 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing edge AI models on HPC systems with the edge in the loop
May 26, 2025Artificial intelligence and machine learning models deployed on edge devices, e.g., for quality control in Additive Manufacturing (AM), are frequently small in size. Such models usually have to deliver highly accurate results within a short time frame. Methods that are commonly employed in literature start out with larger trained models and try to reduce their memory and latency footprint by structural pruning, knowledge distillation, or quantization. It is, however, also possible to leverage hardware-aware Neural Architecture Search (NAS), an approach that seeks to systematically explore the architecture space to find optimized configurations. In this study, a hardware-aware NAS workflow is introduced that couples an edge device located in Belgium with a powerful High-Performance Computing system in Germany, to train possible architecture candidates as fast as possible while performing real-time latency measurements on the target hardware. The approach is verified on a use case in the AM domain, based on the open RAISE-LPBF dataset, achieving ~8.8 times faster inference speed while simultaneously enhancing model quality by a factor of ~1.35, compared to a human-designed baseline.
kLog: A Language for Logical and Relational Learning with Kernels
Jul 28, 2014
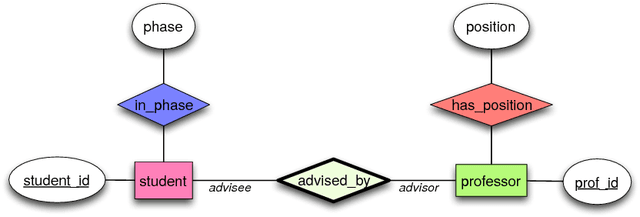
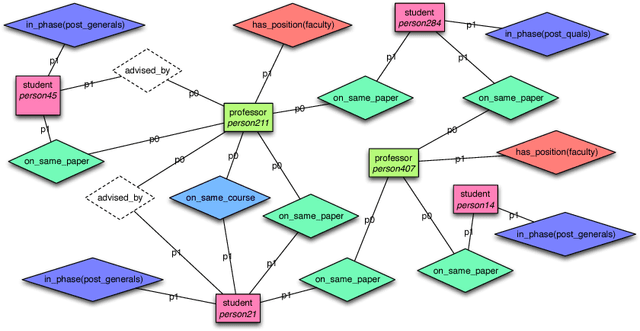

We introduce kLog, a novel approach to statistical relational learning. Unlike standard approaches, kLog does not represent a probability distribution directly. It is rather a language to perform kernel-based learning on expressive logical and relational representations. kLog allows users to specify learning problems declaratively. It builds on simple but powerful concepts: learning from interpretations, entity/relationship data modeling, logic programming, and deductive databases. Access by the kernel to the rich representation is mediated by a technique we call graphicalization: the relational representation is first transformed into a graph --- in particular, a grounded entity/relationship diagram. Subsequently, a choice of graph kernel defines the feature space. kLog supports mixed numerical and symbolic data, as well as background knowledge in the form of Prolog or Datalog programs as in inductive logic programming systems. The kLog framework can be applied to tackle the same range of tasks that has made statistical relational learning so popular, including classification, regression, multitask learning, and collective classification. We also report about empirical comparisons, showing that kLog can be either more accurate, or much faster at the same level of accuracy, than Tilde and Alchemy. kLog is GPLv3 licensed and is available at http://klog.dinfo.unifi.it along with tutorials.