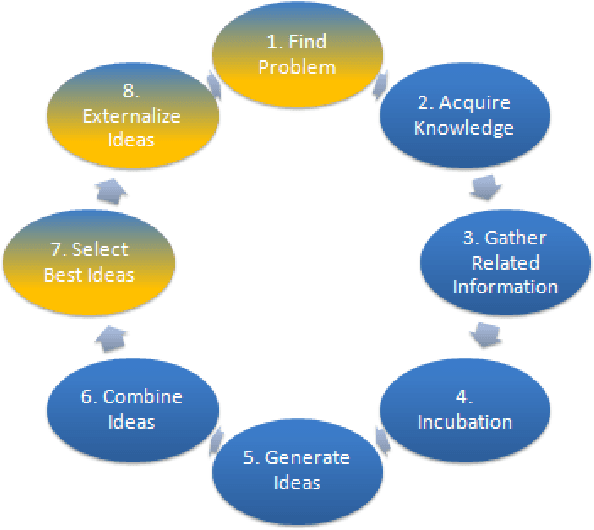
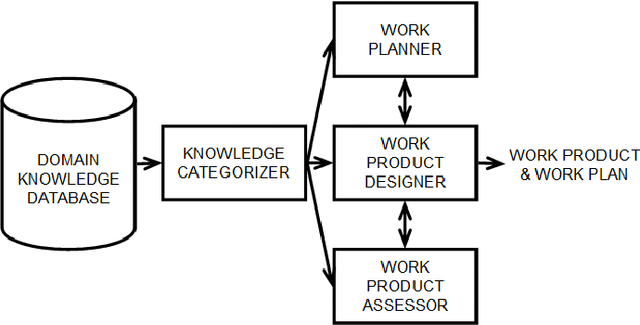
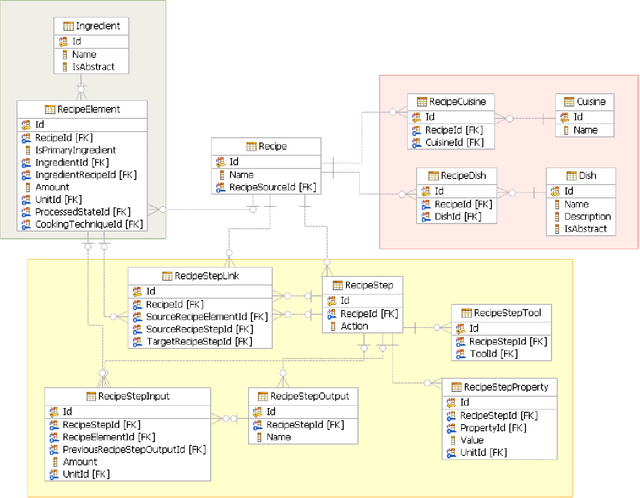
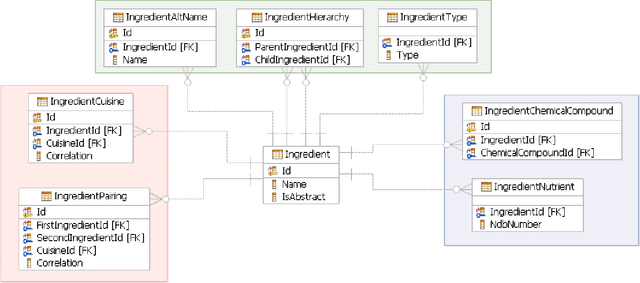
Computational creativity is an emerging branch of artificial intelligence that places computers in the center of the creative process. Broadly, creativity involves a generative step to produce many ideas and a selective step to determine the ones that are the best. Many previous attempts at computational creativity, however, have not been able to achieve a valid selective step. This work shows how bringing data sources from the creative domain and from hedonic psychophysics together with big data analytics techniques can overcome this shortcoming to yield a system that can produce novel and high-quality creative artifacts. Our data-driven approach is demonstrated through a computational creativity system for culinary recipes and menus we developed and deployed, which can operate either autonomously or semi-autonomously with human interaction. We also comment on the volume, velocity, variety, and veracity of data in computational creativity.